
是否有任何统计上合理的方法将网络中的中心分数转换为比率?
现在,我发现球员在各自的曲棍球队中处于中心地位。因为有些球员可能打60场比赛,而另一些人可能打20场比赛,所以打60场比赛的球员几乎总是(可以理解)具有较高的中间性。然而,我试图想出一种方法来规范游戏数量的中心性,这样我就可以比较不同玩家的影响,同时考虑他们玩的频率。
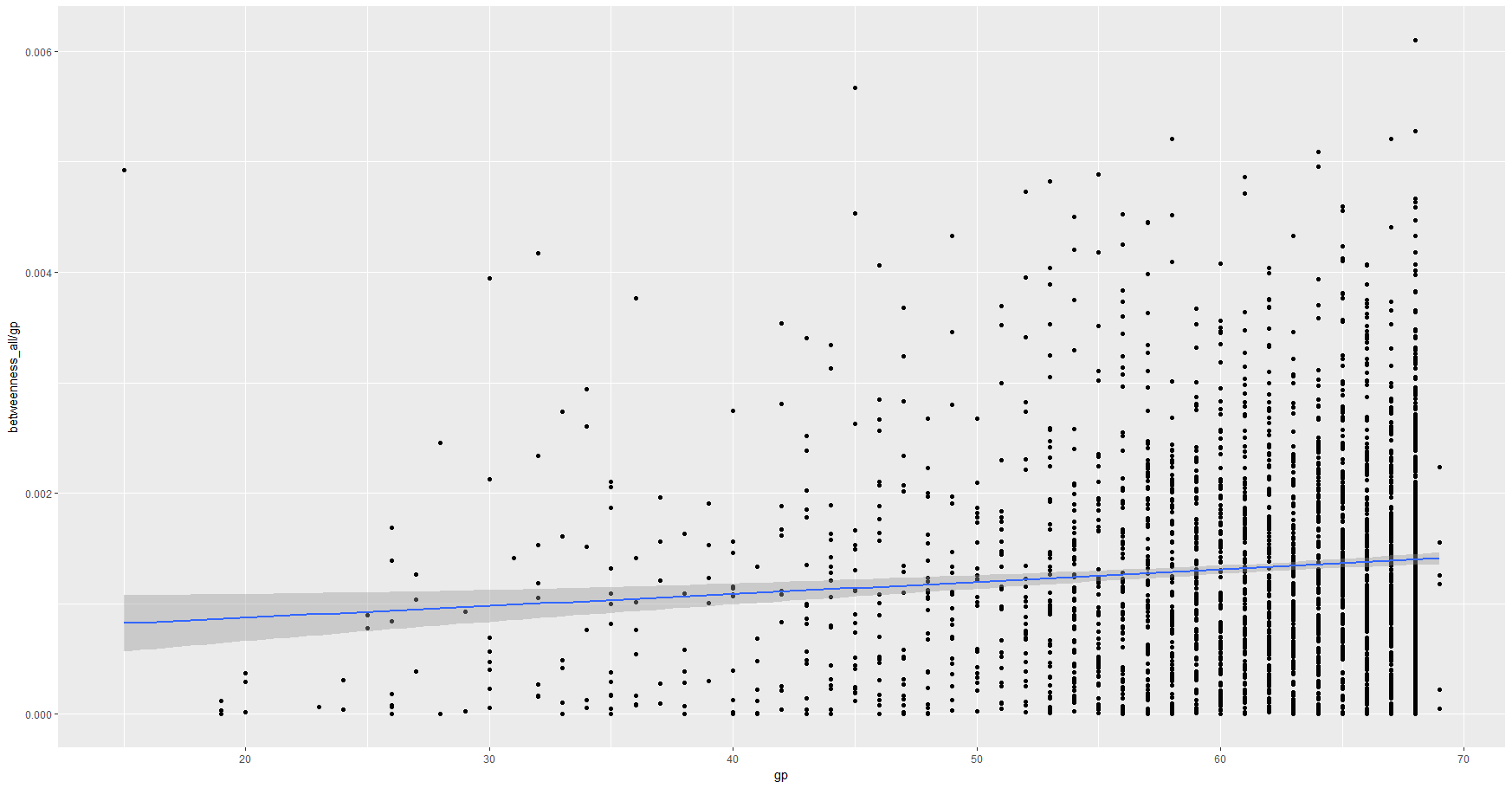
我试过用游戏来除法,但这仍然低估了玩更多游戏的附加效果(请看图表)。
第一个图表是游戏与累计(累积)之间的博弈。
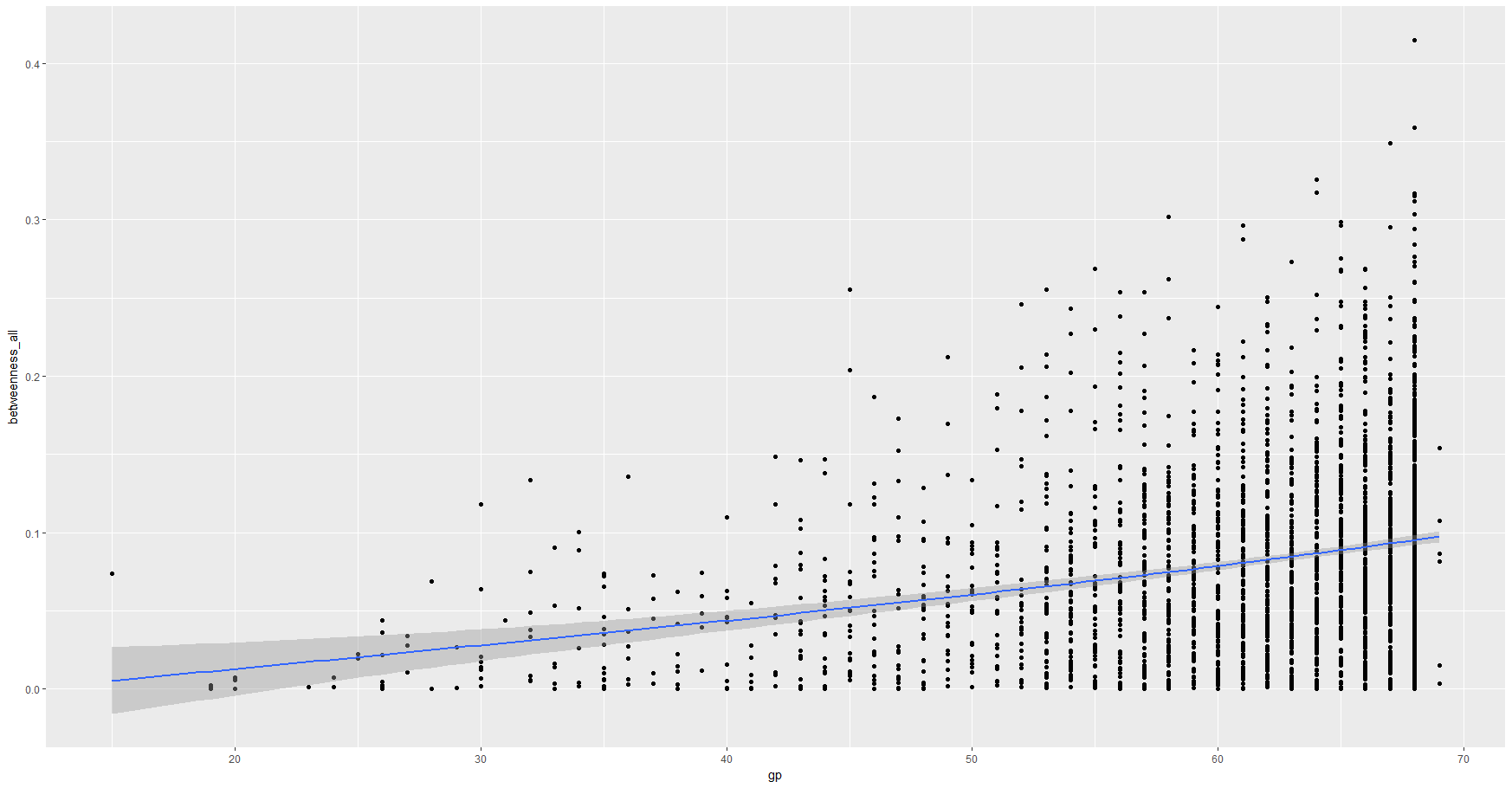
第二张图表是每场比赛的博弈与中间状态(仍然是一个正斜率)。
理想情况下,我不想在游戏和标准化的中心性之间建立联系,这样我就可以比较玩家,不管他们玩了多少场。知道我能做什么吗?
回答 1
Stack Overflow用户
发布于 2018-06-08 17:52:50
您不提供任何数据,所以我将使用内置数据集来帮助您。数据集是mtcars,假设cyl代表游戏的数量,disp代表中心性分数。
你可以看到这个情节中的关系
library(tidyverse)
# plot cyl against disp
mtcars %>%
ggplot(aes(cyl, disp))+
geom_point()+
geom_smooth(method = "lm")
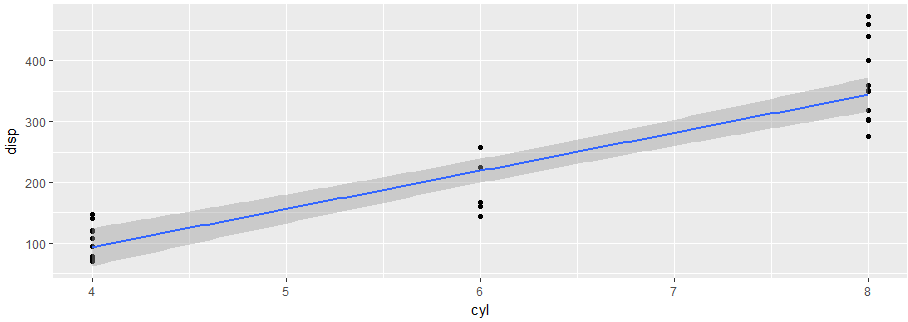
所玩的游戏(即cyl)与中心性分数(即disp)相关。
然后你就可以像这样创造新的分数
# build the model
m = lm(disp~cyl, data = mtcars)
# use model to get estimated disp at a given cyl value
mtcars$pred_disp = predict(m, newdata = mtcars)
# calculate the difference
mtcars$diff = mtcars$disp - mtcars$pred_disp画出新的分数,看它们与玩的游戏无关。
# plot cyl against diff
mtcars %>%
ggplot(aes(cyl, diff))+
geom_point()+
geom_smooth(method = "lm")
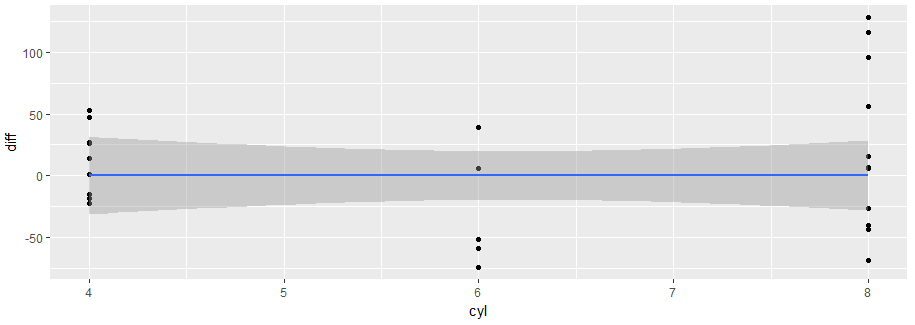
所玩的游戏(即cyl)与新的中心得分(即diff)无关。
另外,再次检查dataset mtcars,重点放在创建的新变量上。每个游戏值(即pred_disp)的预期中心性得分(即cyl)与预期值相同。新的中心性分数(即diff)是旧的中心性分数减去预期的中心分数。一个积极的新分数意味着球员的中心性比预期的中心位置要高。负数的新分数表示负值。
请注意,如果您愿意,可以对变量diff (例如,从-1到1的值)进行一些进一步的规范化。
https://stackoverflow.com/questions/50765723
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号