
Apache输出数据不一致?
使用nifi相当新。在设计上需要帮助。我试图在HDFS dir中使用虚拟csv文件创建一个简单的流,并为每个流文件中的每个记录添加一些文本数据。
传入文件:
dummy1.csv
dummy2.csv
dummy3.csv目录:
"Eldon Base for stackable storage shelf, platinum",Muhammed MacIntyre,3,-213.25,38.94,35,Nunavut,Storage & Organization,0.8
"1.7 Cubic Foot Compact ""Cube"" Office Refrigerators",BarryFrench,293,457.81,208.16,68.02,Nunavut,Appliances,0.58
"Cardinal Slant-D Ring Binder, Heavy Gauge Vinyl",Barry French,293,46.71,8.69,2.99,Nunavut,Binders and Binder Accessories,0.39
...期望输出:
d17a3259-0718-4c7b-bee8-924266aebcc7,Mon Jun 04 16:36:56 EDT 2018,Fellowes Recycled Storage Drawers,Allen Rosenblatt,11137,395.12,111.03,8.64,Northwest Territories,Storage & Organization,0.78
25f17667-9216-4f1d-b69c-23403cd13464,Mon Jun 04 16:36:56 EDT 2018,Satellite Sectional Post Binders,Barry Weirich,11202,79.59,43.41,2.99,Northwest Territories,Binders and Binder Accessories,0.39
ce0b569f-5d93-4a54-b55e-09c18705f973,Mon Jun 04 16:36:56 EDT 2018,Deflect-o DuraMat Antistatic Studded Beveled Mat for Medium Pile Carpeting,Doug Bickford,11456,399.37,105.34,24.49,Northwest Territories,Office Furnishings,0.61the flow
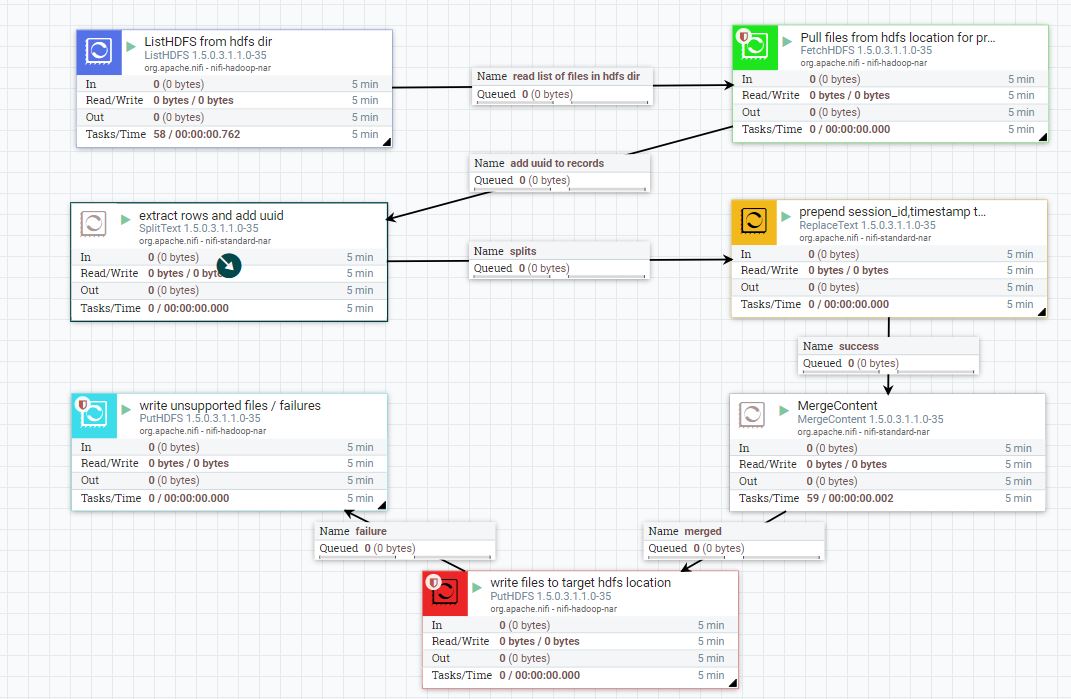
分裂文本-
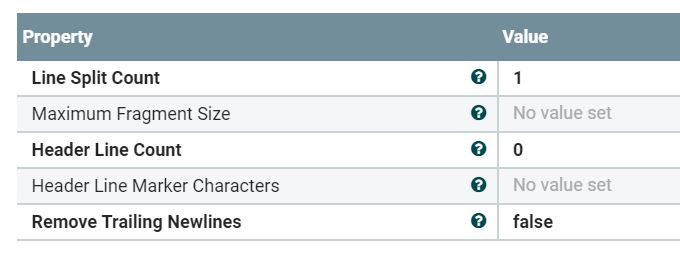
ReplaceText

MergeContent-
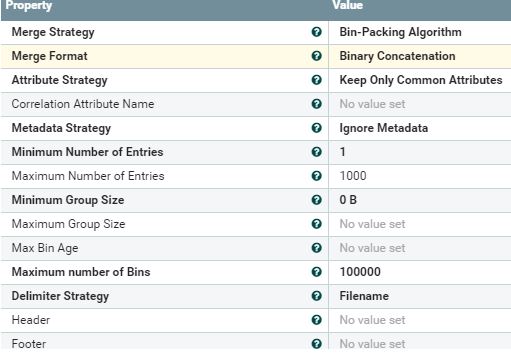
(这可能是实现我正在尝试获得的目标的糟糕方法,但我在某个地方看到,在生成唯一会话id时,uuid是最好的选择。因此,考虑从输入的数据中提取每一行到流文件并生成uuid)
但是,正如你所看到的,数据的顺序是混乱的。前3行的输出不一样。但是,我使用的测试数据(50000项)似乎在其他行中有数据。多项测试显示,数据顺序通常在2001行之后发生变化。
是的,我确实在这里搜索过类似的问题,并尝试在合并中使用碎片整理方法,但是它不起作用。如果有人能解释这里正在发生的事情,以及如何使用唯一的session_id (每个记录的时间戳)以同样的方式获取数据,我将不胜感激。有什么参数我需要修改或修改才能得到正确的输出吗?如果有更好的方法,我愿意接受建议。
回答 1
Stack Overflow用户
发布于 2018-06-05 17:41:01
首先,感谢您如此详尽和详细的答复。我想你消除了我对处理器工作方式的许多疑虑!
只有在碎片模式下才能保证合并的顺序,因为它将根据流文件的碎片索引进行排序。我不知道为什么这会不起作用,但是如果您能够用显示问题的示例数据创建一个流的模板,那么调试就会很有帮助。
我将再次尝试使用干净的模板复制此方法。可能是一些参数问题和HDFS编写器无法编写。
我不确定您的流程的目的是只是重新合并原来的CSV被分割,或合并在一起几个不同的CSV。碎片模式只会重新合并原来的CSV,所以如果ListHDFS选择了10个CSV,在拆分和重新合并之后,您应该再次拥有10个CSV。
是的,这正是我所需要的。将数据拆分并连接到相应的文件中。我不需要特别地(还)加入输出。
将CSV拆分为每流文件1行的方法是一种常见的方法,但是如果您有许多大型CSV文件,它的性能就不会很好。一种更有效的方法是使用,尝试在不分割的情况下对数据进行操作。这通常可以通过面向记录的处理器来完成。
- 我只是本能地使用了这种方法,并没有意识到这是一种常见的方法。有时,数据文件可能非常大,这意味着一个文件中有超过一百万条记录。这不是集群中i/o的问题吗?因为这意味着每个record=one flowfile=one都有唯一的uuid。nifi可以处理的合适数量的流文件是什么?(我知道这取决于集群配置,并将尝试从hdp管理获得更多有关集群的信息)
- “尝试在不分裂的情况下对数据进行操作”,你有什么建议?您能给出要使用的示例、模板或处理器吗?
在这种情况下,您需要为CSV定义一个模式,其中包括数据中的所有列,以及会话id和时间戳。然后使用UpdateRecord处理器,您将使用记录路径表达式,如/session_id = ${UUID()}和/timestamp = ${now()}。这将逐行地流内容,并更新每条记录并将其写回,并将其保存为一个流文件。
这看起来很有希望。您能共享一个从hdfs>processing>write hdfs文件中提取文件的简单模板吗?
由于限制,我不愿意分享模板。但是让我看看我是否能创建一个通用的templ,并且我将分享
谢谢你的智慧!)
https://stackoverflow.com/questions/50702622
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号