
当内存达到88%时服务器崩溃
我在一个8GB内存/ 80 GB磁盘/Ubuntu16.04.3 x64 /4 vCPU的数字海洋液滴中使用带有角向通用的服务器端渲染,并使用PM2作为进程管理器。
我使用一个6GB交换文件,当“空闲-m”时可用内存如下所示:
total used free shared buff/cache available
Mem: 7983 1356 5290 16 1335 6278
Swap: 6143 88 6055拉姆用看起来很好。PM2的集群模式有4个进程。
每6-8小时,当我的数字海洋面板的内存达到88%时,CPU就会非常高,web应用程序没有正确的响应,并且PM2不得不重新启动进程,无法确定web应用程序有多长时间不能正常工作。
下面是所发生的事情的图像:
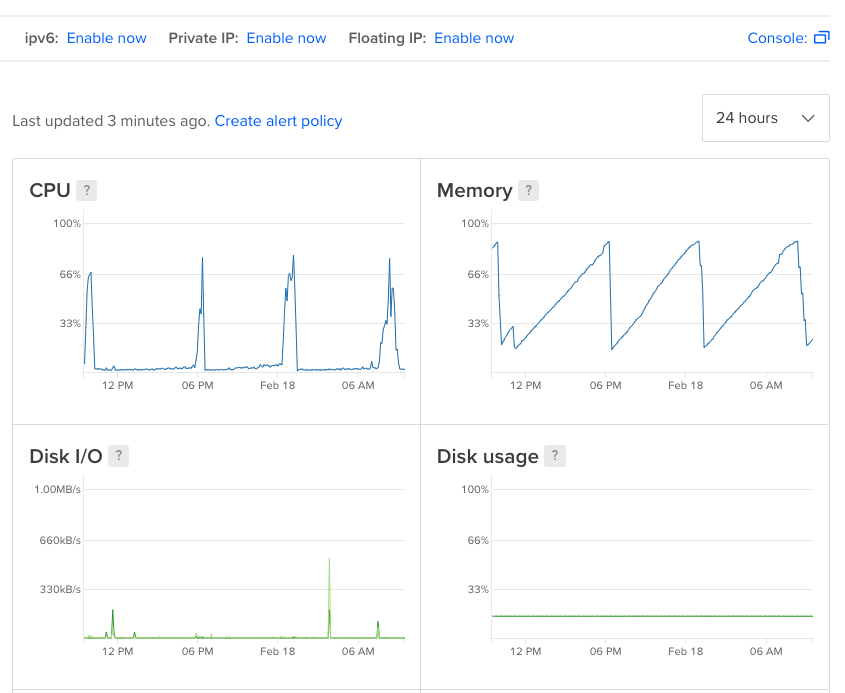
正常工作时,性能良好:
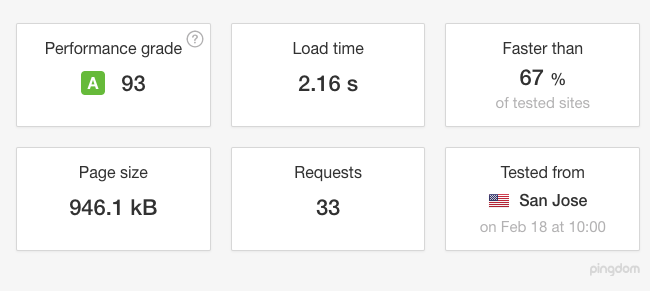
我想我错过了某种配置什么的,因为这种情况总是在同一时间发生。
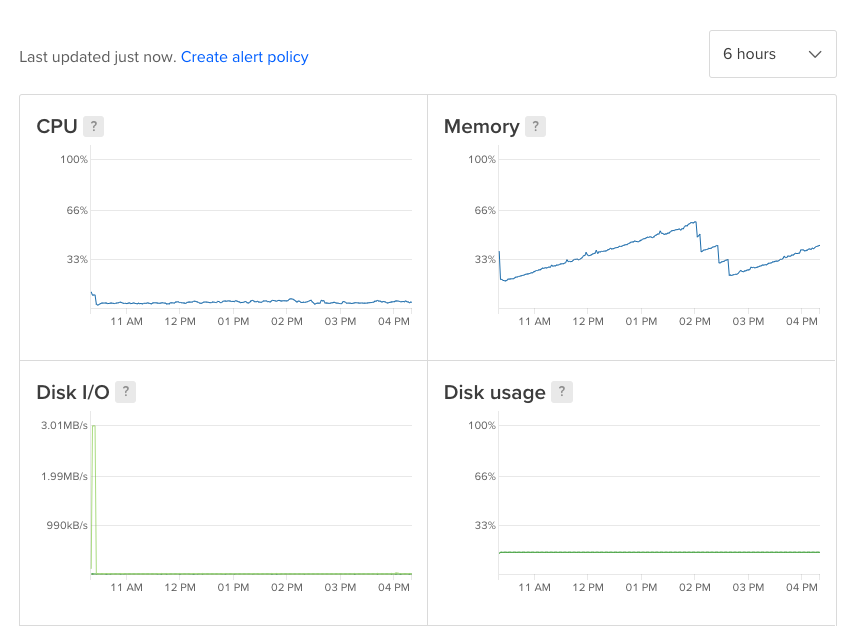
到目前为止,EDIT1在我的代码中修复了一些不兼容的地方(应用程序正在工作,但有时会因为这个问题而失败),并添加了1GB的pm2中的内存限制。我不确定这是不是该走的路,因为我对进程管理还有点陌生,但是CPU级别现在还不错。如有任何意见,敬请见谅。我留下了当前行为的图片,每当四个进程中的一个达到1GB时,它就会重新启动:
EDIT2 I再添加3幅图像,其中2幅显示来自数字海洋的顶级进程,另一幅显示关键度量状态:
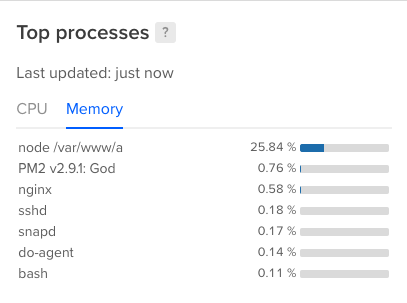
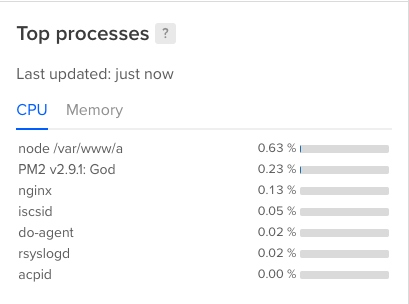
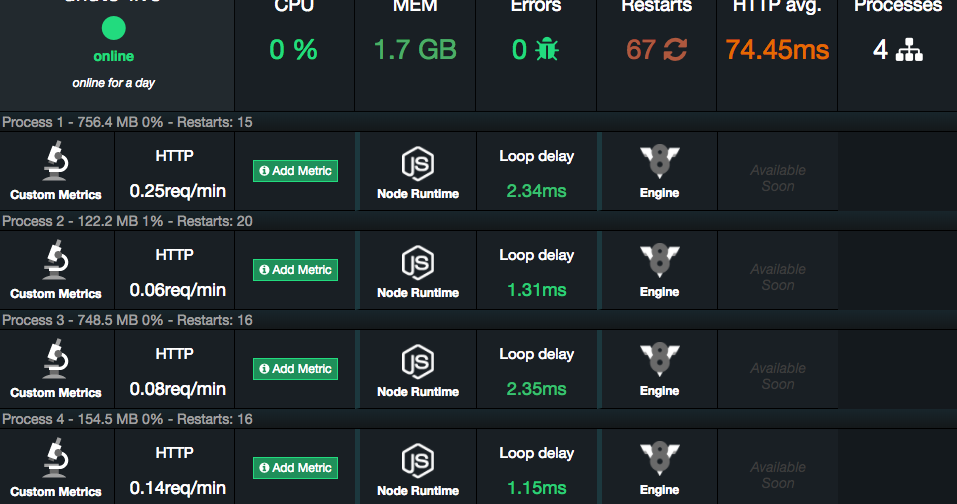
EDIT3我发现了一些内存泄漏从我的角度应用程序(我忘记取消订阅从几个订阅)和系统行为改善,但内存线仍在上升。我将继续研究内存漏入角的情况,看看是否犯了其他错误:
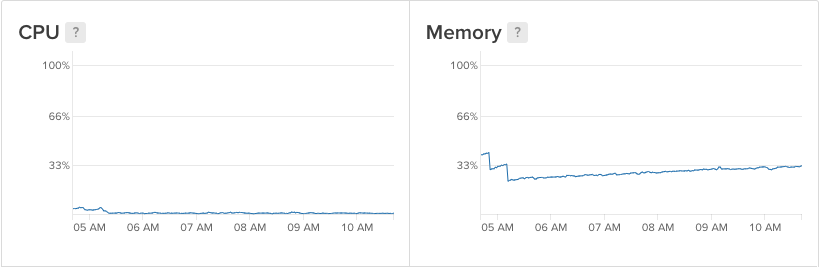
回答 2
Stack Overflow用户
发布于 2018-02-26 00:37:47
看起来你的角度环球应用程序正在漏掉内存,它不应该随着时间的推移而增加,因为你观察到了,但基本上保持平稳。
您可以尝试查找内存泄漏(看起来您已经发现了一个问题,并且怀疑它还可能是什么)。
您可以尝试的另一件事是定期重新启动应用程序。例如,请参见这里,如何每隔几个小时重新启动pm2进程,以重置并防止您遇到的OOM情况。
Stack Overflow用户
发布于 2021-04-21 10:26:31
在我们的(边缘)案例中,kubernetes的健康检查是问题的原因。健康检查通过内部IP访问主页。页面使用调用者URL (在本例中是它的IP)来加载一些它无法找到的资源。这会导致错误,并以某种方式缓存并慢慢耗尽所有内存。由于健康检查的规律,即使在晚上,我们的记忆力也有同样的线性上升。
我们通过让健康检查调用"/health“来解决这个问题,其中我们只返回了200个代码。不管怎么说都应该这么做。
https://stackoverflow.com/questions/48849995
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号