
慢速循环python在python的数据帧中搜索数据
我有两个数据框架:一个是所有数据(称为“数据”),另一个是每个观测站开始和结束的纬度和经度(称为“信息”),我试图获得一个数据框架,在每个观测站旁边都有纬度和经度,这是我在python中的代码:
for i in range(0,15557580):
for j in range(0,542):
if data.year[i] == '2018' and data.station[i]==info.station[j]:
data.latitude[i] = info.latitude[j]
data.longitude[i] = info.longitude[j]
break但是,由于我有大约1500万的观察,做它,需要很多时间,有更快的方法吗?
非常感谢(我对此还不熟悉)
编辑:
我的文件信息看起来像这样(大约500个观察站,每个站一个)。
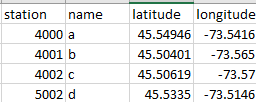
像这样的文件数据(这里没有显示其他变量)(大约1500万次观测,每次旅行一次)。
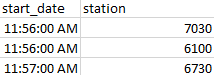
我想要得到的是,当站号匹配时,得到的数据如下所示:

回答 2
Stack Overflow用户
发布于 2018-05-21 23:44:40
这是一个解决办法。还可以使用pandas.merge向data添加2个新列并执行等效映射。
# create series mappings from info
s_lat = info.set_index('station')['latitude']
s_lon = info.set_index('station')['latitude']
# calculate Boolean mask on year
mask = data['year'] == '2018'
# apply mappings, if no map found use fillna to retrieve original data
data.loc[mask, 'latitude'] = data.loc[mask, 'station'].map(s_lat)\
.fillna(data.loc[mask, 'latitude'])
data.loc[mask, 'longitude'] = data.loc[mask, 'station'].map(s_lon)\
.fillna(data.loc[mask, 'longitude'])Stack Overflow用户
发布于 2018-05-21 23:47:19
当任何人开始处理大型数据集时,这是一个非常反复和重要的问题。大数据本身就是一个完整的主题,以下是对主要概念的简要介绍。
1.准备数据集
在大数据中,80%到90%的时间用于收集、过滤和准备数据集。创建数据子集,使其优化以供进一步处理。
2.优化脚本
短代码并不总是指性能方面的优化代码。在您的情况下,不知道您的数据集,很难确切地说您应该如何处理它,您将不得不自己想出如何在获得完全相同的结果的同时避免最大可能的计算。尽量避免任何不必要的计算。
如果适当,还可以考虑将工作拆分到多个线程上。
作为一般规则,您不应该在内部使用for循环并将它们放在break中。当您不知道首先需要经过多少个循环时,您应该始终使用while或do...while循环。
3.考虑使用分布式存储和计算
这本身就是一个太大的主题,无法在这里加以解释。
以序列化的方式存储、访问和处理数据对于少量的数据来说更快,但对于大型数据集则非常不合适。相反,我们使用分布式存储和计算框架。
它的目标是并行地做每件事。它依赖于一个名为MapReduce的概念。
第一个分布式数据存储框架是Hadoop (例如。Hadoop分布式文件系统( HDFS)。这个框架有其优点和缺陷,取决于您的应用程序。
在任何情况下,如果您愿意使用此框架,那么您可能更适合不直接在HDFS顶部使用MR,而是使用更高级别的MR,最好是内存中的MR,例如Spark或Apache在HDFS之上。另外,根据您的需要,尝试查看诸如Hive、Pig或Sqoop等框架。
同样,这个主题是一个完全不同的世界,但很可能很适合你的情况。可以自由地记录所有这些概念和框架,如果需要的话,可以将您的问题保留在评论中。
https://stackoverflow.com/questions/50457554
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号