
Kotlin上界:‘:Any`’对Kotlin的泛型推理有什么区别?
Kotlin上界:‘:Any`’对Kotlin的泛型推理有什么区别?
提问于 2018-05-09 08:13:44
在Kotlin for Android Developers的书中,我们看到了扩展函数
fun <T:Any> SelectQueryBuilder.parseList(parser: (Map<String,Any?>) -> T):List<T> = parseList(object:MapRowParser<T>{
override fun parseRow(columns: Map<String, Any?>): T = parser(columns)
})我不知道为什么:Any是必要的。
如果我把它写成fun <T> SelectQueryBuilder.parseList(...),Android会抱怨
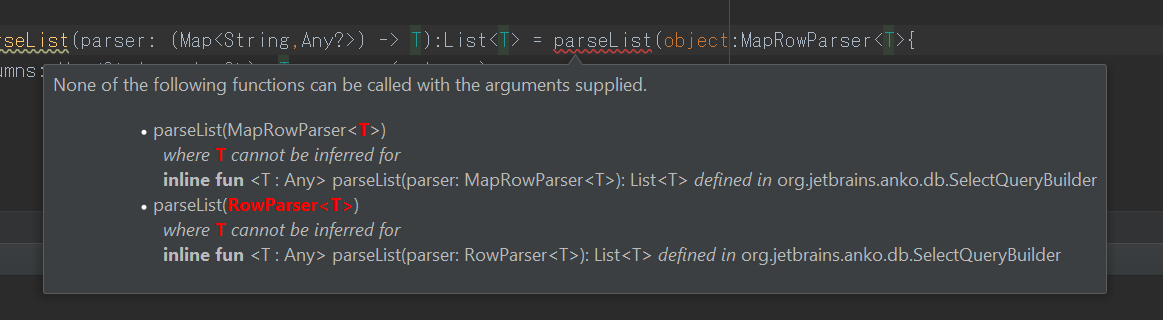
然而,当您将:Any添加回时,该错误就会消失。
现在,就我而言,T应该暗示T:Any,尽管情况显然不是这样的。为什么会这样呢?那又有什么区别呢?
回答 2
Stack Overflow用户
回答已采纳
发布于 2018-05-09 08:22:46
现在,就我而言,
T应该暗示T:Any
T意味着T:Any?,其中Any?最接近于Java的Object。使用T:Any,您指定了一个非空类型。
Stack Overflow用户
发布于 2018-05-09 08:33:23
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/50248546
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号