
TensorFlow是否使用GPU上的所有硬件?
NVidia GP100有30个TPC电路和240个“纹理单元”。TPC和纹理单元是由TensorFlow使用的,还是这些一次性的硅片用于机器学习?
我正在研究GPU和Windows 10内置的GPU性能监视器,在运行中的神经网络训练过程中,我看到各种硬件功能没有得到充分利用。Tensorflow使用CUDA。我想,库达可以访问所有的硬件组件。如果我知道差距在哪里(在Tensorflow和基础数据自动化系统之间),以及它是否是物质(浪费了多少硅),例如,我可以通过复制TensorFlow,修改它,然后提交一个拉请求来补救。
例如,下面的答案讨论从CUDA访问的纹理对象。NVidia注意到这些可以用于加速延迟敏感的、短运行的内核。如果我搜索"TextureObject tensorflow“,我就不会有任何点击。所以我可以假设,除非有相反的证据,TensorFlow没有利用TextureObjects。
NVidia销售用于神经网络训练的GPGPU。到目前为止,他们似乎已经对他们的电路采取了双重使用策略,所以他们留在了不用于机器学习的电路中。这就引出了纯TensorFlow电路是否会更有效的问题。因此,谷歌现在正在推广TPU。目前尚不清楚TPU对TensorFlow是否比NVidia GPU便宜。NVidia正在对谷歌的价格/性能声明提出质疑。
回答 1
Stack Overflow用户
发布于 2018-06-11 15:49:23
所有这些东西都不是可以在数据自动化系统中单独处理的单独硬件。请阅读您的文件第10页的这篇文章:
每台GP100内的GPC都有10条短信。每个SM有64个CUDA核心和4个纹理单元。有60个短消息,GP100共有3840个单精度CUDA核心和240个纹理单元。每个内存控制器附加到512 KB的L2缓存,每个HBM2 DRAM堆栈由一对内存控制器控制。整个GPU包括总共4096 KB的L2缓存。
如果我们在上面读到:
GP100是世界上性能最高的并行计算处理器,以满足由特斯拉P100加速器平台服务的GPU加速计算市场的需求。和以前的Tesla类GPU一样,GP100是由图形处理集群(GPC)、纹理处理集群(TPC)、流多处理器(SMs)和内存控制器组成的。一个完整的GP100由6个GPC、60个Pascal、30个TPC(每个包含两个SMs)和8个512位内存控制器(总计4096位)组成。
看一看图表,我们看到了以下情况:
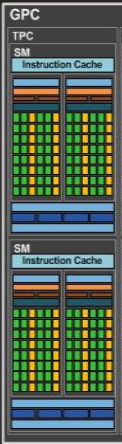
因此,不仅GPC和SMS没有分开硬件,甚至连TPC也只是另一种方式来重组硬件架构,并想出一个花哨的营销名称。您可以清楚地看到,TPC并没有在图表中添加任何新内容,它只是看起来像是SMs的容器。1 GPC5 TPCs10短消息
内存控制器是所有硬件为了与RAM接口而准备的,更多的内存控制器可以启用更高的带宽,参见下图:
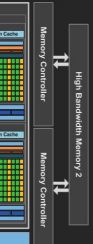
其中“高带宽内存”指的是HBM2 --一种类似于GDDR5的视频存储器,换句话说,就是指视频RAM。这并不是您在软件中直接使用CUDA解决的问题,就像您使用X86桌面计算机那样。
所以在现实中,我们这里只有SMs,而不是TPC和GPC。因此,为了回答您的问题,由于张量流利用了库达,大概它将使用它所能使用的所有可用硬件。
编辑:海报将他们的问题编辑成一个完全不同的问题,并且有新的误解,所以下面是答案:
纹理处理集群(TPC)和纹理单元不是一回事。TPC似乎仅仅是一个流媒体多处理器(SM)的组织,加入了一些营销魔术。
纹理单元不是一个具体的术语,不同的GPU和GPU都有不同的特性,但基本上可以把它们看作是纹理存储器或就绪访问纹理存储器的组合,它使用空间一致性,而不是L1、L2、L3。缓存,它使用时间一致性,结合一些固定的功能。固定功能可以包括插值访问滤波器(通常是线性插值)、不同的坐标模式、may控制和各向异性纹理滤波。请参阅本主题的Cuda 9.0指南,以获得纹理单元功能的概念,以及您可以通过CUDA控制什么。在图中,我们可以看到底部的纹理单位。
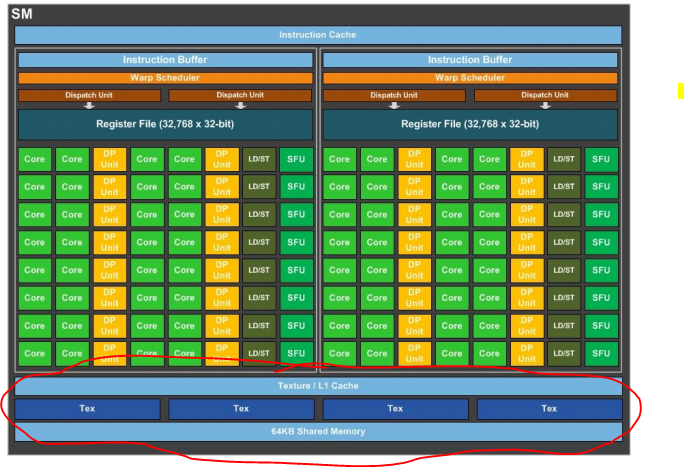
显然,它们与我发布的第一张图片中显示的TPC完全不同,至少根据图表,TPC没有与它们相关的额外功能,只是一个包含两个SMs的容器。
现在,尽管您可以在cuda中处理纹理功能,但您通常不需要这样做。纹理单元固定的功能对神经网络并不是那么有用,然而,即使你没有显式地尝试访问它,空间相干的纹理记忆通常也会被CUDA自动地用作优化。这样,TensorFlow仍然不会“浪费”硅。
https://stackoverflow.com/questions/50777871
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号