
R dplyr group_by主题似乎使用了整个数据格式而不是主题。
R dplyr group_by主题似乎使用了整个数据格式而不是主题。
提问于 2018-06-12 00:30:48
背景我正在使用一个来自R的重复测量临床试验的大型数据集,在这里我想为每个主题做一些数据处理。这可以是为每个主题提取x列中的最大值,或为每个主题提取y列的平均值。
问题
我喜欢使用dplyr包和管道,这使我使用了group_by函数。但是当我尝试应用它时,我想要提取的数据似乎不是按主题分组,而是根据整个数据集提取数据。
码
这就是我到目前为止所做的:
data <- read.csv(file="group_by_question.csv", header=TRUE, sep=",")
library(dplyr)
library(plyr)
data <- tbl_df(data)
test <- data %>%
filter(!is.na(wght)) %>%
dplyr::group_by(subject_id) %>%
mutate(maxwght=max(wght),meanwght=mean(wght)) %>%
ungroup()测试数据的样本:
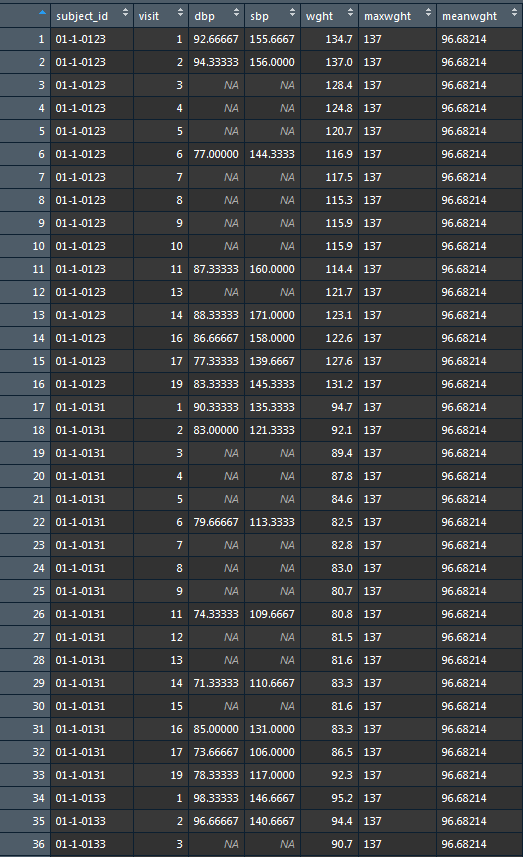
在这里找到我的数据集的.csv示例:https://drive.google.com/file/d/1wGkSQyJXqSswThiNsqC26qaP7d3catyX/view?usp=sharing
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-06-12 00:44:45
这是你想要的吗?在下面的示例中,输出按subject id显示maxwght列的最大值。例如,如果需要每个主题id的maxwght的平均值,则可以将max()替换为mean。
library(dplyr)
data <- read.csv(file="group_by_question.csv", header=TRUE, sep=",")
test <- data %>%
filter(!is.na(wght)) %>%
mutate(maxwght=max(wght),meanwght=mean(wght)) %>%
group_by(subject_id) %>%
summarise(value = max(maxwght)) %>%
ungroup()页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/50807745
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号