
在云jupyter笔记本上上传csv文件时出错
我已经建立了一个google云帐户,我想在jupyter笔记本上更快地完成我的深入学习,但是我找不到一种方法来读取我从github帐户下载的csv文件,然后我尝试了。
dataset = pd.read_csv('/home/user/.jupyter/SIEMENSTRAIN.csv')
但是我得到了以下错误
pandas.parser.CParserError:错误标记数据。C错误:第3行中预期的2个字段,saw 12
为什么?当我用我的笔记本电脑读到它时,一切都很好。
有什么建议吗?
我尝试了这个错误的推荐解决方案,并得到了下一个警告。
/home/user/anaconda3/lib/python3.5/site-packages/ipykernel/main.py:1: ParserWarning:返回到'python‘引擎,因为'c’引擎不支持regex分隔符;您可以通过指定engine='python‘来避免这个警告。如果将 ==命名为“main”:
当我运行dataset.head()时,出现了这样的情况

有什么帮助吗?
回答 2
Stack Overflow用户
发布于 2018-06-13 20:26:28
有很多可能会导致这个问题..。我首先要确保Pandas (Pd)的版本是更新和兼容的。
更有可能的原因是CSV本身不正确,因此pd.read_csv()无法正确工作(因此出现了分析错误)。这可能与头文件有关,不过我不确定您的原始CSV文件是什么样子。例如,使用read_csv是值得的:
df = pandas.read_csv(fileName, sep='delimiter', header=None)这个篡改了两样东西-分隔符,如果pd是从CSV读取一个头是否。
我在我的书中浏览了一些关于股票预测(另一个很酷的机器学习问题)和深度学习的内容,可以随意查看。
祝好运!
Stack Overflow用户
发布于 2018-06-15 09:14:08
我尝试了你的建议,这就是我得到的
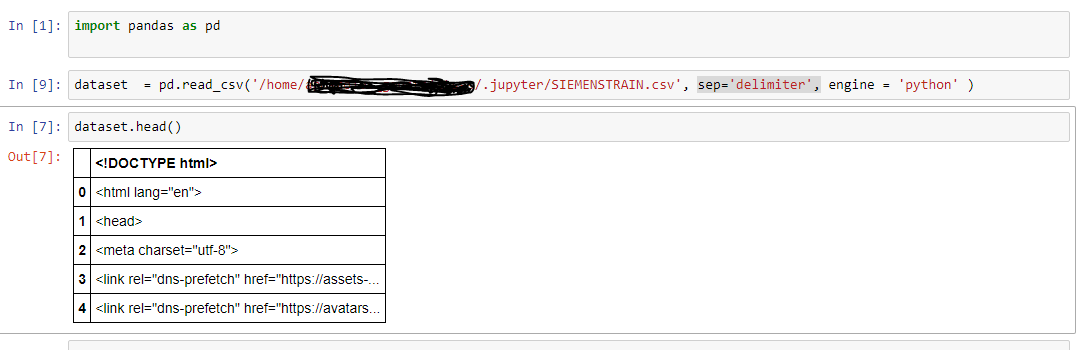
有什么建议吗?我想这条路是可以的,但是它不会被正确地阅读,或者我错了吗?
https://stackoverflow.com/questions/50818579
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号