
为什么在运行1TB时没有还原剂?
为什么在运行1TB时没有还原剂?
提问于 2018-03-27 09:21:20
我使用以下命令运行hadoop的terasort基准测试:
jar /Users/karan.verma/Documents/backups/h/hadoop-2.6.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar teragen -Dmapreduce.job.maps=100 1t random-data并为100个地图任务打印了以下日志:
18/03/27 13:06:03 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/03/27 13:06:04 INFO client.RMProxy: Connecting to ResourceManager at /127.0.0.1:8032
18/03/27 13:06:05 INFO terasort.TeraSort: Generating -727379968 using 100
18/03/27 13:06:05 INFO mapreduce.JobSubmitter: number of splits:100
18/03/27 13:06:05 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1522131782827_0001
18/03/27 13:06:06 INFO impl.YarnClientImpl: Submitted application application_1522131782827_0001
18/03/27 13:06:06 INFO mapreduce.Job: The url to track the job: http://localhost:8088/proxy/application_1522131782827_0001/
18/03/27 13:06:06 INFO mapreduce.Job: Running job: job_1522131782827_0001
18/03/27 13:06:16 INFO mapreduce.Job: Job job_1522131782827_0001 running in uber mode : false
18/03/27 13:06:16 INFO mapreduce.Job: map 0% reduce 0%
18/03/27 13:06:29 INFO mapreduce.Job: map 2% reduce 0%
18/03/27 13:06:31 INFO mapreduce.Job: map 3% reduce 0%
18/03/27 13:06:32 INFO mapreduce.Job: map 5% reduce 0%
....
18/03/27 13:09:27 INFO mapreduce.Job: map 100% reduce 0%下面是打印在控制台上的最终计数器:
18/03/27 13:09:29 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=10660990
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=8594
HDFS: Number of bytes written=0
HDFS: Number of read operations=400
HDFS: Number of large read operations=0
HDFS: Number of write operations=200
Job Counters
Launched map tasks=100
Other local map tasks=100
Total time spent by all maps in occupied slots (ms)=983560
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=983560
Total vcore-milliseconds taken by all map tasks=983560
Total megabyte-milliseconds taken by all map tasks=1007165440
Map-Reduce Framework
Map input records=0
Map output records=0
Input split bytes=8594
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=9746
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=11220811776
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0以下是作业计划的输出:
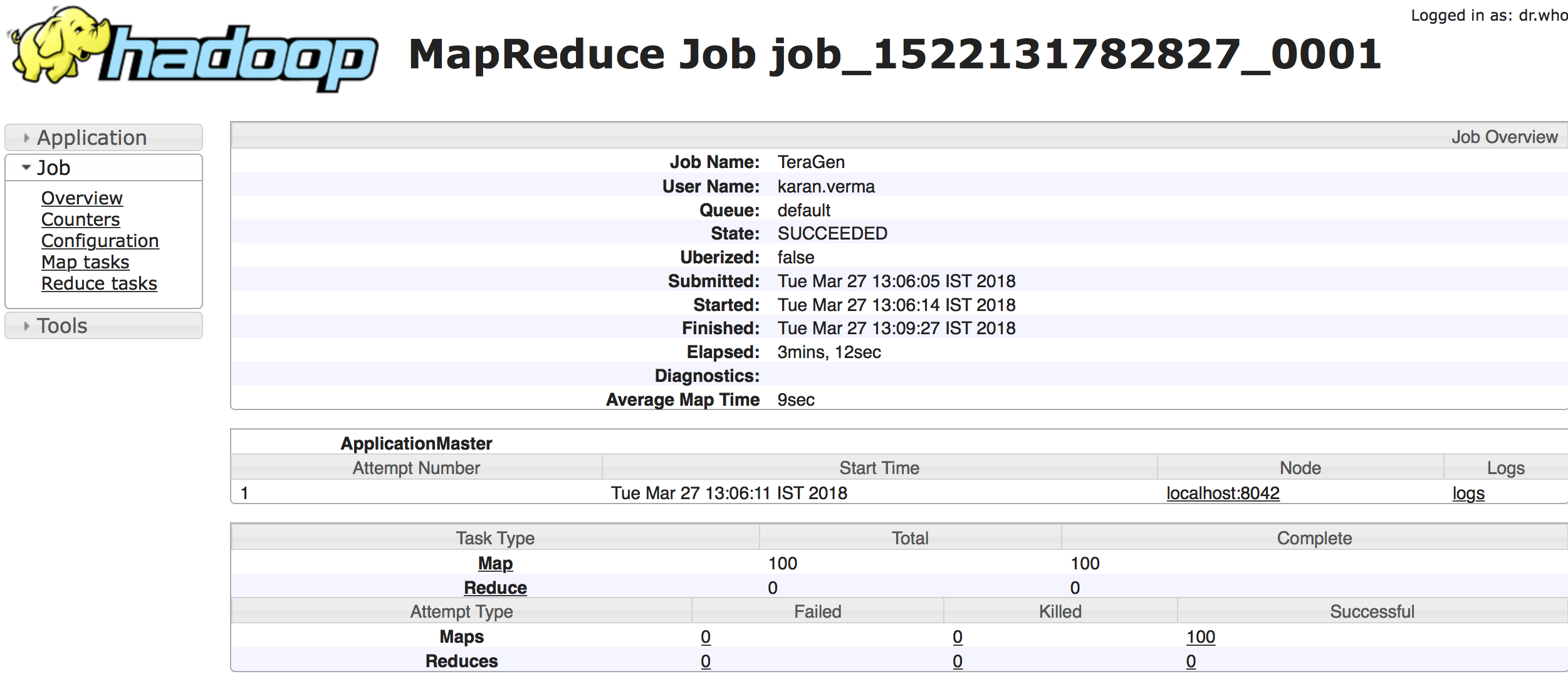
请提出为什么没有减少任务?
回答 2
Stack Overflow用户
回答已采纳
发布于 2018-03-27 09:41:14
您的run命令显示您正在运行teragen,而不是terasort。teragen只生成您可以用于terasort的数据,因此不需要还原器。
要在刚才生成的数据上运行terasort,请运行:
hadoop jar /Users/karan.verma/Documents/backups/h/hadoop-2.6.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar terasort random-data terasort-output然后你应该看到减速机。
Stack Overflow用户
发布于 2018-03-27 10:12:03
在执行teragen时不会运行任何减少任务。以下是文件:
TeraGen将运行映射任务来生成数据,并且不会运行任何减少任务。映射任务的默认数量由"mapreduce.job.maps=2“参数定义。这里唯一的目的是以以下格式生成随机数据的1TB:“10字节,键,2,字节,中断,32字节,acsii/十六进制,4字节,中断,48字节,填充,4字节,填充,4个字节,中断\r\n”。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/49508974
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号