
计数具有两个给定值对应于另一个变量的值的变量的出现情况
从图片中可以看到,我有一列有序号,一列有物质编号。
我想知道一对材料以同样的顺序出现的频率。
问题是,我有30000行订单号码和700个唯一的材料编号。有可能吗?
我在想,如果用列和行都有700个材料编号和计数数字来建立一个矩阵是否更容易。
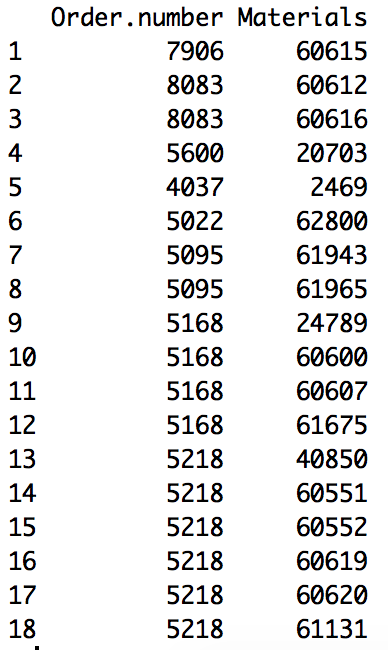
编辑:第一张照片不是一个很好的例子。我上传了第二张带有随机材质的照片。因此,我希望它对每对(如我突出显示的例子10-11 )计数,以相同的顺序出现多少次。可以看出,10和11以3种不同的顺序出现。

回答 2
Stack Overflow用户
发布于 2018-05-23 08:36:20
就内存空间而言,最优的解决方案是每对存储一行,即700*699 / 2。这个问题仍然相对较小,操作700*700矩阵的简单性可能比您正在保存的700*701/2单元更有价值,因为每个单元格的字节数为240 is。如果矩阵是稀疏的(即,大多数对材料从未排列在一起),并且使用适当的数据结构,则可能会更少。
下面是代码的样子:
首先,我们希望创建一个具有尽可能多的行和列的数据格式。矩阵更容易创建,因此我们创建一个矩阵,然后将其转换为dataframe。
all_materials = levels(as.factor(X$Materials))
number_materials = length(all_materials)
Pairs <- as.data.frame(matrix(data = 0, nrow = number_materials, ncol = number_materials))(在这里,X是您的数据集)
然后,我们将行名和列名设置为能够使用材料的标识符直接访问行和列,这些标识符显然不一定编号为1到700。
colnames(Pairs) <- all_materials
rownames(Pairs) <- all_materials然后我们迭代数据集。
for(order in levels(as.factor(X$Order.number))){
# getting the materials in each order
materials_for_order = X[X$Order.number==order, "Materials"]
if (length(materials_for_order)>1) {
# finding each possible pair from the materials list
all_pairs_in_order = combn(x=materials_for_order, m=2)
# incrementing the cell at the line and column corresponding to each pair
for(i in 1:ncol(all_pairs_in_order)){
Pairs[all_pairs_in_order[1, i], all_pairs_in_order[2, i]] = Pairs[all_pairs_in_order[1, i], all_pairs_in_order[2, i]] + 1
}
}
}在循环的末尾,Pairs表应该包含所需的一切。
Stack Overflow用户
发布于 2018-05-23 08:48:33
这里有一个data.table解决方案
library(data.table)
combis <- data.table(do.call(rbind,
DT[, if (.N > 1) list(combn(Materials, 2, simplify=FALSE)), by=Order.number]$V1
))
ans <- combis[, .N, by=.(V1, V2)]
#check results
setorder(ans, V1, V2)
ans和一个base方法:
allComb <- by(DT, DT$Order.number, function(x) {
if (nrow(x) > 1) {
return(combn(x$Materials, 2, simplify=FALSE)))
}
NULL
}
materialsPairs <- as.data.frame(do.call(rbind, unlist(allComb, recursive=FALSE)))
#https://stackoverflow.com/a/18201245/1989480
res <- aggregate(cnt ~ ., data=transform(materialsPairs, cnt=1), length)
#check results
head(res[order(res$V1, res$V2),])数据:
library(data.table)
set.seed(0L)
M <- 30e3
nOrd <- 3000
DT <- data.table(Order.number=sample(nOrd, M, replace=TRUE),
Materials=sample(700, M, replace=TRUE))
setorder(DT, Order.number, Materials)https://stackoverflow.com/questions/50482870
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号