
并联回路性能退化
我目前正在为并行执行优化数据处理逻辑。我已经注意到,随着核心计数的增加--数据处理性能没有必要增加--我认为应该这样做。
下面是测试代码:
Console.WriteLine($"{DateTime.Now}: Data processing start");
double lastElapsedMs = 0;
for (int i = 1; i <= Environment.ProcessorCount; i++)
{
var watch = System.Diagnostics.Stopwatch.StartNew();
ProccessData(i); // main processing method
watch.Stop();
double elapsedMs = watch.ElapsedMilliseconds;
Console.WriteLine($"{DateTime.Now}: Core count: {i}, Elapsed: {elapsedMs}ms");
lastElapsedMs = elapsedMs;
}
Console.WriteLine($"{DateTime.Now}: Data processing end");和
public static void ProccessData(int coreCount)
{
// First part is data preparation.
// splitting 1 collection into smaller chunks, depending on core count
////////////////
// combinations = collection of data
var length = combinations.Length;
int chuncSize = length / coreCount;
int[][][] chunked = new int[coreCount][][];
for (int i = 0; i < coreCount; i++)
{
int skip = i * chuncSize;
int take = chuncSize;
int diff = (length - skip) - take;
if (diff < chuncSize)
{
take = take + diff;
}
var sub = combinations.Skip(skip).Take(take).ToArray();
chunked[i] = sub.ToArray();
}
// Second part is itteration. 1 chunk of data processed per core.
////////////////
Parallel.For(0, coreCount, new ParallelOptions() { MaxDegreeOfParallelism = coreCount }, (chunkIndex, state) =>
{
var chunk = chunked[chunkIndex];
int chunkLength = chunk.Length;
// itterate data inside chunk
for (int idx = 0; idx < chunkLength; idx++)
{
// additional processing logic here for single data
}
});
}结果如下:
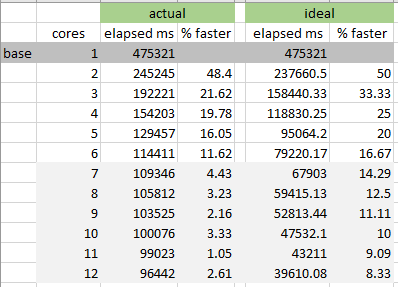
从结果集中可以看到--通过使用两个核而不是一个--您可以获得几乎理想的性能提高(考虑到一个核心在4700Mhz运行,而在每个4600Mhz上运行两个核心)。
在此之后,当数据应该在3个核上并行处理时,我预计与2个核心执行相比,性能会提高33%。实际增长21.62%。
接下来,随着核心计数的增加,“并行”执行性能的下降继续增加。
最后,当我们有12个核心结果时-- actual和ideal结果之间的差异是原来的两倍多(96442 as对39610 as)!
我当然没有预料到这种差别会如此之大。我有一个Intel 8700k处理器。6个物理核心和6个逻辑-总计12线程。1核心运行在4700 mode涡轮模式,2C 4600,3C 4500,4C 4400,5-6C 4400,6C 4300。
如果重要的话-我在Core-temp中做了额外的观察
- 当一个核心处理正在运行时??每6个核心中就有1个在忙着50%。
- 当两个核心处理在运行时??6个核心中有2个在忙50%。
- 当3个核心处理在运行时??6个核心中有3个在忙着50%。
- 当4个核心处理在运行时??6个核心中有4个在忙着50%。
- 当5芯处理正在运行时,6芯中有5芯忙碌50%。
- 当6个核心处理运行时??6个核心中有6个在忙50%。
- 当7芯加工运行时,6芯中有5芯忙碌50%,1芯100%繁忙。
- 当8芯加工运行时,6芯中有4芯忙碌50%,2芯100%繁忙。
- 当9芯加工运行时,6芯中有3芯忙碌50%,3芯100%繁忙。
- 当10芯加工运行时,6芯中有2芯忙碌50%,4芯100%繁忙。
- 当11芯处理运行时,6芯中有1/6占50%,5芯100%。
- 当12个核心处理在运行时??所有6个核都100%运行。
我可以肯定地看到,最终结果不应该像ideal结果那样表现,因为每个核的频率降低了,但是仍然..。有一个很好的解释为什么我的代码在12个核心上表现这么差吗?这是每台机器上的普遍情况,还是我的个人电脑的一个限制?
用于测试的.net核心2
编辑:对不起,忘记提到数据块可以优化,因为我已经将其作为草案解决方案进行了优化。然而,分裂是在1秒内完成的,因此在结果执行时间中增加了1000到2000‘s的最大值。
Edit2:,我刚刚去掉了所有的分块逻辑,并删除了MaxDegreeOfParallelism属性。数据按原样并行处理。现在的执行时间是94196ms,它与以前的时间基本相同,不包括块时间。.net似乎足够聪明,可以在运行时分块数据,所以不需要额外的代码,除非我想限制使用的核心数量。然而,事实是,这并没有显著提高业绩。我倾向于“Ahmdahl定律”的解释,因为我所做的一切都没有增加债券以外的错误幅度。
回答 2
Stack Overflow用户
发布于 2018-04-12 10:56:10
是啊,阿姆达尔定律。性能加速比从不与抛出问题的核数成线性关系。
还有往复..。
Stack Overflow用户
发布于 2018-04-12 11:20:01
正如nvoigt所指出的,分块代码运行在单个内核上,而且运行速度很慢。看看这两行:
var sub = combinations.Skip(skip).Take(take).ToArray();
chunked[i] = sub.ToArray();循环中的SkipTake是一个施莱米尔画家性能问题。使用不同的方法
sub已经是一个非常好的数组了,为什么要在下一行再复制一次呢?数组分配不是0成本。
我认为ArraySegment很适合解决这个问题,而不是制作数组副本。至少,您可以比当前所做的工作更有效地ToArray ArraySegment。
https://stackoverflow.com/questions/49794692
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号