
R中数值级数中瞬态渐近动力学的求法
R中数值级数中瞬态渐近动力学的求法
提问于 2018-02-21 00:16:25
以下是我在研究中向前迈进的关键。
我试图找到一种方法来计算大型数据集的瞬态和渐近线动态的持续时间。这里有一个简短的例子,说明我的数据是什么样的。
x <- c(6,3,8,9,4,3,2,9,8,6,7,1, 2, 3, 2, 1, 1, 2, 1, 1, 2, 3, 2, 1, 1, 2, 1,1, 2, 3, 2, 1, 1, 2, 1,1, 2, 3, 2, 1, 1, 2, 1, 1, 2, 3, 2, 1, 1, 2, 1, 1, 2, 3, 2, 1, 1, 2, 1,1, 2, 3, 2, 1, 1, 2, 1,1, 2, 3, 2, 1, 1, 2, 1,1, 2, 3, 2, 1, 1, 2, 1, 1, 2, 3, 2, 1, 1, 2, 1,1, 2, 3, 2, 1, 1, 2, 1,1, 2, 3, 2, 1, 1, 2, 1, 1, 2, 3, 2, 1, 1, 2, 1, 1, 2, 3, 2, 1, 1, 2, 1,1, 2, 3, 2, 1, 1, 2, 1,1, 2, 3, 2, 1, 1, 2, 1,1)
plot(x, type="l")
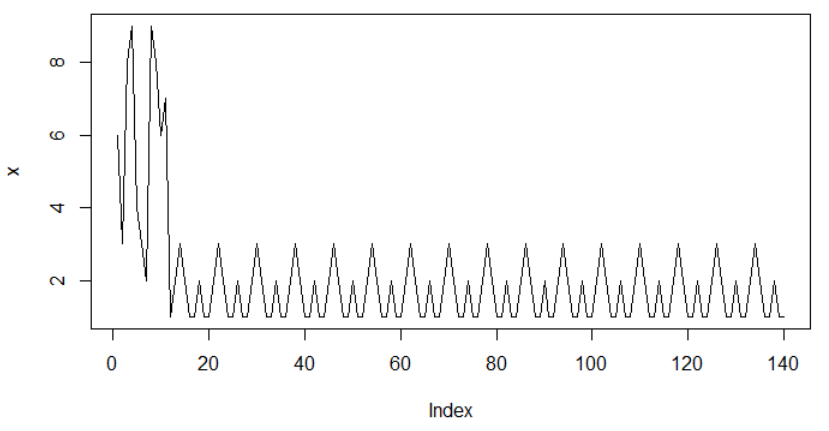
我看了一下一阶和二阶导数,但没有按我的意愿工作。
任何帮助都是非常感谢的。
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-02-21 00:53:57
如果我正确理解,您可以探索一个变点分析。
有一个名为changepoint的R包,它实现了各种转换点搜索方法,详细信息可以在原版出版物中找到。
下面是一个使用示例数据的示例。
library(changepoint);
ret <- cpt.mean(x, class = FALSE);
ret;
#cpt conf.value
#11.0000000 0.9406066在输出中,cpt是转换点最可能的位置。如果你放大情节,你会发现这似乎是明智的。
plot(x, type="l", xlim = c(0, 20));
abline(v = ret[1], col = "red")
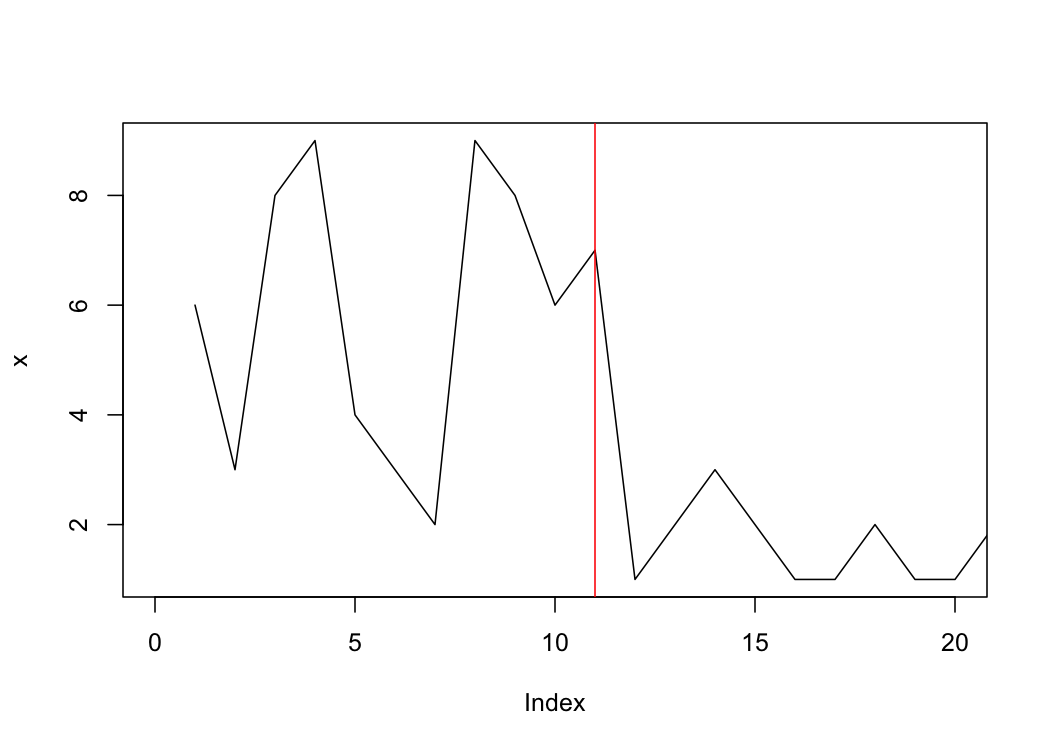
显然,您需要更仔细地查看一些“调优”参数。?cpt.mean和论文将是一个很好的起点。
然后,您可以将事件x < cpt归类为瞬态事件,将x > cpt分类为渐近事件;但是,这当然取决于您的数据的上下文/来源,而我不知道这一点。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/48896326
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号