
R:如何绘制在示例列表中出现的字符串项的百分比?
我有一个CSV文件,其中包含许多示例,本质上是3列(人名、文件名和有序项列表)。我想要绘制项目的出现时间,所以y是所有可能的标签(6个项目,或'A','S','P','X','N','R')和x是每个标签在那个地方的百分比。因此,x=1有6个数据点,表示这些项目在列表中第一位的次数,x=2是项目在列表中第二位的次数,x=3是第三位出现的次数,等等,对于前5-6项,这些项目将是一行。
输入数据:
Participant,ImageName,GazeOrder,,,,,,,,,,,,,,,,,,,,,,,,,,
Person1, fiveobjectsrandom3.jpg, A, A, S, S, P, X, N, N, R,,,,,,,,,,,,,,,,,,
Person2, fiveobjectsrandom2.jpg, S, S, S, S, R, R, P, R,,,,,,,,,,,,,,,,,,,
Person3, fiveobjectsrandom4.jpg, N, N, S, S, R, R, R, A, P, P, 行的长度并不完全相同(有时列表提前结束,有时完全为空)
当我将其导入R中时,它将给出前3列,并将其命名为其余的X、X.1、X.2等,这很好。我知道我可以用摘要(Imported_frame)抓取摘要,如果我知道如何获取它们来绘制图表,那么该表包含我想要的计数,但我不知道如何--例如。
gsum <- summary(gaze_order)
Participant ImageName GazeOrder
Person1 : 5 fiveobjectsrandom0.jpg:47 A :35
Person2 : 5 fiveobjectsrandom1.jpg:47 X :66
Person3 : 5 fiveobjectsrandom2.jpg:47 N :33
Person4 : 5 fiveobjectsrandom3.jpg:47 P :25
Person5 : 5 fiveobjectsrandom4.jpg:47 S :57
Person6 : 5 R :10
(Other) :205 NA's : 9
X X.1 X.2 X.3
A :28 A :24 A :25 A :29
X :49 X :36 X :25 X :20
N :44 N :48 N :54 N :61
P :32 P :35 P :40 P :31
S :57 S :61 S :58 S :52
R :16 R :19 R :19 R :15
NA's: 9 NA's :12 NA's :14 ..........我还可以获得整个列表的位置1与imported_frame$GazeOrder,2与imported_frame$X,3与imported_frame$X.1,等等。
这也是我所需要的--它比我所需要的要复杂得多,而且我不知道如何解释它的内部工作原理;当我开始根据我自己的数据修改它时,我得到了“错误:当我处理‘概括’时,不应该直接调用这个函数,例如
rm(list = ls())
library(tidyverse)
# read child score data
gaze_order <- read.csv(file="~/Dropbox/Eye tracking analysis/TOBII data/item_gazes_5Pictures.csv", header=TRUE, sep = ",", na.strings=c("", "NA"))
gaze_labels <- c("A", "X", "S", "N", "R", "P")
ggplot(data = gaze_order, mapping = aes(x = gaze_order$GazeOrder, y = gaze_labels)) +
geom_point()
ggplot(gaze_order, summarise(Pl = sum(grepl("P", gaze_order$GazeOrder))/n(),
Na = sum(grepl("N", gaze_order$GazeOrder))/n(),
Ba = sum(grepl("X", gaze_order$GazeOrder))/n(),
So = sum(grepl("S", gaze_order$GazeOrder))/n(),
Ai = sum(grepl("A", gaze_order$GazeOrder))/n(),
Sp = sum(grepl("S", gaze_order$GazeOrder))/n()))所需的输出数据如下所示,https://i.stack.imgur.com/cdJTF.png
{kind=link}
而不是简,二月,玛.它只是1,2,3,4,5.,而不是A,B,而是可能的6个标签,'A','S','P','X','N','R‘。
有什么想法?我也一直在玩grepl来计算所有列表中的所有项目,但是它最终变得难以置信的笨重,我相信我使用它是错误的。
回答 1
Stack Overflow用户
发布于 2018-03-06 22:45:57
要获得您想要的绘图,有两个步骤:生成正确的计数,然后生成实际的绘图。summary可以提供计数,但它更适合交互式使用,我们更愿意将它放在表中。
- 第一步是读取数据。您可以忽略这里的警告,我们只是没有列名。
- 那我们就得弄清楚我们的数目。使用
gather将所有列收集到一个变量中,这样更容易绘制。这就是所谓的整洁数据。然后,我们使用两个mutate调用从生成的列名中提取实际的凝视顺序。我们使用count按凝视顺序和字母获得计数,然后使用complete为字母和凝视顺序的组合填充零,因为它们丢失了。
编辑:在gather上展开。从文档中看:gather有如下参数:gather(data, key = "key", value = "value", ..., na.rm = FALSE, [some more])。data是通过管道向前传递的tbl。
key = "colname"是要保存新行(即列名)标识符的列的名称。value = "letter"是要保存新行(即字母)值的列的名称。... = -Participant, -ImageName是我们要收集的列的选择,即名称为凝视顺序,值为字母的列。选择它们的最简单方法是选择除Participant和ImageName之外的所有。有关变量选择的更多理解,请参见?dplyr::select。na.rm = TRUE只是删除了我们不需要的所有缺失的值。
我建议查看本章以获得更多信息,并尝试更改参数以了解不同的情况。
- 最后,我们可以绘制正确的图表。我们将
gaze_order分配给x美学,n分配给y,因为这些是我们在每个轴上想要的变量。重要的是,我们可以根据需要使用colour为每个字母绘制一个单独的行。剩下的只是调整标签和轴断裂。
library(tidyverse)
tbl <- read_csv(
"Participant,ImageName,GazeOrder,,,,,,,,,,,,,,,,,,,,,,,,,,
Person1, fiveobjectsrandom3.jpg, A, A, S, S, P, X, N, N, R,,,,,,,,,,,,,,,,,,
Person2, fiveobjectsrandom2.jpg, S, S, S, S, R, R, P, R,,,,,,,,,,,,,,,,,,,
Person3, fiveobjectsrandom4.jpg, N, N, S, S, R, R, R, A, P, P, "
)
#> Warning: Missing column names filled in: 'X4' [4], 'X5' [5], 'X6' [6],
#> 'X7' [7], 'X8' [8], 'X9' [9], 'X10' [10], 'X11' [11], 'X12' [12],
#> 'X13' [13], 'X14' [14], 'X15' [15], 'X16' [16], 'X17' [17], 'X18' [18],
#> 'X19' [19], 'X20' [20], 'X21' [21], 'X22' [22], 'X23' [23], 'X24' [24],
#> 'X25' [25], 'X26' [26], 'X27' [27], 'X28' [28], 'X29' [29]
#> Warning in rbind(names(probs), probs_f): number of columns of result is not
#> a multiple of vector length (arg 2)
#> Warning: 1 parsing failure.
#> row # A tibble: 1 x 5 col row col expected actual file expected <int> <chr> <chr> <chr> <chr> actual 1 3 <NA> 29 columns 13 columns literal data file # A tibble: 1 x 5
tidy_tbl <- tbl %>%
gather("colname", "letter", -Participant, -ImageName, na.rm = TRUE) %>%
mutate(
colname = ifelse(colname == "GazeOrder", "X3", colname),
gaze_order = as.integer(str_sub(colname, 2, -1)) - 2
) %>%
count(gaze_order, letter) %>%
complete(gaze_order, letter, fill = list(n = 0))
ggplot(tidy_tbl) +
geom_line(aes(x = gaze_order, y = n, colour = letter)) +
scale_x_continuous(breaks = 1:10) +
scale_colour_discrete(name = "Letter") +
labs(
x = "Gaze Order",
y = "Count",
title = "Count of letters by gaze order"
)
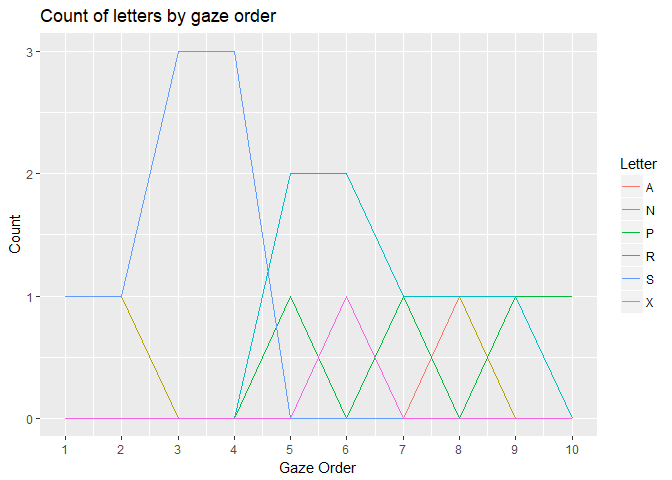
由reprex封装创建于2018-03-06 (v0.2.0)。
https://stackoverflow.com/questions/49140063
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号