
无法使用pyhdf读取HDF4数据集(pyhdf.error.HDF4Error: select:不存在数据集)
我正在尝试读取一个HDF4文件(https://www.dropbox.com/s/5d40ukfsu0yupwl/MOD13A2.A2016001.h23v05.006.2016029070140.hdf?dl=0)。
import os
import numpy as np
from pyhdf.SD import SD, SDC
# Open file.
FILE_NAME = 'MOD13A2.A2016001.h23v05.006.2016029070140.hdf'
hdf = SD(FILE_NAME, SDC.READ)
# List available SDS datasets.
print (hdf.datasets())
# Read dataset.
DATAFIELD_NAME="1_km_16_days_NDVI"
data2D = hdf.select(DATAFIELD_NAME)
data = data2D[:,:] 当我执行这个脚本时,我得到以下错误:跟踪(最近一次调用):文件"Test.py",第15行,在data2D = hdf.select(DATAFIELD_NAME)文件"C:\Python35\lib\site-packages\pyhdf\SD.py“中,第1599行,在选择raise HDF4Error(" select : non”) pyhdf.error.HDF4Error: select: non中
我使用了类似的python代码来读取其他HDF4文件,并且运行良好。但在这种情况下,我无法理解问题所在。
回答 1
Stack Overflow用户
发布于 2018-04-06 07:08:22
如果仔细查看print(hdf.datasets())的输出,就会注意到以下一行:
...
'1 km 16 days NDVI': (('YDim:MODIS_Grid_16DAY_1km_VI',
'XDim:MODIS_Grid_16DAY_1km_VI'),
(1200, 1200),
22,
0),
...键是数据集的名称。注意,名称使用空格分隔单词,而不是像示例中那样使用下划线。
如果您将DATAFIELD_NAME替换为DATAFIELD_NAME='1 km 16 days NDVI'。即用数据集名称中的空格替换下划线,您的代码将在没有错误的情况下工作。
这足以访问地砖中的数据,但是地理定位需要更多的工作。目前,您已经可以将数据可视化
from matplotlib import pyplot as plt
plt.imshow(data)
plt.colorbar()
plt.show()
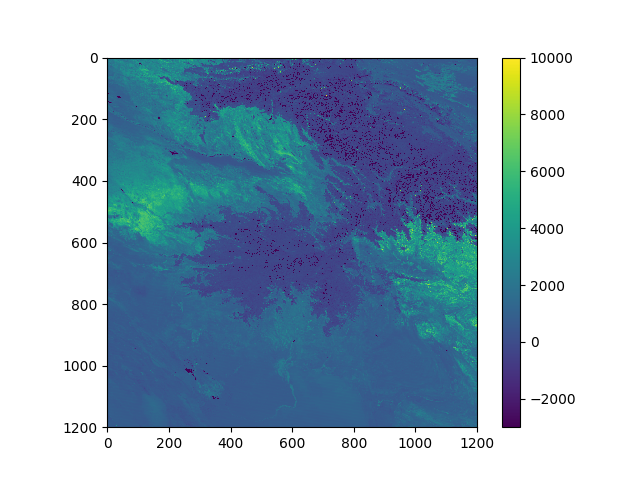
剩下要做的是
- 向科学单位标度
- 地理定位
另外,请使用pprint模块输出结构复杂的大型字典,即将print(hdf.datasets())替换为
import pprint
...
pprint.pprint(hdf.datasets())https://stackoverflow.com/questions/49670685
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号