
神经网络:神秘ReLu
我一直在构建一个编程语言检测器,即一个代码片段分类器,作为一个更大项目的一部分。我的基线模型非常直截了当:将输入标记化,并将代码段编码为单词袋,或者,在本例中,将标记包编码,并在这些特性的基础上构建一个简单的NN。

神经网络的输入是一个固定长度的计数器数组,这些计数器由最特殊的标记组成,如"def"、"self"、"function"、"->"、"const"、"#include"等,这些计数器都是从语料库中自动提取出来的。其思想是,这些标记对于编程语言来说是非常独特的,因此即使这种天真的方法也应该获得高精度的分数。
Input:
def 1
for 2
in 2
True 1
): 3
,: 1
...
Output: python设置
我得到了99%的准确性很快,并决定这是一个迹象,它的工作,正如预期。下面是模型(完整的运行脚本是这里):
# Placeholders
x = tf.placeholder(shape=[None, vocab_size], dtype=tf.float32, name='x')
y = tf.placeholder(shape=[None], dtype=tf.int32, name='y')
training = tf.placeholder_with_default(False, shape=[], name='training')
# One hidden layer with dropout
reg = tf.contrib.layers.l2_regularizer(0.01)
hidden1 = tf.layers.dense(x, units=96, kernel_regularizer=reg,
activation=tf.nn.elu, name='hidden1')
dropout1 = tf.layers.dropout(hidden1, rate=0.2, training=training, name='dropout1')
# Output layer
logits = tf.layers.dense(dropout1, units=classes, kernel_regularizer=reg,
activation=tf.nn.relu, name='logits')
# Cross-entropy loss
loss = tf.reduce_mean(
tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, abels=y))
# Misc reports: accuracy, correct/misclassified samples, etc.
correct_predicted = tf.nn.in_top_k(logits, y, 1, name='in-top-k')
prediction = tf.argmax(logits, axis=1)
wrong_predicted = tf.logical_not(correct_predicted, name='not-in-top-k')
x_misclassified = tf.boolean_mask(x, wrong_predicted, name='misclassified')
accuracy = tf.reduce_mean(tf.cast(correct_predicted, tf.float32), name='accuracy')产出是相当令人鼓舞的:
iteration=5 loss=2.580 train-acc=0.34277
iteration=10 loss=2.029 train-acc=0.69434
iteration=15 loss=2.054 train-acc=0.92383
iteration=20 loss=1.934 train-acc=0.98926
iteration=25 loss=1.942 train-acc=0.99609
Files.VAL mean accuracy = 0.99121 <-- After just 1 epoch!
iteration=30 loss=1.943 train-acc=0.99414
iteration=35 loss=1.947 train-acc=0.99512
iteration=40 loss=1.946 train-acc=0.99707
iteration=45 loss=1.946 train-acc=0.99609
iteration=50 loss=1.944 train-acc=0.99902
iteration=55 loss=1.946 train-acc=0.99902
Files.VAL mean accuracy = 0.99414测试精度也在1.0左右。一切看起来都很完美。
神秘的ReLu
但随后我注意到,我将activation=tf.nn.relu放入最后的密集层(logits),这显然是一个bug:没有必要在softmax之前放弃负值,因为它们表明类的概率很低。零阈值只会使这些类人为地更有可能发生,这将是一个错误。摆脱它只会使模型在正确的类中更加健壮和自信。
我也是这么认为。所以我用activation=None替换了它,再次运行模型,然后发生了一件令人惊讶的事情:性能没有提高。完全没有。事实上,it 显着地降低了。
iteration=5 loss=5.236 train-acc=0.16602
iteration=10 loss=4.068 train-acc=0.18750
iteration=15 loss=3.110 train-acc=0.37402
iteration=20 loss=5.149 train-acc=0.14844
iteration=25 loss=2.880 train-acc=0.18262
Files.VAL mean accuracy = 0.28711
iteration=30 loss=3.136 train-acc=0.25781
iteration=35 loss=2.916 train-acc=0.22852
iteration=40 loss=2.156 train-acc=0.39062
iteration=45 loss=1.777 train-acc=0.45312
iteration=50 loss=2.726 train-acc=0.33105
Files.VAL mean accuracy = 0.29362训练的准确率较高,但未超过91-92%。我多次改变激活,改变不同的参数(层的大小,脱落,正则化,额外的层,任何东西)并且总是有相同的结果:“错误”模型立即达到99%,而“正确”模型在50次之后几乎没有达到90%。根据拉伸板,重量分布没有太大的差异:梯度并没有消失,两种模型都正常学习。
这怎麽可能?最终的ReLu怎么能使一个模型如此优越呢?尤其是如果这个ReLu是个bug呢?
回答 1
Stack Overflow用户
发布于 2018-02-26 16:35:57
预测分布
在玩了一段时间之后,我决定可视化这两个模型的实际预测分布:
predicted_distribution = tf.nn.softmax(logits, name='distribution')下面是这些分布的柱状图,以及它们是如何随时间演变的。
与ReLu (错误模型)
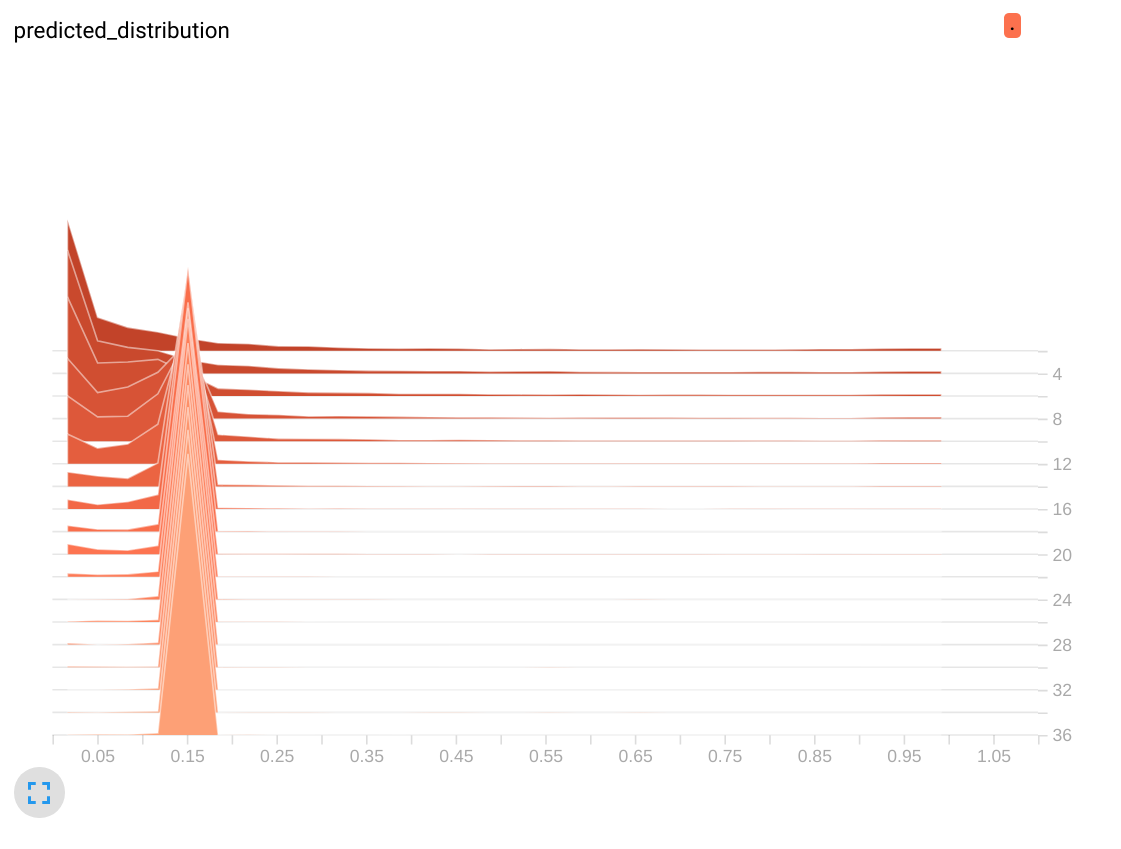
无ReLu (正确模型)
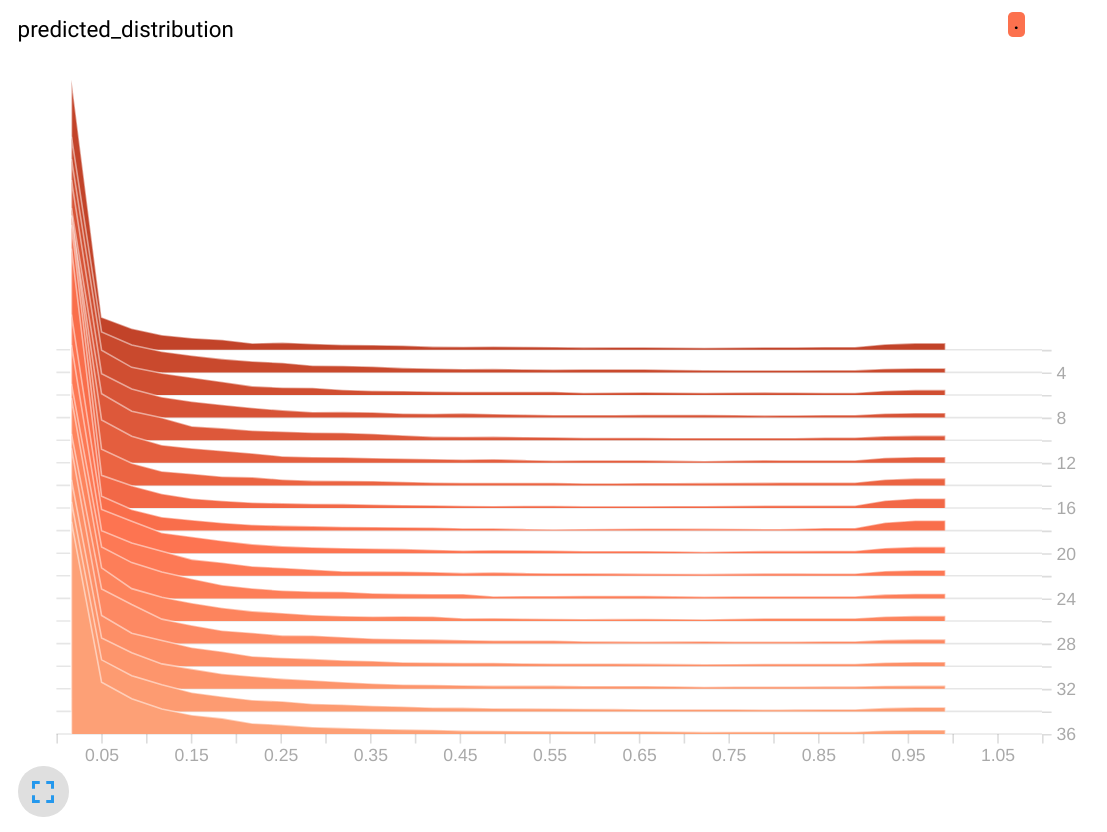
第一个直方图是有意义的,大多数概率接近0。但是ReLu模型的直方图是可疑:经过几次迭代后,这些值似乎集中在0.15上。打印实际预测证实了这一观点:
[0.14286 0.14286 0.14286 0.14286 0.14286 0.14286 0.14286]
[0.14286 0.14286 0.14286 0.14286 0.14286 0.14286 0.14286]当时我有7个类(针对7种不同的语言),0.14286是1/7。事实证明,“完美”模型学会了输出0逻辑,这反过来又转化为统一预测。
但是,如何报告这一分布为99%的准确性呢?
tf.nn.in_top_k
在深入研究tf.nn.in_top_k之前,我检查了另一种计算精度的方法:
true_correct = tf.equal(tf.argmax(logits, 1), tf.cast(y, tf.int64))
alternative_accuracy = tf.reduce_mean(tf.cast(true_correct, tf.float32))..。对最高的预测等级和地面真理进行诚实的比较。其结果是:
iteration=2 loss=3.992 train-acc=0.13086 train-alt-acc=0.13086
iteration=4 loss=3.590 train-acc=0.13086 train-alt-acc=0.12207
iteration=6 loss=2.871 train-acc=0.21777 train-alt-acc=0.13672
iteration=8 loss=2.466 train-acc=0.37695 train-alt-acc=0.16211
iteration=10 loss=2.099 train-acc=0.62305 train-alt-acc=0.10742
iteration=12 loss=2.066 train-acc=0.79980 train-alt-acc=0.17090
iteration=14 loss=2.016 train-acc=0.84277 train-alt-acc=0.17285
iteration=16 loss=1.954 train-acc=0.91309 train-alt-acc=0.13574
iteration=18 loss=1.956 train-acc=0.95508 train-alt-acc=0.06445
iteration=20 loss=1.923 train-acc=0.97754 train-alt-acc=0.11328事实上,tf.nn.in_top_k与k=1的准确性很快偏离了正确的准确性,并开始报告99%的幻想值。那么它实际上是做什么的呢?以下是文献资料对此的看法:
说明目标是否在K值最高的预测中。 这输出了一个
batch_sizebool数组,如果对目标类的预测是所有预测中的顶级k预测之一,则条目out[i]为真。注意,InTopK的行为与TopKop在处理领带方面的行为不同;如果多个类具有相同的预测值,并且跨越顶k边界,则所有这些类都被认为在顶层k中。
就是这样。如果概率是一致的(这实际上意味着“我不知道”),那么它们都是正确的。情况甚至更糟,因为如果逻辑分布几乎是均匀的,softmax可能会将其转换为完全均匀的分布,在这个简单的例子中可以看到:
x = tf.constant([0, 1e-8, 1e-8, 1e-9])
tf.nn.softmax(x).eval()
# >>> array([0.25, 0.25, 0.25, 0.25], dtype=float32)..。这意味着,根据tf.nn.in_top_k规范,每一个几乎一致的预测都可以被认为是“正确的”。
结论
在tensorflow中,tf.nn.in_top_k是一个危险的准确性度量方法,因为它可能会默默地吞下错误的预测,并将其报告为“正确”。相反,您应该始终使用这个长而可信的表达式:
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(logits, 1), tf.cast(y, tf.int64)), tf.float32))https://stackoverflow.com/questions/48993004
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号