
R中显示意外行为的最小二乘方法的自制实现
我正在构建一个示例,以图形化的方式展示最小二乘法是如何工作的。我正在应用一种数值方法,给R一些可能的截距(a)和斜率(b)的组合,然后计算所有可能的组合的平方和(SSE)。与最低SSE相关联的a和b的组合应该是最好的组合,但与lm()计算的实际值相比,我对a的估计总是偏离标记。最重要的是,我对a的估计对给定的R的可能值范围很敏感--范围越宽,a的估计值就越远。
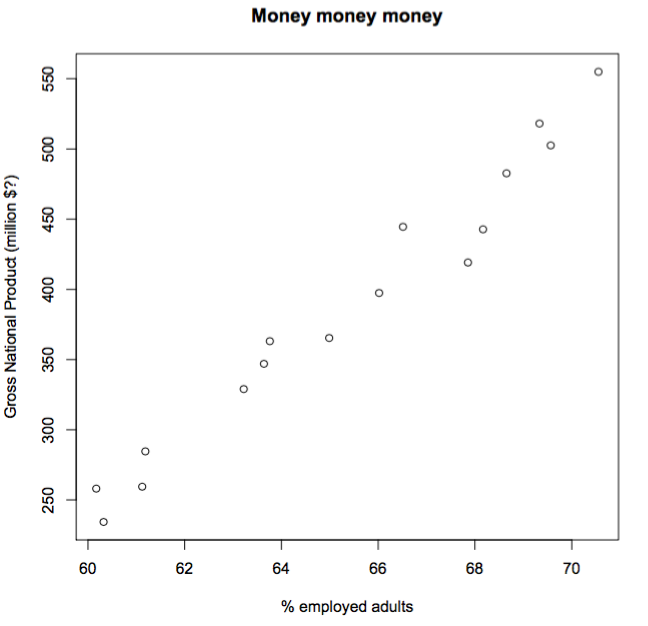
这是我的例子。我使用的数据集"longley",内置于R:
data(longley)
plot(GNP ~ Employed, data = longley,
xlab="% employed adults",
ylab="Gross National Product (million $?)",
main="Money money money"
)
# ranges of a and be where we think their true value lies:
possible.a.vals <- seq(-1431,-1430, by=0.01)
possible.b.vals <- seq(27,28.5, by=0.01)
# all possible combinations of a and b:
possible.ab <- expand.grid(possible.a.vals = possible.a.vals,
possible.b.vals = possible.b.vals
)
possible.ab.SSE <- as.data.frame(possible.ab)
head(possible.ab.SSE); tail(possible.ab.SSE)
possible.ab.SSE$SSE <- rep(NA, length.out = length(possible.ab.SSE[,1]))
for (i in 1:length(possible.ab.SSE[,1])){
predicted.GNP <- possible.ab.SSE$possible.a.vals[i] + possible.ab.SSE$possible.b.vals[i] * longley$Employed
possible.ab.SSE$SSE[i] <- sum((longley$GNP - predicted.GNP)^2)
}
possible.ab.SSE$possible.a.vals[which(possible.ab.SSE$SSE == min(possible.ab.SSE$SSE))]
possible.ab.SSE$possible.b.vals[which(possible.ab.SSE$SSE == min(possible.ab.SSE$SSE))]
# Estimate of a = -1430.73
# estimate of b = 27.84
# True values of a and b:
# a = -1430.48
# b = 27.84我对b的估计是即席的,但a略有出入。此外,扩大a和b的可能值范围会产生与实际值更远的a的估计值,给我一个大约1428年的估计值,并且使我的循环永远工作,如果我不是懒驴的话,我可以用apply()来解决这个问题。
# plot in 3d:
require(akima) # this helps interpolating the values of a,b, and SSE to create a surface
x= possible.ab.SSE$possible.a.vals
y= possible.ab.SSE$possible.b.vals
z=possible.ab.SSE$SSE
s=interp(x,y,z)
persp(x = s$x,
y = s$y,
z = s$z,
theta =50, phi = 10,
xlab="a", ylab="b", zlab="SSE",
box=T
)
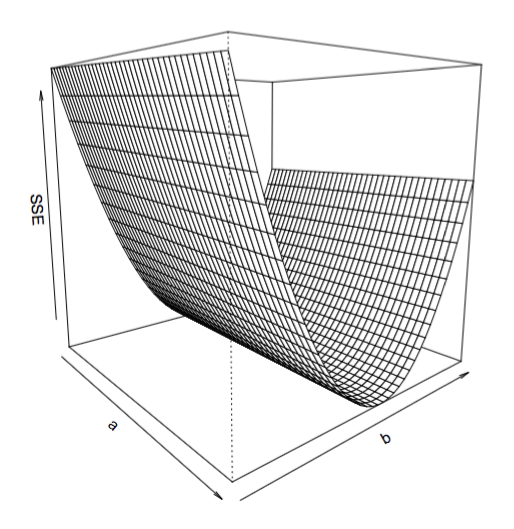
这表明,平方和与可能的a值之间的相关性大致是持平的,这就解释了为什么估计值往往偏离标号。这仍然让我感到困惑:如果最小二乘法的分析方法确定了参数值的估计,那么数值方法也应该如此。
不应该吗?
提前感谢您的反馈。
编辑
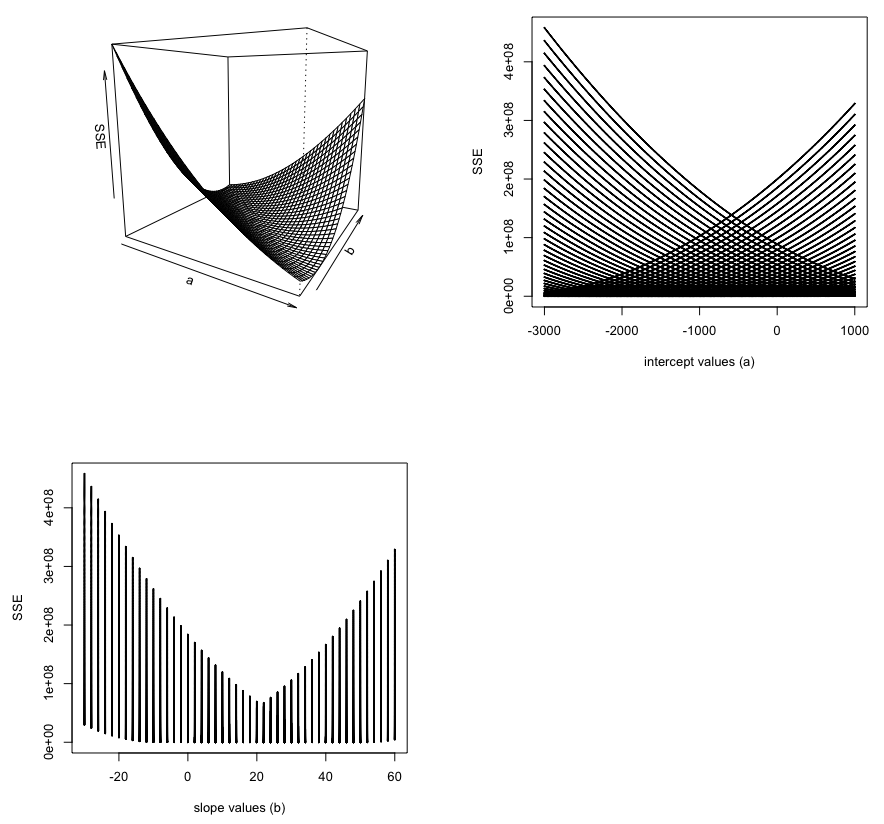
有人指出,这是一个解决问题的问题。我忽略了与a的每个值相关联的SSE的值并不独立于b;最重要的是,SSE的变化受b的变化的影响比受a中的变化的影响更大(或者至少这是我对它的理解)。结果表明,斜率b估计值的近似可以得到截距a的估计值。
以下三个图表显示了a、b和SSE之间对于范围更广、范围更稀疏的值的相关性:
possible.a.vals <- seq(-3000,1000, by=10)
possible.b.vals <- seq(-30,60, by=2)
回答 1
Stack Overflow用户
发布于 2018-05-24 13:38:39
@bolker是对的。说你的“对b的估计是对的”是不完全正确的。在您的示例27.84中最小化SSE的值与OLS估计( 27.83626 )之间的差异最终会对截获估计产生显著影响。
data(longley)
# ranges of a and be where we think their true value lies:
possible.a.vals <- seq(-1431,-1430, by = 0.005)
possible.b.vals <- seq(27.5,28, by = 0.00001)
# all possible combinations of a and b:
possible.ab.SSE <- expand.grid(possible.a.vals = possible.a.vals,
possible.b.vals = possible.b.vals)
possible.ab.SSE <- as.matrix(possible.ab.SSE)
out <- tcrossprod(cbind(1, longley$Employed), possible.ab.SSE)
possible.ab.SSE <- as.data.frame(possible.ab.SSE)
possible.ab.SSE$SSE <- colSums((out - longley$GNP)^2)
possible.ab.SSE[order(possible.ab.SSE$SSE), ][1, ]
# possible.a.vals possible.b.vals SSE
# 6758127 -1430.48 27.83622 4834.891
coef(lm(GNP ~ Employed, data = longley))
# (Intercept) Employed
# -1430.48231 27.83626 https://stackoverflow.com/questions/50508425
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号