
项目名称euler #22
项目名称euler #22
提问于 2018-06-22 07:07:12
欧拉计划22:姓名分数
使用names.txt (链接:names.txt),一个46K的文本文件,包含超过5000个名字,从按字母顺序排序开始。然后计算出每个名称的字母值,将该值乘以其在列表中的字母位置,以获得名称得分。例如,当列表按字母顺序排序时,COLIN (值为3 + 15 + 12 + 9 + 14 = 53 )是列表中的第938个名称。所以,科林会得到一个分数的938 × 53 = 49714。文件中所有的名字分数的总数是多少?
My输出:
811204450
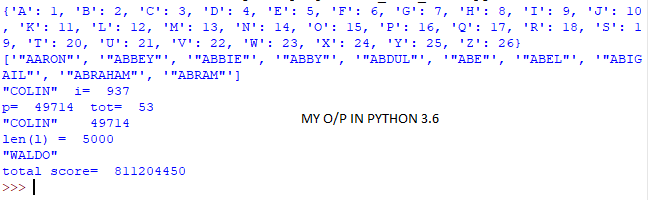
我不知道我错在哪里--我的答案是"COLIN“也是49714,而且名字也被正确地排序了。
我的代码:
d=dict()
j=1
for i in range(ord('A'),ord('Z')+1):
d[chr(i)]=j
j+=1
def main():
global d
print(d)
f=open("p022_names.txt","r")
t=f.read()
t=t.split(',')
t.sort() #THIS IS BUILT IN FN. SORT
print(t[0:10]) #CHECKING IF EVERYTHING IS SORTED
tot=0
l=[]
i=0
for i in range(5000): #THERE ARE 5000 NAMES
for s in t[i]:
if(s=='"'):
#print(s)
continue
else:
#print(s)
tot+=d[s]
p=(i+1)*tot
l.append(p)
if(t[i]=='"COLIN"'):
print(t[i]," i= ",i)
print("p= ",p," tot= ",tot)
print(t[i]," ",l[i])
tot=p=0
p=0
print("len(l) = ",len(l))
for i in range(len(l)):
p+=l[i]
print("total score= ",p)
main()回答 1
Stack Overflow用户
发布于 2018-06-22 07:40:18
来自https://projecteuler.net/problem=22
...a 46K文本文件,包含在上的5,000个名字.
如果你想检查一下的话,它是5163。只要改变:
for i in range(5000):至
for i in range(len(t)):还可以使用sum和生成器表达式缩短代码:
t = sorted(name.strip('"') for name in t)
result = sum(sum(ord(c)-64 for c in t[i]) * (i+1) for i in range(len(t)))页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/50982483
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号