
使用熊猫规范化的嵌套json到csv
使用熊猫规范化的嵌套json到csv
提问于 2018-04-04 11:51:53
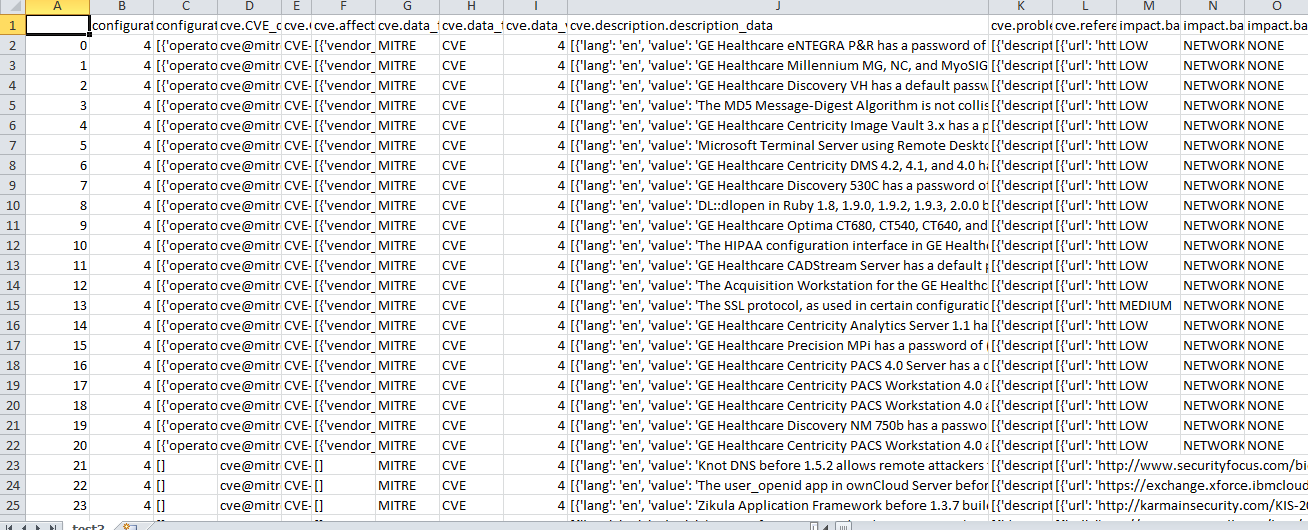
通过给定的脚本,我能够获得输出,就像我在屏幕截图中显示的那样,但是有一个名为cve.description.description_data的列,它再次以json格式出现。我也想提取这些数据。
import json
import pandas as pd
from pandas.io.json import json_normalize
#load json object
with open('nvdcve-1.0-modified.json') as f:
d = json.load(f)
#tells us parent node is 'programs'
nycphil = json_normalize(d['CVE_Items'])
nycphil.head(3)
works_data = json_normalize(data=d['CVE_Items'], record_path='cve')
works_data.head(3)
nycphil.to_csv("test4.csv")如果我更改了works_data = json_normalize(data=d['CVE_Items'], record_path='cve.descr'),就会出现以下错误:
“KeyError= resultspec KeyError:'cve.description'”
JSON格式如下:
{
"CVE_data_type":"CVE",
"CVE_data_format":"MITRE",
"CVE_data_version":"4.0",
"CVE_data_numberOfCVEs":"1000",
"CVE_data_timestamp":"2018-04-04T00:00Z",
"CVE_Items":[
{
"cve":{
"data_type":"CVE",
"data_format":"MITRE",
"data_version":"4.0",
"CVE_data_meta":{
"ID":"CVE-2001-1594",
"ASSIGNER":"cve@mitre.org"
},
"affects":{
"vendor":{
"vendor_data":[
{
"vendor_name":"gehealthcare",
"product":{
"product_data":[
{
"product_name":"entegra_p&r",
"version":{
"version_data":[
{
"version_value":"*"
}
]
}
}
]
}
}
]
}
},
"problemtype":{
"problemtype_data":[
{
"description":[
{
"lang":"en",
"value":"CWE-255"
}
]
}
]
},
"references":{
"reference_data":[
{
"url":"http://apps.gehealthcare.com/servlet/ClientServlet/2263784.pdf?DOCCLASS=A&REQ=RAC&DIRECTION=2263784-100&FILENAME=2263784.pdf&FILEREV=5&DOCREV_ORG=5&SUBMIT=+ ACCEPT+"
},
{
"url":"http://www.forbes.com/sites/thomasbrewster/2015/07/10/vulnerable- "
},
{
"url":"https://ics-cert.us-cert.gov/advisories/ICSMA-18-037-02"
},
{
"url":"https://twitter.com/digitalbond/status/619250429751222277"
}
]
},
"description":{
"description_data":[
{
"lang":"en",
"value":"GE Healthcare eNTEGRA P&R has a password of (1) value."
}
]
}
},
"configurations":{
"CVE_data_version":"4.0",
"nodes":[
{
"operator":"OR",
"cpe":[
{
"vulnerable":true,
"cpe22Uri":"cpe:/a:gehealthcare:entegra_p%26r",
"cpe23Uri":"cpe:2.3:a:gehealthcare:entegra_p\\&r:*:*:*:*:*:*:*:*"
}
]
}
]
},
"impact":{
"baseMetricV2":{
"cvssV2":{
"version":"2.0",
"vectorString":"(AV:N/AC:L/Au:N/C:C/I:C/A:C)",
"accessVector":"NETWORK",
"accessComplexity":"LOW",
"authentication":"NONE",
"confidentialityImpact":"COMPLETE",
"integrityImpact":"COMPLETE",
"availabilityImpact":"COMPLETE",
"baseScore":10.0
},
"severity":"HIGH",
"exploitabilityScore":10.0,
"impactScore":10.0,
"obtainAllPrivilege":false,
"obtainUserPrivilege":false,
"obtainOtherPrivilege":false,
"userInteractionRequired":false
}
},
"publishedDate":"2015-08-04T14:59Z",
"lastModifiedDate":"2018-03-28T01:29Z"
}
]
}我想把所有的数据都压平。
回答 1
Stack Overflow用户
发布于 2018-04-04 15:30:00
假设多个URL在行和所有其他元数据重复之间进行描述,则考虑一个递归函数调用来提取嵌套json对象d中的每个键值对。
递归函数将调用global来更新需要绑定到用于pd.DataFrame()调用的字典列表中的全局对象。最后一个循环更新递归函数的内部字典,以集成不同的urls (存储在多个urls中)
import json
import pandas as pd
# load json object
with open('nvdcve-1.0-modified.json') as f:
d = json.load(f)
multi = []; inner = {}
def recursive_extract(i):
global multi, inner
if type(i) is list:
if len(i) == 1:
for k,v in i[0].items():
if type(v) in [list, dict]:
recursive_extract(v)
else:
inner[k] = v
else:
multi = i
if type(i) is dict:
for k,v in i.items():
if type(v) in [list, dict]:
recursive_extract(v)
else:
inner[k] = v
recursive_extract(d['CVE_Items'])
data_dict = []
for i in multi:
tmp = inner.copy()
tmp.update(i)
data_dict.append(tmp)
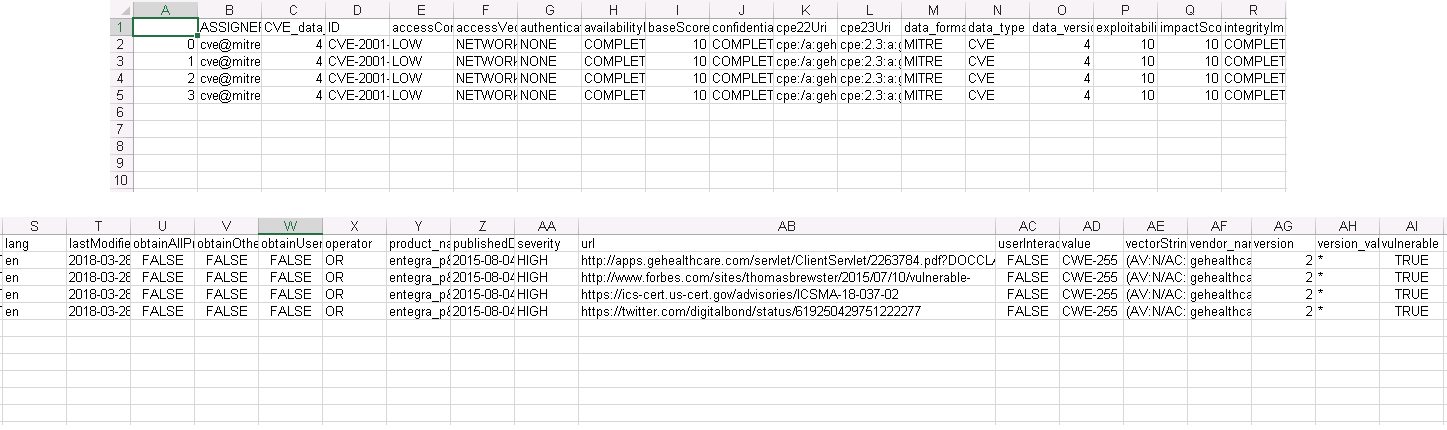
df = pd.DataFrame(data_dict)
df.to_csv('Output.csv')输出(除URL外,所有列均相同,为强调而加宽)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/49650304
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号