
在多索引dataframe中查找列的最大值并返回其所有值。
在多索引dataframe中查找列的最大值并返回其所有值。
提问于 2018-04-18 18:09:20
数据集的可复制代码:
df = {'player' : ['a','a','a','a','a','a','a','a','a','b','b','b','b','b','b','b','b','b','c','c','c','c','c','c','c','c','c'],
'week' : ['1','1','1','2','2','2','3','3','3','1','1','1','2','2','2','3','3','3','1','1','1','2','2','2','3','3','3'],
'category': ['RES','VIT','MATCH','RES','VIT','MATCH','RES','VIT','MATCH','RES','VIT','MATCH','RES','VIT','MATCH','RES','VIT','MATCH','RES','VIT','MATCH','RES','VIT','MATCH','RES','VIT','MATCH'],
'energy' : [75,54,87,65,24,82,65,42,35,25,45,87,98,54,82,75,54,87,65,24,82,65,42,35,25,45,98] }
df = pd.DataFrame(data= df)
df = df[['player', 'week', 'category','energy']]
我需要找到“每个球员,找到他的能量最大的一周,并显示所有类别,能量值的那一周”。
所以我做的是:
1.将球员和周设为索引
2.遍历索引,求出能量的最大值并返回其值。
df = df.set_index(['player', 'week'])
for index, row in df1.iterrows():
group = df1.ix[df1['energy'].idxmax()]获得的产出:
category energy
player week
b 2 RES 98
2 VIT 54
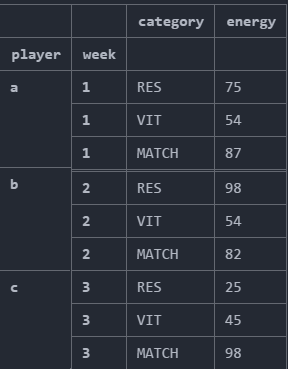
2 MATCH 82这个获得的输出是整个数据集中的最大能量,我希望每个玩家的最大能量与所有其他类别和它的能量为那一周。
预期产出:
我试过像评论中建议的那样使用groupby方法,
df.groupby(['player','week'])['energy'].max().groupby(level=['player','week'])获得的产出如下:
energy category
player week
a 1 87 VIT
2 82 VIT
3 65 VIT
b 1 87 VIT
2 98 VIT
3 87 VIT
c 1 82 VIT
2 65 VIT
3 98 VIT回答 3
Stack Overflow用户
回答已采纳
发布于 2018-04-18 18:39:58
为每个玩家找到最大能量周,然后为该玩家选择那个星期,并将所有玩家的结果连在一起。
max_energy_idx = df.groupby('player')['energy'].idxmax() # 2, 12, 26
max_energy_weeks = df['week'].iloc[max_energy_idx] # '1', '2', '3'
players = sorted(df['player'].unique()) # 'a', 'b', 'c'
result = pd.concat(
[df.loc[(df['player'] == player) & (df['week'] == max_enery_week), :]
for player, max_enery_week in zip(players, max_energy_weeks)]
)
>>> result
player week category energy
0 a 1 RES 75
1 a 1 VIT 54
2 a 1 MATCH 87
12 b 2 RES 98
13 b 2 VIT 54
14 b 2 MATCH 82
24 c 3 RES 25
25 c 3 VIT 45
26 c 3 MATCH 98如果需要,可以对结果设置索引:
result = result.set_index(['player', 'week'])Stack Overflow用户
发布于 2018-04-18 19:12:33
使用您的df及其原始索引(即在设置多个索引之前),可以通过使用.merge执行内部连接,在一行中获得结果。
df.merge(df.loc[df.groupby('player').energy.idxmax(), ['player', 'week']])
# player week category energy
# 0 a 1 RES 75
# 1 a 1 VIT 54
# 2 a 1 MATCH 87
# 3 b 2 RES 98
# 4 b 2 VIT 54
# 5 b 2 MATCH 82
# 6 c 3 RES 25
# 7 c 3 VIT 45
# 8 c 3 MATCH 98Stack Overflow用户
发布于 2018-04-18 18:54:41
另一种解决办法是不附带条件的:
idx = df.groupby('player')['energy'].idxmax()
coord = df.iloc[idx]
coord
player week category energy
2 a 1 MATCH 87
12 b 2 RES 98
26 c 3 MATCH 98
df.set_index(['player', 'week']).loc[(df.iloc[idx].set_index(['player', 'week']).index)]
category energy
player week
a 1 RES 75
1 VIT 54
1 MATCH 87
b 2 RES 98
2 VIT 54
2 MATCH 82
c 3 RES 25
3 VIT 45
3 MATCH 98页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/49906335
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号