
MDP迷宫策略图
MDP迷宫策略图
提问于 2018-04-17 13:37:38
我有一个5x-5迷宫,具体如下。
r = [1 0 1 1 1
1 1 1 0 1
0 1 0 0 1
1 1 1 0 1
1 0 1 0 1];其中1是路径,0是墙壁。
假设我有一个函数foo(policy_vector,r),它将策略向量的元素映射到r中的元素,例如1=UP、2=Right、3=Down、4=Left。MDP的设置使得墙状态永远不会实现,因此这些状态的策略在图中被忽略。
policy_vector' = [3 2 2 2 3 2 2 1 2 3 1 1 1 2 3 2 1 4 2 3 1 1 1 2 2]
symbols' = [v > > > v > > ^ > v ^ ^ ^ > v > ^ < > v ^ ^ ^ > >]我试图在解决迷宫的背景下,为马尔可夫决策过程展示我的决策。我要怎么设计出这样的东西呢?Matlab更好,但是Python很好。
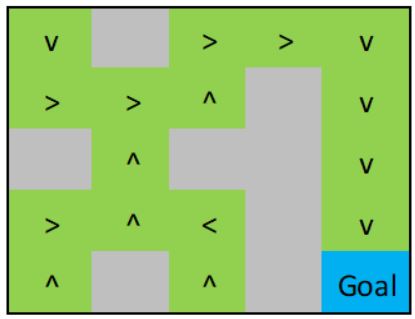
即使有人能告诉我如何制作这样的情节,我也能从中找到答案。

回答 1
Stack Overflow用户
回答已采纳
发布于 2018-04-25 16:21:31
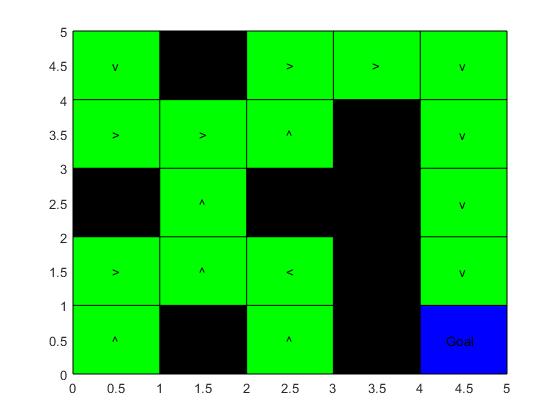
function[] = policy_plot(policy,r)
[row,col] = size(r);
symbols = {'^', '>', 'v', '<'};
policy_symbolic = get_policy_symbols(policy, symbols);
figure()
hold on
axis([0, row, 0, col])
grid on
cnt = 1;
fill([0,0,col,col],[row,0,0,row],'k')
for rr = row:-1:1
for cc = 1:col
if r(row+1 - rr,cc) ~= 0 && ~(row == row+1 - rr && col == cc)
fill([cc-1,cc-1,cc,cc],[rr,rr-1,rr-1,rr],'g')
text(cc - 0.55,rr - 0.5,policy_symbolic{cnt})
end
cnt = cnt + 1;
end
end
fill([cc-1,cc-1,cc,cc],[rr,rr-1,rr-1,rr],'b')
text(cc - 0.70,rr - 0.5,'Goal')
function [policy_symbolic] = get_policy_symbols(policy, symbols)
policy_symbolic = cell(size(policy));
for ii = 1:length(policy)
policy_symbolic{ii} = symbols{policy(ii)};
end页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/49879640
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号