
如何解释锯齿形训练的损失?
如何解释锯齿形训练的损失?
提问于 2018-03-04 07:48:11
我的训练数据包括大约700个独特的样本(这是一个回归问题)。数据不被洗牌,所以第一个N个样本有相同的标签(例如,值1.25),然后下一个M样本有一个相同的标签(例如,2.99)等等。总共大约有15个唯一的标签。
我使用一个简单的CNN,因为输入是一个图像(64x64x3)。即使没有辍学或其他形式的正规化,我也无法使训练损失稳定在接近于零的水平。
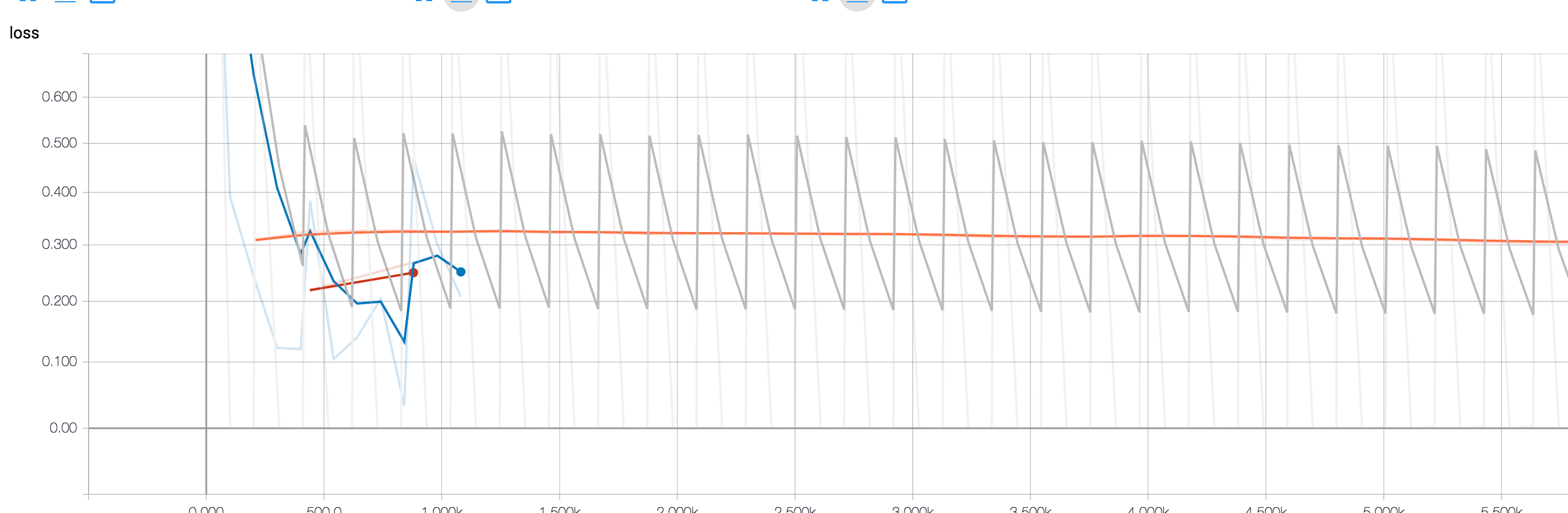
这种学习缺失的模式是什么?(灰色线是训练损失,橙色线是验证损失)。
回答 2
Stack Overflow用户
发布于 2018-03-04 12:34:19
从这种模式中你能得到的唯一指示就是学习率太高,你应该降低它,直到损失开始减少为止。
Stack Overflow用户
发布于 2018-10-03 11:21:58
似乎你的学习速度太大,使你的参数剧烈波动。
我当时建议的事情是:
- 降低初始学习率
- 尝试另一个具有某种学习速率衰减的优化器(例如,在这种情况下对我有用的亚当)。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/49093182
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号