
熊猫MultiIndex,按1级和2级选择值
在1.level和2.level中选择值会出现一些问题。
我通过设置MultiIndex获得了一个
header = [0,1]
In[1]: df = pd.read_csv('Data.txt', sep='\t', header=[0,1], skipinitialspace=True)
In[2]: print(df.columns)
Out[2]: MultiIndex(
levels=[['20052065', '20052066', '20052082', '20052087', '20052089'],
['CTF1', 'CTF2', 'CTF3', 'CTF_M', 'CTM1', 'CTM2', 'CTM3', 'CTM_M']],
labels=[[...]],
names=[...])如果它试图从1.level获取2级值和选定元素的数据,我将得到以下输出:
In[3]: print(df['20052065'][['CTF1','CTF_M']])
Out[3]: TIME[s] CTF1 CTF_M
0.000 -14.386 14.963
60.000 -26.937 34.729
120.000 -29.986 58.265
... ... ...现在,我尝试为两个元素生成输出,并执行如下操作:
In[4]: print(df[['20052065','20052066']][['CTF1','CTF_M']])
Out[4]: KeyError: "['CTF1' 'CTF_M'] not in index"不知怎么的,这不管用。也许你知道哪里出了大错?
谢谢你帮忙。
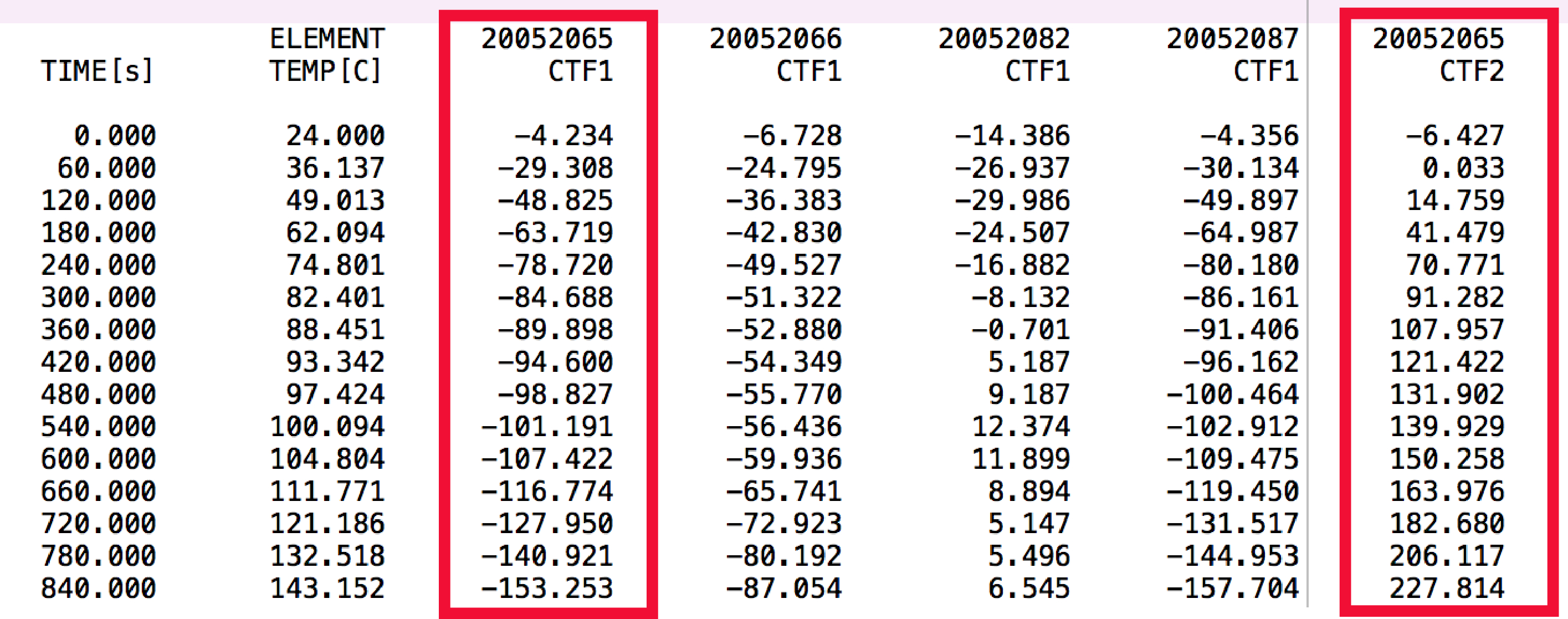
编辑: In[1]: print(df)看起来如下:
Out[1]: ELEMENT 20052065 20052066 20052082 20052087 20052089 20052090 \
TIME[s] TEMP[C] CTF1 CTF1 CTF1 CTF1 CTF1 CTF1
0.000 24.000 -4.234 -6.728 -14.386 -4.356 -6.926 -10.205
60.000 36.137 -29.308 -24.795 -26.937 -30.134 -24.735 -23.474
... ... ... ... ... ... ... ...*.txt文件看起来像:
回答 2
Stack Overflow用户
发布于 2018-03-25 15:25:32
你可以用df.loc
import numpy as np
import pandas as pd
columns = pd.MultiIndex.from_product([['A','B','C'],['X','Y','Z']])
df = pd.DataFrame(np.random.randint(10, size=(3,len(columns))), columns=columns)
# A B C
# X Y Z X Y Z X Y Z
# 0 2 7 5 1 6 0 5 0 0
# 1 8 4 7 2 0 8 7 3 9
# 2 0 6 8 8 1 1 8 0 2
# In some cases `sort_index` may be needed to avoid UnsortedIndexError
df = df.sort_index(axis=1)
print(df.loc[:, (['A','B'],['X','Y'])])收益(类似):
A B
X Y X Y
0 2 7 1 6
1 8 4 2 0
2 0 6 8 1如果您只想选择,比方说,('A','Y')和('B','X')列,那么请注意,您可以将MultiIndexed列指定为元组:
In [37]: df.loc[:, [('A','Y'),('B','X')]]
Out[37]:
A B
Y X
0 7 1
1 4 2
2 6 8甚至只有df[[('A','Y'),('B','X')]] (这会产生相同的结果)。
一般来说,最好使用单个索引器(如df.loc[...] ),而不是双索引(例如df[...][...])。它可能会更快(因为它对__getitem__的调用更少,生成的临时子DataFrames也更少)和df.loc[...] = value --向修改df本身的DataFrame的子片分配任务是正确的方式。
df[['A','B']][['X','Y']]不能工作的原因是df[['A','B']]返回带有MultiIndex的DataFrame:
In [36]: df[['A','B']]
Out[36]:
A B
X Y Z X Y Z
0 2 7 5 1 6 0
1 8 4 7 2 0 8
2 0 6 8 8 1 1所以用['X','Y']索引这个['X','Y']失败了,因为没有顶级的列标签名为'X'或'Y'。
有时,根据DataFrame的构造方式(或者由于在DataFrame上执行的操作),需要对MultiIndex进行词汇排序,然后才能将其切片。有一个文档中的装箱警告提到了这个问题。若要对列索引进行词汇排序,请使用
df = df.sort_index(axis=1)Stack Overflow用户
发布于 2018-03-25 15:20:22
我想需要切片机
print (df)
20052065 20052066 20052065 20052066 20052065 20052066
CTF1 CTF_M CTF_M1 CTF_Mr V A
0 1 2 4 5 6 7
df = df.sort_index(axis=1)
idx = pd.IndexSlice
print (df.loc[:, idx[['20052065','20052066'], ['CTF1','CTF_M']]])
20052065 20052066
CTF1 CTF_M
0 1 2https://stackoverflow.com/questions/49477384
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号