
如何优化LightFM的超参数?
如何优化LightFM的超参数?
提问于 2018-04-18 10:02:26
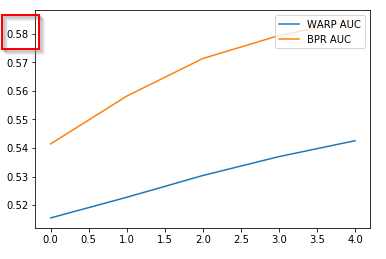
我正在我的数据集上使用LightFM推荐库,它给出了下面图像中的结果。
NUM_THREADS = 4
NUM_COMPONENTS = 30
NUM_EPOCHS = 5
ITEM_ALPHA = 1e-6
LEARNING_RATE = 0.005
LEARNING_SCHEDULE = 'adagrad'
RANDOM_SEED = 29031994
warp_model = LightFM(loss='warp',
learning_rate=LEARNING_RATE,
learning_schedule=LEARNING_SCHEDULE,
item_alpha=ITEM_ALPHA,
no_components=NUM_COMPONENTS,
random_state=RANDOM_SEED)
bpr_model = LightFM(loss='bpr',
learning_rate=LEARNING_RATE,
learning_schedule=LEARNING_SCHEDULE,
item_alpha=ITEM_ALPHA,
no_components=NUM_COMPONENTS,
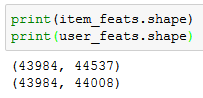
random_state=RANDOM_SEED)我的特征形状如下:
如何优化我的超参数以提高曲线下面积(AUC)分数?
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-04-23 14:31:37
您可以在滑雪博士中找到一个很好的超参数优化指南。
可以应用于优化LightFM模型的一种简单但有效的技术是随机搜索。大致由以下步骤组成:
- 将数据分成一个训练集、一个验证集和一个测试集。
- 为要优化的每个超参数定义一个分布。例如,如果您正在优化您的学习速率,您可以使用平均为0.05的指数分布;如果您正在优化损失函数,您可以从
['warp', 'bpr', 'warp-kos']中均匀抽样。 - 在优化的每一次迭代中,对所有的超参数进行采样,并使用它们来拟合训练数据上的模型。评估模型在验证集上的性能。
- 执行多个优化步骤后,选择具有最佳验证性能的步骤。
要评估最终模型的性能,应该使用测试集:简单地评估测试集上的最佳验证模型。
以下脚本说明了这一点:
import itertools
import numpy as np
from lightfm import LightFM
from lightfm.evaluation import auc_score
def sample_hyperparameters():
"""
Yield possible hyperparameter choices.
"""
while True:
yield {
"no_components": np.random.randint(16, 64),
"learning_schedule": np.random.choice(["adagrad", "adadelta"]),
"loss": np.random.choice(["bpr", "warp", "warp-kos"]),
"learning_rate": np.random.exponential(0.05),
"item_alpha": np.random.exponential(1e-8),
"user_alpha": np.random.exponential(1e-8),
"max_sampled": np.random.randint(5, 15),
"num_epochs": np.random.randint(5, 50),
}
def random_search(train, test, num_samples=10, num_threads=1):
"""
Sample random hyperparameters, fit a LightFM model, and evaluate it
on the test set.
Parameters
----------
train: np.float32 coo_matrix of shape [n_users, n_items]
Training data.
test: np.float32 coo_matrix of shape [n_users, n_items]
Test data.
num_samples: int, optional
Number of hyperparameter choices to evaluate.
Returns
-------
generator of (auc_score, hyperparameter dict, fitted model)
"""
for hyperparams in itertools.islice(sample_hyperparameters(), num_samples):
num_epochs = hyperparams.pop("num_epochs")
model = LightFM(**hyperparams)
model.fit(train, epochs=num_epochs, num_threads=num_threads)
score = auc_score(model, test, train_interactions=train, num_threads=num_threads).mean()
hyperparams["num_epochs"] = num_epochs
yield (score, hyperparams, model)
if __name__ == "__main__":
from lightfm.datasets import fetch_movielens
data = fetch_movielens()
train = data["train"]
test = data["test"]
(score, hyperparams, model) = max(random_search(train, test, num_threads=2), key=lambda x: x[0])
print("Best score {} at {}".format(score, hyperparams))页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/49896816
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号