
多元正态密度部分的有效计算方法
我对计算数量感兴趣:
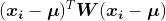
其中,x_i是1xD向量(维数N个中的一个),μ是DxK矩阵,W是K DxD矩阵的列表。
这将导致1XK向量。我以以下方式对所有N和K进行了尝试:
res = zeros(N,K);
for i in 1:N
for k in 1:K
res[i,k] = (x_matrix[i,:]-mus_matrix[:,k])'*
w_matrix[k]*(x_matrix[i,:]-mus_matrix[:,k])如果我尝试将其矢量化,请使用以下方法:
res = zeros(N,K);
for i in 1:N
res[i,:] = (x_matrix[i,:].-mus_matrix)'.*w_matrix.*(x_matrix[i,:].-mus_matrix)我得到以下错误:
ERROR: DimensionMismatch("arrays could not be broadcast to a common size")
Stacktrace:
[1] _bcs1(::Base.OneTo{Int64}, ::Base.OneTo{Int64}) at ./broadcast.jl:70
[2] _bcs at ./broadcast.jl:63 [inlined]
[3] broadcast_shape(::Tuple{Base.OneTo{Int64},Base.OneTo{Int64}}, ::Tuple{Base.OneTo{Int64}}, ::Tuple{Base.OneTo{Int64},Base.OneTo{Int64}}, ::Vararg{Tuple{Base.OneTo{Int64},Base.OneTo{Int64}},N} where N) at ./broadcast.jl:57 (repeats 3 times)
[4] broadcast_indices(::Array{Float64,2}, ::Array{Any,1}, ::Array{Float64,1}, ::Vararg{Any,N} where N) at ./broadcast.jl:53
[5] broadcast_c(::Function, ::Type{Array}, ::Array{Float64,2}, ::Array{Any,1}, ::Vararg{Any,N} where N) at ./broadcast.jl:311
[6] broadcast(::Function, ::Array{Float64,2}, ::Array{Any,1}, ::Array{Float64,1}, ::Vararg{Any,N} where N) at ./broadcast.jl:434下面是一个示例:
julia> N = 5
5
julia> D=2
2
julia> K = 4
4
julia> W=[]
0-element Array{Any,1}
julia> x = rand(N,D)
5×2 Array{Float64,2}:
0.576477 0.9575
0.184454 0.660436
0.470267 0.729649
0.648879 0.782561
0.626453 0.111332
julia> mu = rand(K,D)
4×2 Array{Float64,2}:
0.989281 0.00126782
0.659106 0.66136
0.50843 0.289442
0.327962 0.523229
julia> for i in 1:K
push!(W,rand(D,D))
end然后跑
julia> (x_matrix[i,:]-mus_matrix[:,k])'*
w_matrix[k]*(x_matrix[i,:]-mus_matrix[:,k])
34649.850360744866但是用第二个代码
julia> (x_matrix[i,:].-mus_matrix)'.*w_matrix.*(x_matrix[i,:].-mus_matrix)
ERROR: DimensionMismatch("arrays could not be broadcast to a common size")
Stacktrace:
[1] _bcs1(::Base.OneTo{Int64}, ::Base.OneTo{Int64}) at ./broadcast.jl:70
[2] _bcs at ./broadcast.jl:63 [inlined]
[3] broadcast_shape(::Tuple{Base.OneTo{Int64},Base.OneTo{Int64}}, ::Tuple{Base.OneTo{Int64}}, ::Tuple{Base.OneTo{Int64},Base.OneTo{Int64}}, ::Vararg{Tuple{Base.OneTo{Int64},Base.OneTo{Int64}},N} where N) at ./broadcast.jl:57 (repeats 3 times)
[4] broadcast_indices(::Array{Float64,2}, ::Array{Any,1}, ::Array{Float64,1}, ::Vararg{Any,N} where N) at ./broadcast.jl:53
[5] broadcast_c(::Function, ::Type{Array}, ::Array{Float64,2}, ::Array{Any,1}, ::Vararg{Any,N} where N) at ./broadcast.jl:311
[6] broadcast(::Function, ::Array{Float64,2}, ::Array{Any,1}, ::Array{Float64,1}, ::Vararg{Any,N} where N) at ./broadcast.jl:434回答 1
Stack Overflow用户
发布于 2018-03-27 08:37:21
TL/DR:下面的优化变体,但Einsum看起来更好,IMHO。
看起来像一个使用爱因斯坦求和符号的例子。在朱莉娅,Einsum.jl可以这样做:
julia> N = 5
5
julia> D = 3
3
julia> K = 10
10
julia> x = rand(N, D)
5×3 Array{Float64,2}:
0.587436 0.210529 0.261725
0.527269 0.457477 0.482939
0.52726 0.411209 0.138872
0.89107 0.464789 0.758392
0.885267 0.931014 0.672959
julia> μ = rand(D, K)
3×10 Array{Float64,2}:
0.280792 0.265066 0.81437 0.503377 0.0717916 … 0.275872 0.609961 0.0820088 0.0042564
0.0177643 0.0959438 0.563948 0.332433 0.088527 0.691971 0.0296638 0.604488 0.956057
0.668128 0.444816 0.74203 0.518232 0.48689 0.465067 0.117469 0.729514 0.109973
julia> W = rand(K, D, D)
10×3×3 Array{Float64,3}:
[:, :, 1] =
0.320861 0.662103 0.219234
0.780944 0.769377 0.566203
0.466207 0.428527 0.330901
0.15534 0.035435 0.346737
0.810676 0.328116 0.469505
0.676575 0.668204 0.285334
0.455551 0.211295 0.85295
0.229995 0.741487 0.783361
0.0937583 0.401419 0.47032
0.956335 0.434213 0.967791
[:, :, 2] =
0.275903 0.130298 0.184485
0.941648 0.940107 0.439454
0.425292 0.252654 0.797115
0.0203406 0.594075 0.484809
0.164309 0.941597 0.455314
0.73628 0.109502 0.920664
0.906305 0.177235 0.540193
0.360038 0.0486971 0.20626
0.914357 0.699901 0.295872
0.284143 0.659117 0.291479
[:, :, 3] =
0.138311 0.921371 0.353719
0.345247 0.70865 0.246736
0.361364 0.636543 0.343837
0.752149 0.581561 0.346399
0.705888 0.24765 0.703952
0.992327 0.369668 0.109407
0.341624 0.223715 0.970667
0.762169 0.94248 0.917569
0.0367128 0.589345 0.121106
0.826602 0.692111 0.229499
julia> using Einsum
julia> @einsum r[n,k] := (x[n,i] - μ[i,k]) * W[k,i,j] * (x[n,j] - μ[j,k])
julia> r
5×10 Array{Float64,2}:
0.0176889 0.087092 0.522184 0.0417967 … -0.0430999 0.041266 -0.0596579 0.432076
0.0521066 0.364059 0.181515 0.00434307 -0.0248712 0.226976 -0.0686294 0.437169
-0.0472136 0.127803 0.458812 0.0119074 0.0391649 -0.0190299 -0.0585371 0.264379
0.468634 1.16498 -0.00263205 0.192809 0.273537 1.13787 -0.0653081 1.41321
0.749655 2.20266 0.0205068 0.420249 0.573358 1.42499 0.441232 1.67574 哪个@macroexpand本质上是下面的循环(加上准备和边界检查):
begin
local k
for k = 1:size(μ, 2)
begin
local n
for n = 1:size(x, 1)
begin
local s = zero(T)
begin
local j
for j = 1:size(W, 3)
begin
local i
for i = 1:size(x, 2)
s += (x[n, i] - μ[i, k]) * W[k, i, j] * (x[n, j] - μ[j, k])
end
end
end
end
r[n, k] = s
end
end
end
end
end现在,为了找到更好的性能,我比较了几个使用BenchmarkTools.jl的变体。您可以在我的笔记本电脑这里上看到完整的代码和结果。它表明,Einsum变体实际上比原来的要好:
# Original:
# memory estimate: 1017.73 MiB
# allocs estimate: 3429967
# median time: 361.982 ms (15.94% GC)
# Einsum:
# memory estimate: 2.64 MiB
# allocs estimate: 76
# median time: 127.536 ms (0.00% GC)到目前为止,最有效和分配最少的变量是以下几个,它需要x = x'和W = permutedims(W, [2, 3, 1]) (假设您可以轻松地更改表示):
function test_optimized!(res, x, μ, W)
z = zero(eltype(x))
for k = 1:size(μ, 1)
for n = 1:size(x, 1)
res[n, k] = z
for i = 1:size(W, 1)
for j = 1:size(W, 2)
@inbounds res[n, k] += (x[i, n] - μ[i, k]) * W[i, j, k] * (x[j, n] - μ[j, k])
end
end
end
end
end
function test_optimized(x, μ, W)
res = zeros(N, K)
test_optimized!(res, x, μ, W)
res
end这就把我们带到
# memory estimate: 2.63 MiB
# allocs estimate: 2
# median time: 521.215 μs (0.00% GC)它使用了一些可以找到在医生里的“技巧”:在一个单独的方法中填充预先分配的矩阵,按列的主要顺序访问大步,并使用@inbounds (尽管这只会以微秒的顺序改进事情)。
还有TensorOperations.jl,我认为它在引擎盖下做更智能的事情,但是它失败了:
julia> @tensor r[n,k] := (x[n,i] - μ[i,k]) * W[k,i,j] * (x[n,j] - μ[j,k])
ERROR: TensorOperations.IndexError{String}("invalid index specification: (:n, :i) to (:i, :k)")
Stacktrace:
[1] add_indices(::Tuple{Symbol,Symbol}, ::Tuple{Symbol,Symbol}) at /home/philipp/.julia/v0.6/TensorOperations/src/implementation/indices.jl:22
[2] + at /home/philipp/.julia/v0.6/TensorOperations/src/indexnotation/sum.jl:40 [inlined]
[3] -(::TensorOperations.IndexedObject{(:n, :i),:N,Array{Float64,2},Int64}, ::TensorOperations.IndexedObject{(:i, :k),:N,Array{Float64,2},Int64}) at /home/philipp/.julia/v0.6/TensorOperations/src/indexnotation/sum.jl:44我想这是故意的,与效率有关,参见本期。
https://stackoverflow.com/questions/49501082
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号