
如何更改Glue Crawler创建的自动检测分区的列名?
我有水桶,这是用作移动消防软管流的目的地。
消防软管使用yyyy/mm/dd/HH格式自动在该桶上创建基于日期的前缀。
然后,我创建了一个爬虫,它将搜索到这个桶中的数据,并将其配置如下:
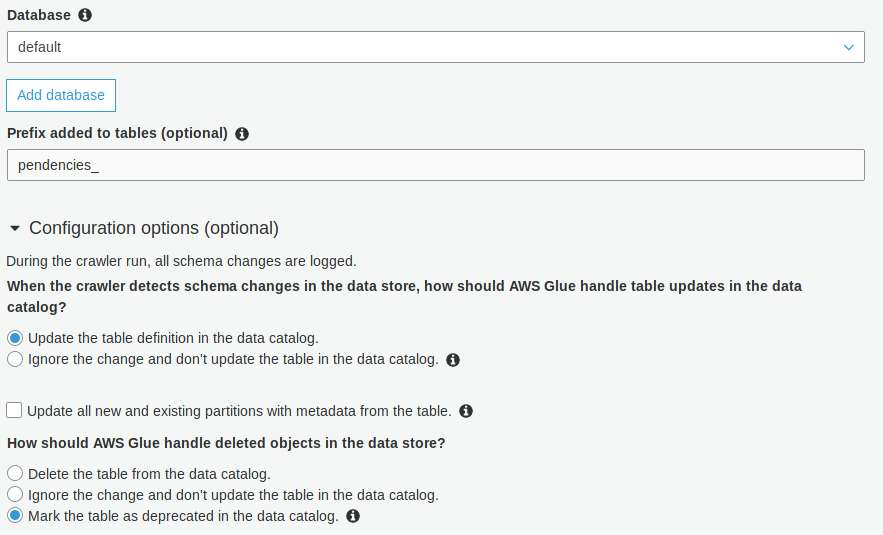
运行爬虫后,它将创建一个具有以下模式的表:
| # | Column name | Data type | Key |
| --- | ----------- | --------- | ------------- |
| 1 | numberissues | int | |
| 2 | group | string | |
| 3 | createdat | string | |
| 4 | companyunitid | string | |
| 5 | partition_0 | string | Partition (0) |
| 6 | partition_1 | string | Partition (1) |
| 7 | partition_2 | string | Partition (2) |
| 8 | partition_3 | string | Partition (3) |如果我将partition-*重命名为它们的右对应物year、month、day和hour,那么表就可以供我使用了。
但是,如果爬虫再次运行,架构会将列名显示给原始的partition-*。
我知道这适用于Hive分区模式year=2018/month=04...,但我想知道是否有可能“提示”有关分区字段名的Glue。
另一种选择是试图改变消防软管的前缀,但我找不到任何迹象表明这是可能的。
回答 2
Stack Overflow用户
发布于 2018-04-10 23:51:12
在这种情况下,您可以设置“忽略更改而不更新数据目录”选项。
然后可以重命名这些列。这将允许爬虫在下一次运行中检测新分区,但保留相应的名称。
Stack Overflow用户
发布于 2021-09-03 15:34:23
现在可以为火龙编写的S3前缀指定自定义格式。要遵循分区的Hive样式,可以在前缀中使用以下语法:
beginning_of_prefix/year=!{timestamp:yyyy}/month=!{timestamp:MM}/day=!{timestamp:dd}/hour=!{timestamp:HH}/示例输出:
beginning_of_prefix/year=2021/month=09/day=03/hour=16/这将使Glue爬虫能够识别分区的名称。
在更多细节中,引入的!{namespace:value}语法AWS允许访问Firehose用于分区的时间戳,并将其打印到前缀中。这是通过将timestamp指定为命名空间,并将有效的DateTimeFormatter字符串指定为值来完成的。请注意:
在计算时间戳时,使用包含在所编写的Amazon对象中的最古老记录的近似到达时间戳。
而这一点:
如果指定不包含时间戳命名空间表达式的前缀,则KinsisDataFirehos将表达式!{时间戳:yyyy/MM/dd/HH/}追加到前缀字段中的值。
(因此,如果不使用timestamp命名空间,则使用旧的分区方式)
例如,其他名称空间还为错误输出前缀启用了按消防软管错误类型进行分区。
https://stackoverflow.com/questions/49699727
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号