
RL策略梯度:如何处理严格正面的奖励?
RL策略梯度:如何处理严格正面的奖励?
提问于 2018-04-13 17:16:55
简言之:
在策略梯度法中,如果奖励总是正数(从不为负),则策略梯度将始终为正,从而使我们的参数不断增大。这使得学习算法变得毫无意义。我们怎样才能解决这个问题?
详细情况:
在“大卫·西尔弗教授的RL课程”第7课(关于YouTube)中,他介绍了策略梯度的增强算法(这里只显示了一个步骤):

实际的政策更新是:
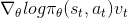
请注意,v_t在这里代表我们得到的奖励。假设我们在玩一个奖励总是积极的游戏。累积分数),没有任何负面的回报,梯度将永远是正的,因此θ将不断增加!那么,我们如何处理那些永不改变的奖励呢?
回答 1
Stack Overflow用户
发布于 2018-10-10 04:26:19
Theta不是一个数字,而是一个参数化模型的数字向量。与你的参数相关的梯度可能是正的,也可能是负的。例如,假设您的参数只是每个操作的概率。它们被限制添加到1.0中。增加一个动作的概率至少需要其他动作中的一个降低概率。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/49822158
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号