
三层神经网络学习不正确
三层神经网络学习不正确
提问于 2018-05-10 18:39:25
所以,我试图实现一个在python中有3层的神经网络,但是我不是最聪明的人,所以任何超过2层的东西对我来说都有点困难。这个问题在于它被困在了.5上,我不知道它到底哪里出了问题。谢谢大家耐心地向我解释这个错误。(我希望这代码是有意义的)
import numpy as np
def sigmoid(x):
return 1/(1+np.exp(-x))
def reduce(x):
return x*(1-x)
l0=[np.array([1,1,0,0]),
np.array([1,0,1,0]),
np.array([1,1,1,0]),
np.array([0,1,0,1]),
np.array([0,0,1,0]),
]
output=[0,1,1,0,1]
syn0=np.random.random((4,4))
syn1=np.random.random((4,1))
for justanumber in range(1000):
for i in range(len(l0)):
l1=sigmoid(np.dot(l0[i],syn0))
l2=sigmoid(np.dot(l1,syn1))
l2_err=output[i]-l2
l2_delta=reduce(l2_err)
l1_err=syn1*l2_delta
l1_delta=reduce(l1_err)
syn1=syn1.T
syn1+=l0[i].T*l2_delta
syn1=syn1.T
syn0=syn0.T
syn0+=l0[i].T*l1_delta
syn0=syn0.T
print l2PS。我知道这可能是一堆垃圾剧本,但这也是我请求援助的原因
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-05-10 20:46:55
- 您的计算不完全正确。例如,
reduce在l1_err和l2_err上被调用,应该在l1和l2上调用它。 - 你正在执行随机梯度下降。在这种情况下,在如此少的参数,它的波动很大。在这种情况下,使用一个完整的批处理梯度下降。
- 偏置单元不存在。尽管你仍然可以在没有偏见的情况下学习,但技术上。
我试图用最小的更改重写您的代码。我已经评论了你的台词以显示变化。
#!/usr/bin/python3
import matplotlib.pyplot as plt
import numpy as np
def sigmoid(x):
return 1/(1+np.exp(-x))
def reduce(x):
return x*(1-x)
l0=np.array ([np.array([1,1,0,0]),
np.array([1,0,1,0]),
np.array([1,1,1,0]),
np.array([0,1,0,1]),
np.array([0,0,1,0]),
]);
output=np.array ([[0],[1],[1],[0],[1]]);
syn0=np.random.random((4,4))
syn1=np.random.random((4,1))
final_err = list ();
gamma = 0.05
maxiter = 100000
for justanumber in range(maxiter):
syn0_del = np.zeros_like (syn0);
syn1_del = np.zeros_like (syn1);
l2_err_sum = 0;
for i in range(len(l0)):
this_data = l0[i,np.newaxis];
l1=sigmoid(np.matmul(this_data,syn0))[:]
l2=sigmoid(np.matmul(l1,syn1))[:]
l2_err=(output[i,:]-l2[:])
#l2_delta=reduce(l2_err)
l2_delta=np.dot (reduce(l2), l2_err)
l1_err=np.dot (syn1, l2_delta)
#l1_delta=reduce(l1_err)
l1_delta=np.dot(reduce(l1), l1_err)
# Accumulate gradient for this point for layer 1
syn1_del += np.matmul(l2_delta, l1).T;
#syn1=syn1.T
#syn1+=l1.T*l2_delta
#syn1=syn1.T
# Accumulate gradient for this point for layer 0
syn0_del += np.matmul(l1_delta, this_data).T;
#syn0=syn0.T
#syn0-=l0[i,:].T*l1_delta
#syn0=syn0.T
# The error for this datpoint. Mean sum of squares
l2_err_sum += np.mean (l2_err ** 2);
l2_err_sum /= l0.shape[0]; # Mean sum of squares
syn0 += gamma * syn0_del;
syn1 += gamma * syn1_del;
print ("iter: ", justanumber, "error: ", l2_err_sum);
final_err.append (l2_err_sum);
# Predicting
l1=sigmoid(np.matmul(l0,syn0))[:]# 1 x d * d x 4 = 1 x 4;
l2=sigmoid(np.matmul(l1,syn1))[:] # 1 x 4 * 4 x 1 = 1 x 1
print ("Predicted: \n", l2)
print ("Actual: \n", output)
plt.plot (np.array (final_err));
plt.show ();我得到的输出是:
Predicted:
[[0.05214011]
[0.97596354]
[0.97499515]
[0.03771324]
[0.97624119]]
Actual:
[[0]
[1]
[1]
[0]
[1]]因此,网络能够预测所有的玩具训练例子。(请注意,在实际数据中,您不希望最好地拟合数据,因为它会导致过度拟合)。请注意,您可能会得到一些不同的结果,因为权重初始化是不同的。此外,尝试初始化[-0.01, +0.01]之间的权重,作为经验规则,当您没有处理特定的问题,并且您具体知道初始化。
这是会聚图。
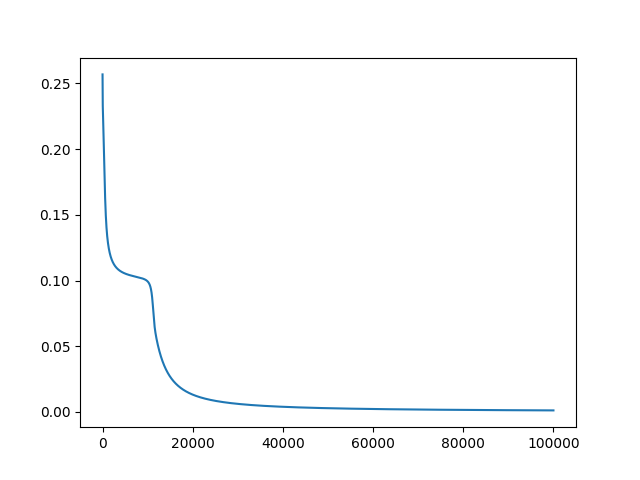
请注意,您不需要对每个示例进行实际迭代,而是可以同时进行矩阵乘法,这要快得多。另外,上面的代码不有偏置单位。当您重新实现代码时,请确保有偏置单元。
我建议您阅读劳尔罗哈斯的神经网络,系统介绍,第4、6和7章。第7章将告诉您如何以简单的方式实现更深层次的网络。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/50279477
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号