
使用Google生态系统与构建您自己的微服务体系结构
在Google生态系统中构建是非常强大的。我非常喜欢您如何将文件摄取到Cloud,然后数据流丰富、转换和聚合数据,然后最终存储在BigQuery或Cloud中。
我有几个问题要帮助我更好地理解。如果您要使用Google服务构建一个大数据产品。
- 当前端web应用程序(可能是内置于React中)向云存储提交文件时,可能需要一段时间才能完全处理。客户端可能希望查看管道中文件的状态。然后,他们可能会想要做一些事情,结果在完成。前端客户端是如何知道文件何时已经完成、处理和准备的?他们需要从某个地方调查数据吗?
- 如果您目前有一个微服务体系结构,其中每个服务都执行不同类型的处理。例如,一个可能解析一个文件,另一个可能处理消息。服务使用Kafka或RabbitMQ进行通信,并将数据存储在Postgres或S3中。如果您采用Google服务生态系统,您能用云存储、数据流、Cloud /Store取代这个微服务体系结构吗?
回答 2
Stack Overflow用户
发布于 2018-05-11 21:58:55
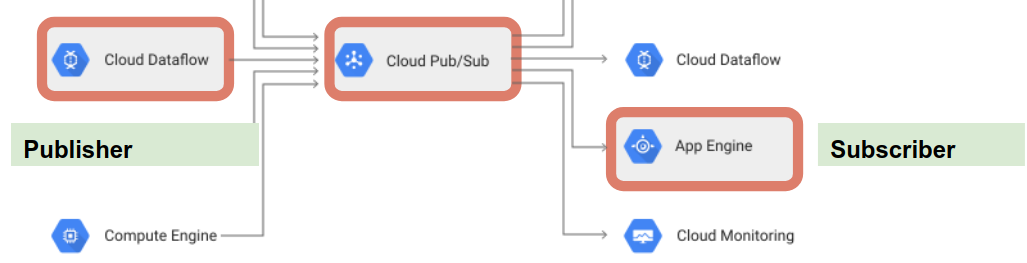
您看过云酒吧/分店 (主题订阅/发布服务)吗?
云Pub/Sub为云带来了面向企业消息的中间件的可扩展性、灵活性和可靠性。通过提供将发送者和接收者分离的多对多异步消息传递,它允许在独立编写的应用程序之间进行安全和高度可用的通信。
我相信Pub/Sub在你的情况下基本上可以替代卡夫卡或RabitMQ。
前端客户端是如何知道文件何时已经完成、处理和准备的?他们需要从某个地方调查数据吗?
例如,如果使用dataflow API处理文件,Cloud可以发布进度并将状态发送到主题。您的前端(应用程序引擎)只需订阅主题并接收更新。
Stack Overflow用户
发布于 2018-05-11 22:22:01
1) Dataflow不对中间结果进行检验。如果前端希望在Dataflow管道中处理元素的更多进展,则需要将自定义进度报告内置到Pipline中。
其中一个想法是将进度更新写入接收器表,并将分子输出到管道的各个部分。例如,有一个BigQuery接收器,您可以在其中编写"element_idX“、”阶段-1已完成“等行。然后,前端可以查询这些结果。(我会避免亲自覆盖旧行,但许多方法都可以工作)。
您可以通过在新接收器中使用PCollection和管道的下一步来实现这一点。
2)您的Microservice体系结构是否使用“管道和过滤器”管道风格的方法?也就是说,每个服务从一个源(Kafka/RabbitMQ)读取并写出数据,那么下一个服务会消耗它吗?
也许最好的方法是设置几个不同的数据流管道,并使用Pub/Sub或Kafka接收器输出结果,然后让下一个管道消耗Pub/Sub接收器。您还可能希望将它们放到另一个位置,如BigQuery/GCS,以便您可以在需要时再次查询这些结果。
还有一个选项是使用云函数而不是Dataflow,后者有Pub/Sub和GCS触发器。一个微服务系统可以设置多个云功能。
https://stackoverflow.com/questions/50284055
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号