
huxtable表格的单元格内分行符
我最近开始为表使用赫克斯表 R包,我对它印象深刻。然而,有一件事我似乎搞不懂,那就是如何在一个细胞中获得线段。这是我尝试过的
library(tidyverse)
library(huxtable)
cars <- mtcars %>%
mutate(car = rownames(.),
car = str_replace(car, " ", "\n")) %>%
slice(1:5) %>%
select(car, cyl, hp)
cars
# A tibble: 5 x 3
car cyl hp
<chr> <dbl> <dbl>
1 "Mazda\nRX4" 6.00 110
2 "Mazda\nRX4 Wag" 6.00 110
3 "Datsun\n710" 4.00 93.0
4 "Hornet\n4 Drive" 6.00 110
5 "Hornet\nSportabout" 8.00 175
ht <- as_hux(cars, add_colnames = TRUE)
escape_contents(ht) <- TRUE
ht但这最终没有中断行,如下面的截图所示。

escape_contents部分似乎没有什么不同。
我不确定我想要的是否可能,但我知道它在其他包中(例如,DT::datatable)。不过,如果可能的话,我很想使用huxtable,因为我喜欢这个包的设计和灵活性。
任何想法都会很好。
编辑:--我应该指定--我希望能让它适用于PDF。
回答 3
Stack Overflow用户
发布于 2018-03-21 06:48:31
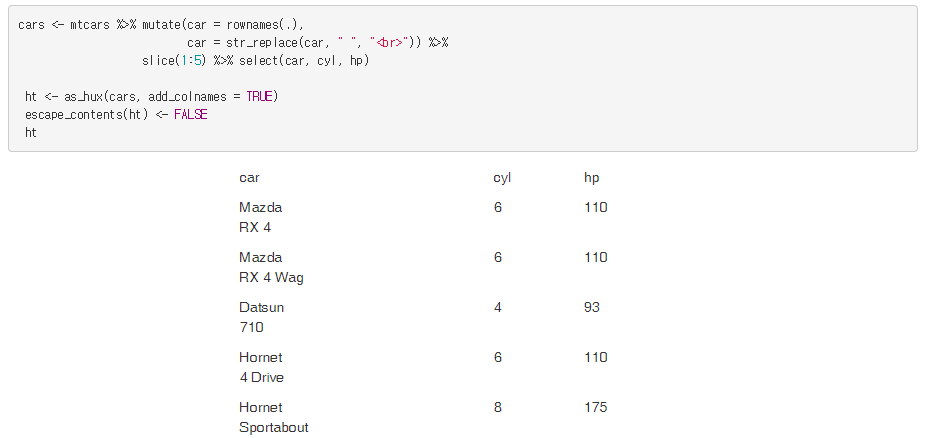
根据转义HTML或LaTeX,您应该使用escape_contents(ht) <- FALSE,使用<br>标记而不是\n
library(tidyverse)
library(huxtable)
cars <- mtcars %>% mutate(car = rownames(.),
car = str_replace(car, " ", "<br>")) %>%
slice(1:5) %>% select(car, cyl, hp)
ht <- as_hux(cars, add_colnames = TRUE)
escape_contents(ht) <- FALSE
ht请注意,输出是一个Rmarkdown文档,谢谢您提供的包信息。看上去不错。以下是我的产量
Stack Overflow用户
发布于 2019-09-04 21:24:19
试试这个,它可以最小化反斜杠的数量:
library(tidyverse)
library(huxtable)
cars <- mtcars %>% mutate(car = rownames(.))
cars$car <- str_replace(cars$car, " ", "\\\\newline ")
cars %>%
as_hux(add_colnames = TRUE) %>%
set_wrap(TRUE) %>%
set_escape_contents(everywhere, "car", FALSE) %>%
quick_pdf()
我认为,set_wrap()调用对于LaTeX表接受换行符是必要的。
如果您想要转义包含换行符的单元格的不同部分,您可以手动地这样做,例如使用xtable::sanitize()。
Stack Overflow用户
发布于 2019-09-03 19:22:49
好吧,结合这个LaTeX StackExchange帖子和这个经典的XKCD的观点,我得到了以下信息:
library(tidyverse)
library(huxtable)
cars <- mtcars %>%
mutate(car = rownames(.),
car = str_replace(car, "(\\S*)\\s(.*)",
"\\\\vtop{\\\\hbox{\\\\strut \\1}\\\\hbox{\\\\strut \\2}}")) %>%
slice(1:5) %>%
select(car, cyl, hp)
ht <- as_hux(cars, add_colnames = TRUE) %>%
set_escape_contents(1:6, 1, FALSE)
theme_article(ht)它提供了以下PDF输出:

当然,如果您使用手工构建自己的单元而不是使用str_replace,那么您将不需要太多的转义。请注意,对于带换行的单元格,将set_escape_contents设置为FALSE是至关重要的。
https://stackoverflow.com/questions/49398097
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号