
如何用collections.FreqItemset处理来自FPGrowth的PySpark?
如何用collections.FreqItemset处理来自FPGrowth的PySpark?
提问于 2018-03-28 17:08:20
我使用的是FPGrowth,这个函数的输出是collections.FreqItemset类型,我不太熟悉它,我发现使用起来很困难,我找不到太多的文档或例子。--这是我的问题,有没有办法在Python3中使用这种格式?如何处理呢?这种格式是从哪里来的?,因为我对如何在Python3上处理这个问题知之甚少,我试着把它转换成我更熟悉的东西,例如熊猫数据。不过,我觉得这是一种肮脏。所以我把我的时间解决方案留在这里等待你们的洞察力。
以文档中的示例为例,将FPGRowth用于python,即这里。
在火星雨中建立环境
import pyspark
sc = pyspark.SparkContext('local[*]')要在示例中运行函数并查看结果,请执行以下操作:
from pyspark.mllib.fpm import FPGrowth
data = sc.textFile("sample_fpgrowth.txt")
transactions = data.map(lambda line: line.strip().split(' '))
model = FPGrowth.train(transactions, minSupport=0.2, numPartitions=10)
result = model.freqItemsets().collect()
for fi in result:
print(fi)如果没有找到该示例的文件,则可以获得这里。输出是这样的

下面这个家伙:输入collections.FreqItemse,我不知道如何在Python中正确处理。
所以我用这种肮脏的方式把它转化成熊猫的数据中心是这样的:
import pandas as pd
df = pd.DataFrame(columns = [0])
for fi in result:
df.loc[''.join(str(e)+' ' for e in fi.items)[0:-1]] = int(fi.freq)
df.head()什么将产生这样的结果:
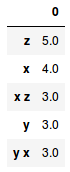
提前感谢您的帮助。
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-01-24 20:06:40
你快到了。而不是使用
for fi in result:
print(fi)使用这个
for fi in result:
print (''.join(fi['items']),fi['freq'])或者这个
for items,frequency in result:
print (''.join(items),frequency)这里的条目是一个简单的python列表,频率应该是一个整数。它可能不会像熊猫的数据一样漂亮,但我猜你想要的是获取这些值。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/49540419
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号