
从Dataset map()函数调用中生成的图形操作中添加Tensorboard摘要
我发现Dataset.map()功能非常好,可以在输入网络进行培训之前设置管道对图像/音频数据进行预处理,但我遇到的一个问题是在预处理之前访问原始数据,然后将其作为摘要发送到张量板。
例如,假设我有一个函数来加载音频数据,做一些框架,制作一个谱图,然后返回这个。
import tensorflow as tf
def load_audio_examples(label, path):
# loads audio, converts to spectorgram
pcm = ... # this is what I'd like to put into tf.summmary.audio() !
# creates one-hot encoded labels, etc
return labels, examples
# create dataset
training = tf.data.Dataset.from_tensor_slices((
tf.constant(labels),
tf.constant(paths)
))
training = training.map(load_audio_examples, num_parallel_calls=4)
# create ops for training
train_step = # ...
accuracy = # ...
# create iterator
iterator = training.repeat().make_one_shot_iterator()
next_element = iterator.get_next()
# ready session
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
train_writer = # ...
# iterator
test_iterator = testing.make_one_shot_iterator()
test_next_element = iterator.get_next()
# train loop
for i in range(100):
batch_ys, batch_xs, path = sess.run(next_element)
summary, train_acc, _ = sess.run([summaries, accuracy, train_step],
feed_dict={x: batch_xs, y: batch_ys})
train_writer.add_summary(summary, i) 看起来,这似乎没有成为图形的一部分,该图表是在张卡的“图”选项卡中绘制的(见下面的屏幕快照)。
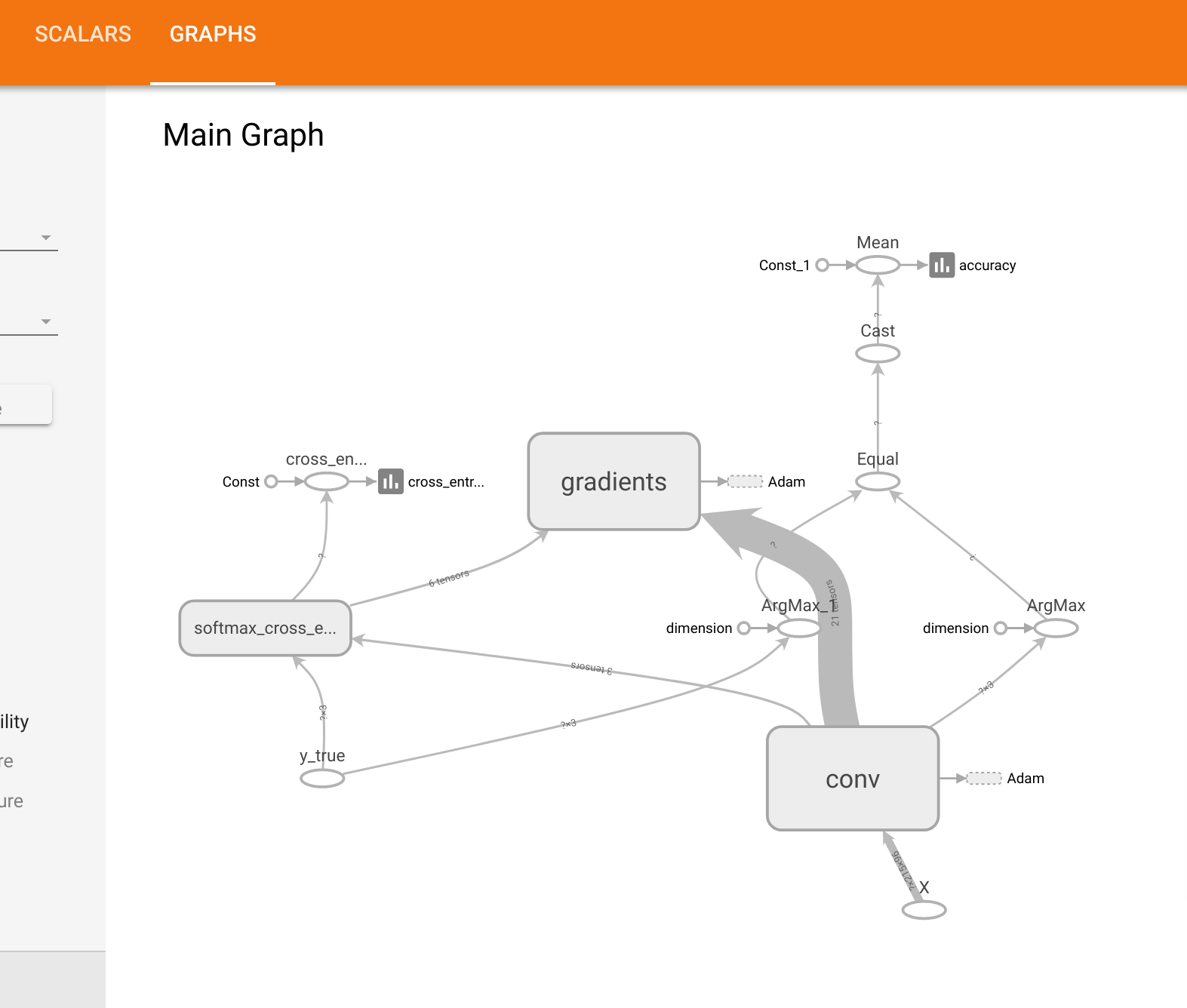
如您所见,它只是X(预处理map()函数的输出)。
- 我如何更好地构造这个结构,将原始音频输入到
tf.summary.audio()中?现在,map()中的内容在我的训练循环中不能作为张量访问。 - 另外,为什么我的图表没有出现在Tensorboard上?我担心我将无法导出我的模型或使用Tensorflow服务将我的模型投入生产,因为我正在使用新的Dataset API -也许我应该回到手工操作?(有队列等)。
回答 1
Stack Overflow用户
发布于 2018-04-03 07:38:54
我认为您对Dataset API的使用没有多大意义。事实上,你有两个不连通的子图。一个用于读取数据,另一个用于运行您的培训步骤。
batch_ys, batch_xs, path = sess.run(next_element)
summary, train_acc, _ = sess.run([summaries, accuracy, train_step],
feed_dict={x: batch_xs, y: batch_ys})上面代码中的第一行运行会话并从中获取数据项。它将数据从Tensorflow后端传输到Python。
下一行使用feed_dict提供数据,即据说效率很低。这一次,TensorFlow将数据从Python传输到运行时。
这会产生以下后果:
- 你的图看起来不相连
- TensorFlow浪费时间进行不必要的数据传输。
要有一个图(没有断开连接的子图),您需要在Dataset API返回的张量之上构建模型。请注意,可以在培训和测试数据集之间切换,而无需手动抓取批处理(请参见数据集指南)。
如果要谈论在map_fn中定义的摘要,我相信您可以从SUMMARIES集合中检索摘要(摘要的默认集合)。添加摘要操作时,还可以传递自己的集合名称。
https://stackoverflow.com/questions/49483025
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号