
为什么peakutils.peak.indexes()似乎忽略了提供的阈值?
我正在检索保存来自plt.psd()方法的信号的功率级别和频率的数组:
Pxx, freqs = plt.psd(signals[0], NFFT=2048, Fs=sdr.sample_rate/1e6, Fc=sdr.center_freq/1e6, scale_by_freq=True, color="green")
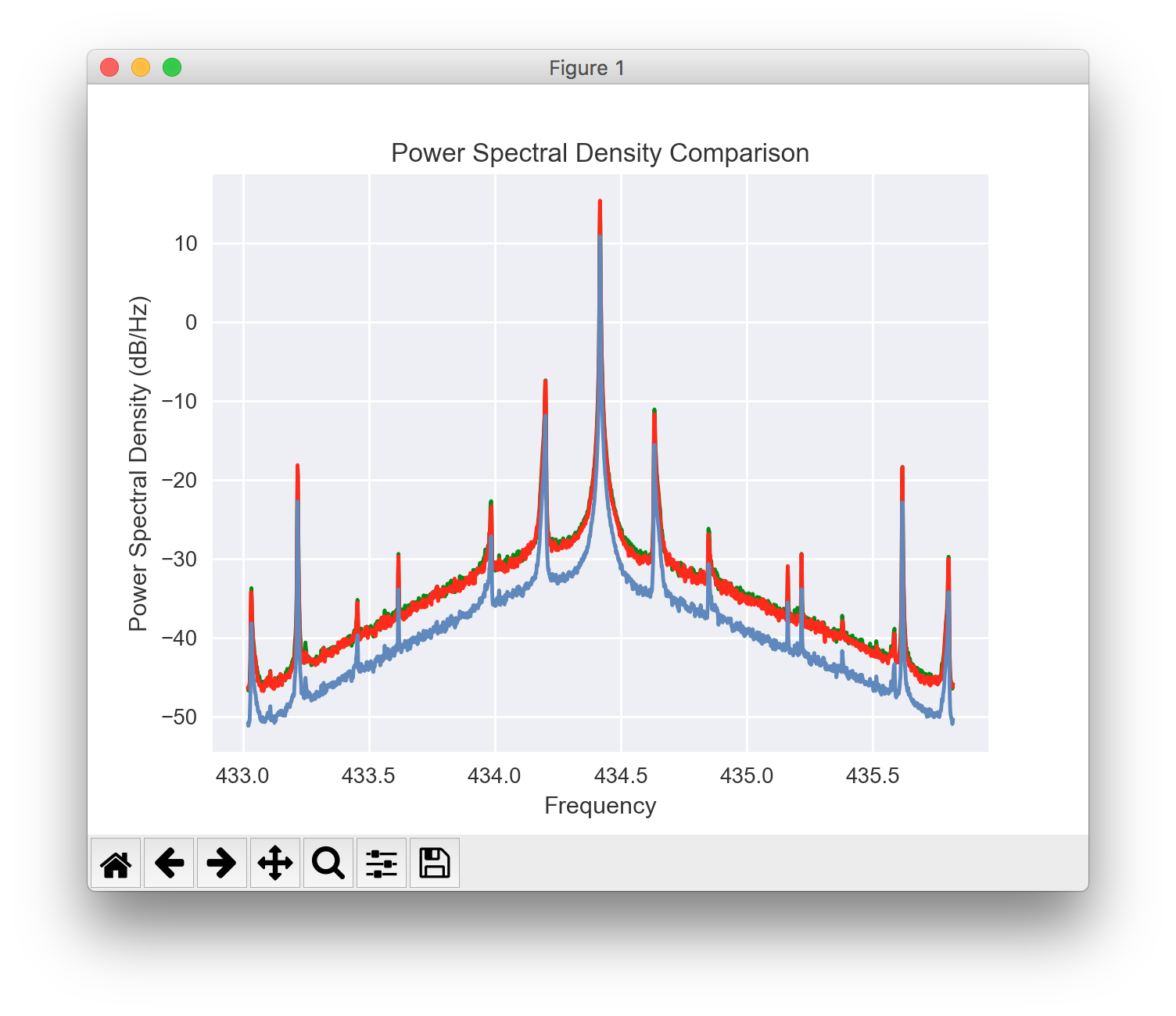
请忽略绿色和红色的信号。只有蓝色的那个与这个问题有关。
我可以让peakutils.peak.indexes()方法返回一些最重要的峰值(蓝色信号)的X和Y坐标:
power_lvls = 10*log10(Pxx/(sdr.sample_rate/1e6))
indexes = peakutils.peak.indexes(np.array(power_lvls), thres=0.6/max(power_lvls), min_dist=120)
print("\nX: {}\n\nY: {}\n".format(freqs[indexes], np.array(power_lvls)[indexes]))
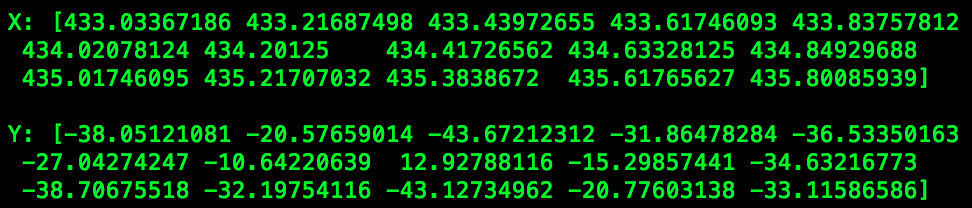
可以看到,坐标很好地与蓝色峰相吻合。
我不满意的是从peak.indexes()方法接收到的峰值坐标的数量。我只希望返回某个功率电平以上的所有峰的坐标,例如-25 (这将正是蓝色信号的5个峰值)。根据peak.indexes()方法的文档,这是通过提供所需的值作为thres参数来完成的。
但是,不管我作为thres尝试了什么,该方法似乎完全忽略了我的值,而仅仅依靠min_dist参数来确定返回峰值的数量。
- 我的阈值有什么问题(在我的代码中,它的意思是“地形图的60%以上的峰值”),以及如何正确地指定某个功率级别(而不是百分比值)?
编辑
我发现,很明显,thres参数只能在浮点数0之间取正值。1.因此,通过将行稍微更改如下,我现在可以按需要影响返回峰值的数量:
indexes = peakutils.peak.indexes(np.array(power_lvls), thres=0.4, min_dist=1)但这仍然给我留下了一个问题:是否有可能将结果限制在五个最高峰值(假设num_of_peaks高于>= 5)。
我相信以下内容将返回五个最高值:
print(power_lvls[np.argsort(power_lvls[indexes])[-5:]])不幸的是,负值似乎被解释为我的power_lvls数组中的最高值。这一行是否可以改为(+)10将被认为高于,例如-40?或者还有其他的(更好的)?解决办法?
编辑2
这些是我作为六个“最高”山峰得到的值:

power_lvls = 10*log10(Pxx/(sdr.sample_rate/1e6))+10*log10(8/3)
indexes = peakutils.indexes(power_lvls, thres=0.35, min_dist=1)
power_lvls_max = power_lvls[np.argsort(power_lvls[indexes])[-6:]]
print("Highest Peaks in Signal:\nX: \n\nY: {}\n".format(power_lvls_max))经过几个小时的尝试没有任何改善,我开始认为这些不是山谷或高峰,只是一些“随机”的值?!这让我相信,我的辩论线有一个问题,我必须先弄清楚?!
编辑3
bottleneck.partition()方法似乎返回正确的值(即使显然它是以随机顺序进行的,而不是从最左的峰值返回到最右边的峰值):
import bottleneck as bn
power_lvls_max = -bn.partition(-power_lvls[indexes], 6)[:6]
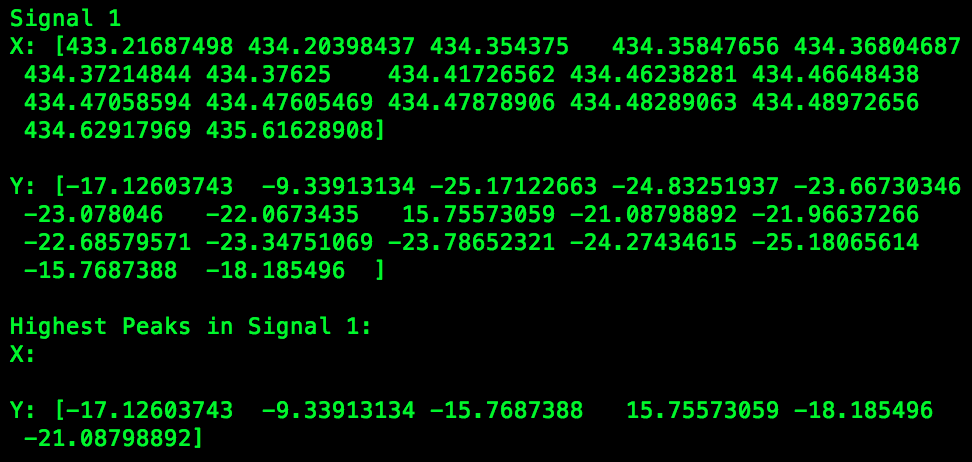
幸运的是,对于我计划对坐标所做的工作来说,峰的顺序并不重要。然而,我必须想出如何将我现在拥有的Y值与它们对应的X值相匹配.
另外,虽然我现在有了一个解决方案,但为了学习的目的,知道我的论证尝试有什么问题还是很有趣的。
回答 2
Stack Overflow用户
发布于 2018-03-26 22:16:53
我想出了如何找到对应的X值,并得到六个最高峰的全部坐标:
power_lvls = 10*log10(Pxx/(sdr.sample_rate/1e6))+10*log10(8/3)
indexes = peakutils.indexes(power_lvls, thres=0.35, min_dist=1)
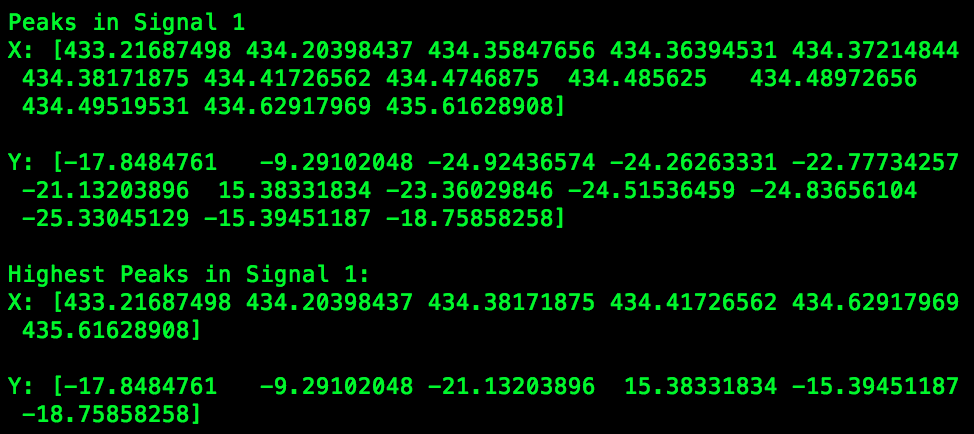
print("Peaks in Signal 1\nX: {}\n\nY: {}\n".format(freqs[indexes], power_lvls[indexes]))
power_lvls_max = -bn.partition(-power_lvls[indexes], 6)[:6]
check = np.isin(power_lvls, power_lvls_max)
indexes_max = np.where(check)
print("Highest Peaks in Signal 1:\nX: {}\n\nY: {}\n".format(freqs[indexes_max], power_lvls[indexes_max]))现在,我有了我的“峰值过滤”(类似),我最初试图通过混淆peakutils.peak.indexes()的peakutils.peak.indexes值来实现它。上面的代码给了我想要的结果:
Stack Overflow用户
发布于 2018-03-26 00:44:29
解决这一问题的一个简单方法是在处理之前向Pxx向量添加一个常量(例如+50 dB)。这样你就可以避免负价值的峰值。处理完成后,您可以再次减去常量,以获得正确的峰值。
https://stackoverflow.com/questions/49477943
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号