
协同过滤-R
我需要得到前5名电影推荐维多利亚,使用加权平均数的每一个其他评论家的排名。我只能在Excel中完成这项工作,但我需要将其转换为R。求值的公式是:
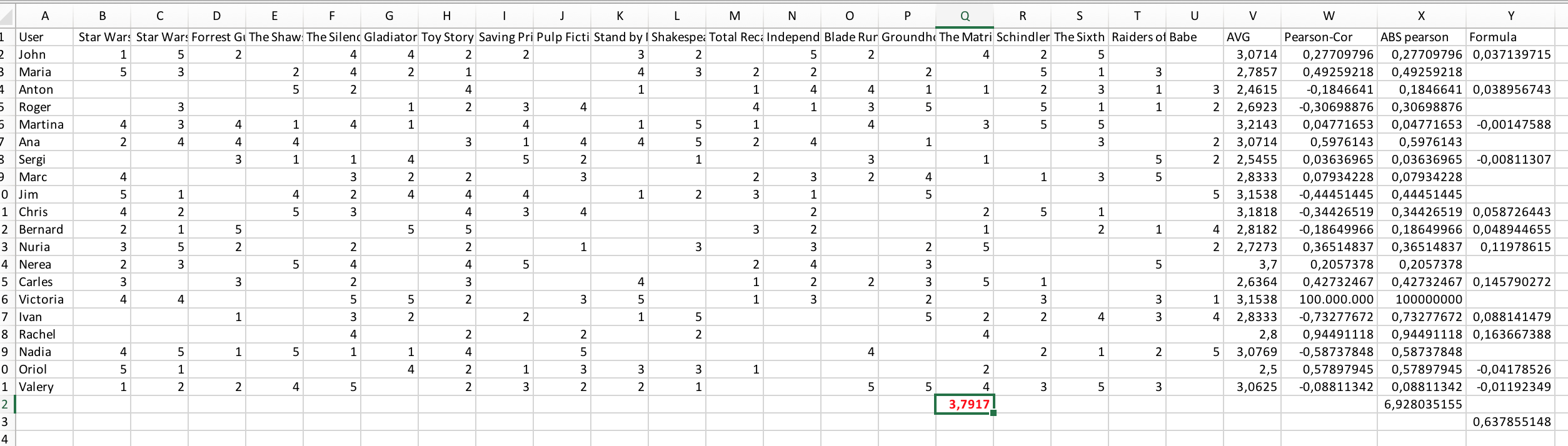
维多利亚平均+(Σ(其他评论家等级-其他评论家平均等级)* pearson相关)/Σ绝对加权皮尔森值-1(即维多利亚的)
为了更好地说明电影The.Matrix,下面的结果应该是
约翰投票=4
约翰平均数=3 0714
John pearson cor = 0,27709796
公式= (4-3,07) * 0,27709796 / 6,9280 ( abs加权值之和)
(我如何在R?中创建这个公式?)如果我能解决这个问题,也许我可以做剩下的
在为每个人做这件事之后,你添加了3,1538 (维多利亚的雅芳),它将产生3,791701302
我需要为所有维多利亚时代没有看过的电影做这件事,这应该是结果
3.7917013044215, 'The Matrix'
3.50776533175371, 'Forrest Gump'
3.33118834864677, 'The Sixth Sense'
3.11491825315719, 'Shakespeare in Love'
2.9124513228665, 'Blade Runner'下面是Excel上的矩阵版本:
到目前为止这是我的代码:
cr2<-t(cr[,2:21])
colnames(cr2)<-cr[,1]
cr2<-as.data.frame(cr2)
cr$Mean <- rowMeans(cr[,2:20], na.rm = TRUE)
cr$Pearson <- cor(cr2[,1:20], cr2[15], use = "pairwise.complete.obs")
cr$PearsonABS <- abs(cor(cr2[,1:20], cr2[15], use = "pairwise.complete.obs"))
x <- sum(cr$PearsonABS) - 1我用非常糟糕的方式(手动)做了这件事。
g <- cr[15,22]
#Forrest Gump
fg = cr[,4] - cr[, 22]
fga = fg * cr[,23]
fgb = fga / x
fgc = sum(fgb, na.rm = TRUE) + g
print(fgc)
#The Shawshank Redemption
sr = cr[,5] - cr[, 22]
sra = sr * cr[,23]
srb = sra / x
src = sum(srb, na.rm = TRUE) + g
print(src)
#Saving Private Ryan
sp = cr[,9] - cr[, 22]
spa = sp * cr[,23]
spb = spa / x
spc = sum(spb, na.rm = TRUE) + g
print(spc)
#Shakespeare in Love
sl = cr[,12] - cr[, 22]
sla = sl * cr[,23]
slb = sla / x
slc = sum(slb, na.rm = TRUE) + g
print(slc)
#Blade Runner
br = cr[,15] - cr[, 22]
bra = br * cr[,23]
brb = bra / x
brc = sum(brb, na.rm = TRUE) + g
print(brc)
#The Matrix
tm = cr[,17] - cr[, 22]
tma = tm * cr[,23]
tmb = tma / x
tmc = sum(tmb, na.rm = TRUE) + g
print(tmc)
#The Sixth Sense
ts = cr[,19] - cr[, 22]
tsa = ts * cr[,23]
tsb = tsa / x
tsc = sum(tsb, na.rm = TRUE) + g
print(tsc)
my_list <- c(fgc, src, spc, slc, brc, tmc, tsc)
head(sort(my_list, decreasing=TRUE), 5)这是dput()
dput(cr)
structure(list(User = structure(c(8L, 10L, 2L, 17L, 11L, 1L,
18L, 9L, 7L, 5L, 3L, 14L, 13L, 4L, 20L, 6L, 16L, 12L, 15L, 19L
), .Label = c("Ana", "Anton", "Bernard", "Carles", "Chris", "Ivan",
"Jim", "John", "Marc", "Maria", "Martina", "Nadia", "Nerea",
"Nuria", "Oriol", "Rachel", "Roger", "Sergi", "Valery", "Victoria"
), class = "factor"), Star.Wars.IV...A.New.Hope = c(1L, 5L, NA,
NA, 4L, 2L, NA, 4L, 5L, 4L, 2L, 3L, 2L, 3L, 4L, NA, NA, 4L, 5L,
1L), Star.Wars.VI...Return.of.the.Jedi = c(5L, 3L, NA, 3L, 3L,
4L, NA, NA, 1L, 2L, 1L, 5L, 3L, NA, 4L, NA, NA, 5L, 1L, 2L),
Forrest.Gump = c(2L, NA, NA, NA, 4L, 4L, 3L, NA, NA, NA,
5L, 2L, NA, 3L, NA, 1L, NA, 1L, NA, 2L), The.Shawshank.Redemption = c(NA,
2L, 5L, NA, 1L, 4L, 1L, NA, 4L, 5L, NA, NA, 5L, NA, NA, NA,
NA, 5L, NA, 4L), The.Silence.of.the.Lambs = c(4L, 4L, 2L,
NA, 4L, NA, 1L, 3L, 2L, 3L, NA, 2L, 4L, 2L, 5L, 3L, 4L, 1L,
NA, 5L), Gladiator = c(4L, 2L, NA, 1L, 1L, NA, 4L, 2L, 4L,
NA, 5L, NA, NA, NA, 5L, 2L, NA, 1L, 4L, NA), Toy.Story = c(2L,
1L, 4L, 2L, NA, 3L, NA, 2L, 4L, 4L, 5L, 2L, 4L, 3L, 2L, NA,
2L, 4L, 2L, 2L), Saving.Private.Ryan = c(2L, NA, NA, 3L,
4L, 1L, 5L, NA, 4L, 3L, NA, NA, 5L, NA, NA, 2L, NA, NA, 1L,
3L), Pulp.Fiction = c(NA, NA, NA, 4L, NA, 4L, 2L, 3L, NA,
4L, NA, 1L, NA, NA, 3L, NA, 2L, 5L, 3L, 2L), Stand.by.Me = c(3L,
4L, 1L, NA, 1L, 4L, NA, NA, 1L, NA, NA, NA, NA, 4L, 5L, 1L,
NA, NA, 3L, 2L), Shakespeare.in.Love = c(2L, 3L, NA, NA,
5L, 5L, 1L, NA, 2L, NA, NA, 3L, NA, NA, NA, 5L, 2L, NA, 3L,
1L), Total.Recall = c(NA, 2L, 1L, 4L, 1L, 2L, NA, 2L, 3L,
NA, 3L, NA, 2L, 1L, 1L, NA, NA, NA, 1L, NA), Independence.Day = c(5L,
2L, 4L, 1L, NA, 4L, NA, 3L, 1L, 2L, 2L, 3L, 4L, 2L, 3L, NA,
NA, NA, NA, NA), Blade.Runner = c(2L, NA, 4L, 3L, 4L, NA,
3L, 2L, NA, NA, NA, NA, NA, 2L, NA, NA, NA, 4L, NA, 5L),
Groundhog.Day = c(NA, 2L, 1L, 5L, NA, 1L, NA, 4L, 5L, NA,
NA, 2L, 3L, 3L, 2L, 5L, NA, NA, NA, 5L), The.Matrix = c(4L,
NA, 1L, NA, 3L, NA, 1L, NA, NA, 2L, 1L, 5L, NA, 5L, NA, 2L,
4L, NA, 2L, 4L), Schindler.s.List = c(2L, 5L, 2L, 5L, 5L,
NA, NA, 1L, NA, 5L, NA, NA, NA, 1L, 3L, 2L, NA, 2L, NA, 3L
), The.Sixth.Sense = c(5L, 1L, 3L, 1L, 5L, 3L, NA, 3L, NA,
1L, 2L, NA, NA, NA, NA, 4L, NA, 1L, NA, 5L), Raiders.of.the.Lost.Ark = c(NA,
3L, 1L, 1L, NA, NA, 5L, 5L, NA, NA, 1L, NA, 5L, NA, 3L, 3L,
NA, 2L, NA, 3L), Babe = c(NA, NA, 3L, 2L, NA, 2L, 2L, NA,
5L, NA, 4L, 2L, NA, NA, 1L, 4L, NA, 5L, NA, NA), Mean = c(3.07142857142857,
2.78571428571429, 2.46153846153846, 2.69230769230769, 3.21428571428571,
3.07142857142857, 2.54545454545455, 2.83333333333333, 3.15384615384615,
3.18181818181818, 2.81818181818182, 2.72727272727273, 3.7,
2.63636363636364, 3.15384615384615, 2.83333333333333, 2.8,
3.07692307692308, 2.5, 3.0625), Pearson = structure(c(0.277097961607667,
0.492592183071889, -0.184664098655286, -0.306988756155365,
0.047716527859489, 0.597614304667197, 0.0363696483726654,
0.0793422835603058, -0.444514447822542, -0.344265186329548,
-0.186499664263607, 0.365148371670111, 0.205737799949456,
0.427324672683063, 1, -0.732776720760177, 0.944911182523068,
-0.587378478571482, 0.578979445733232, -0.0881134221062802
), .Dim = c(20L, 1L), .Dimnames = list(c("John", "Maria",
"Anton", "Roger", "Martina", "Ana", "Sergi", "Marc", "Jim",
"Chris", "Bernard", "Nuria", "Nerea", "Carles", "Victoria",
"Ivan", "Rachel", "Nadia", "Oriol", "Valery"), "Victoria")),
PearsonABS = structure(c(0.277097961607667, 0.492592183071889,
0.184664098655286, 0.306988756155365, 0.047716527859489,
0.597614304667197, 0.0363696483726654, 0.0793422835603058,
0.444514447822542, 0.344265186329548, 0.186499664263607,
0.365148371670111, 0.205737799949456, 0.427324672683063,
1, 0.732776720760177, 0.944911182523068, 0.587378478571482,
0.578979445733232, 0.0881134221062802), .Dim = c(20L, 1L), .Dimnames = list(
c("John", "Maria", "Anton", "Roger", "Martina", "Ana",
"Sergi", "Marc", "Jim", "Chris", "Bernard", "Nuria",
"Nerea", "Carles", "Victoria", "Ivan", "Rachel", "Nadia",
"Oriol", "Valery"), "Victoria"))), .Names = c("User",
"Star.Wars.IV...A.New.Hope", "Star.Wars.VI...Return.of.the.Jedi",
"Forrest.Gump", "The.Shawshank.Redemption", "The.Silence.of.the.Lambs",
"Gladiator", "Toy.Story", "Saving.Private.Ryan", "Pulp.Fiction",
"Stand.by.Me", "Shakespeare.in.Love", "Total.Recall", "Independence.Day",
"Blade.Runner", "Groundhog.Day", "The.Matrix", "Schindler.s.List",
"The.Sixth.Sense", "Raiders.of.the.Lost.Ark", "Babe", "Mean",
"Pearson", "PearsonABS"), row.names = c(NA, -20L), class = "data.frame")我希望我解释得很清楚。有人能帮我吗?
回答 1
Stack Overflow用户
发布于 2018-02-13 23:19:37
好的,我希望你能理解这一点,我会尽力给出足够的解释。其目标是编写一个函数,该函数可以完成手动计算,并使多次运行变得容易。
整理
首先,我们希望使数据变得整洁,因此使用起来更容易。这意味着使每一列都成为一个变量,因此没有跨多列的电影评级。见这里有更多关于整洁数据的信息。我们将使用tidyverse包来完成这个任务。
- 使用
select删除mean列。我们希望能够以不同的方式计算它们,这取决于我们正在查看的用户,而且它们也以列表的形式存储在您的dput中。 - 使用
gather获取所有电影栏,并将电影名称放在一列中,将分级放在另一列中。 - 将
User重命名为小写以保持一致性 - 使用
group_by和mutate对每个用户进行平均评等。na.rm = TRUE意味着mean在计算时将忽略所有NA值。
看上去像这样。现在看到的数据是整洁的,只有四列。
library(tidyverse)
library(magrittr)
tidy_cr <- cr %>%
select(-Mean, -Pearson, -PearsonABS) %>%
gather("film", "rating", -User) %>%
rename(user = User) %>%
group_by(user) %>%
mutate(mean = mean(rating, na.rm = TRUE)) %>%
ungroup()
# A tibble: 400 x 4
user film rating mean
<fct> <chr> <int> <dbl>
1 John Star.Wars.IV...A.New.Hope 1 3.07
2 Maria Star.Wars.IV...A.New.Hope 5 2.79
3 Anton Star.Wars.IV...A.New.Hope NA 2.46
4 Roger Star.Wars.IV...A.New.Hope NA 2.69
5 Martina Star.Wars.IV...A.New.Hope 4 3.21
6 Ana Star.Wars.IV...A.New.Hope 2 3.07
7 Sergi Star.Wars.IV...A.New.Hope NA 2.55
8 Marc Star.Wars.IV...A.New.Hope 4 2.83
9 Jim Star.Wars.IV...A.New.Hope 5 3.15
10 Chris Star.Wars.IV...A.New.Hope 4 3.18
# ... with 390 more rows维多利亚实例
这是一步一步地向您展示每个阶段的输出,以维多利亚为例。首先,我们想知道维多利亚没有看过哪些电影。我们这样做的方法是,filter下到user列中有Victoria的行和NA评级中的行,然后取出film列。
v_films_not_seen <- tidy_cr %>%
filter(user == "Victoria" & is.na(rating)) %>%
extract2("film")
[1] "Forrest.Gump" "The.Shawshank.Redemption" "Saving.Private.Ryan"
[4] "Shakespeare.in.Love" "Blade.Runner" "The.Matrix"
[7] "The.Sixth.Sense" 然后,我们想得出维多利亚的评级,这样我们就可以计算出相关系数和她的具体平均值。我们减少到与维多利亚的行,现在取出rating列。
v_persons_ratings <- tidy_cr %>%
filter(user == "Victoria") %>%
extract2("rating")
[1] 4 4 NA NA 5 5 2 NA 3 5 NA 1 3 NA 2 NA 3 NA 3 1现在我们要计算这些关联。我们首先是group_by用户,所以这个计算将在每个用户完成.然后,我们使用mutate和cor来计算每个用户的评分和维多利亚的评分之间的相关性,我们在最后一步将它们保存为v_persons_ratings。选项use = "complete.obs"意味着相关只关注两个用户对影片评级的观察结果。然后利用abs求出相关系数的绝对值。
v_correlations <- tidy_cr %>%
group_by(user) %>%
mutate(
pearson = cor(rating, v_persons_ratings, use = "complete.obs"),
pearson_abs = abs(pearson)
) %>%
ungroup()
# A tibble: 400 x 6
user film rating mean pearson pearson_abs
<fct> <chr> <int> <dbl> <dbl> <dbl>
1 John Star.Wars.IV...A.New.Hope 1 3.07 0.277 0.277
2 Maria Star.Wars.IV...A.New.Hope 5 2.79 0.493 0.493
3 Anton Star.Wars.IV...A.New.Hope NA 2.46 -0.185 0.185
4 Roger Star.Wars.IV...A.New.Hope NA 2.69 -0.307 0.307
5 Martina Star.Wars.IV...A.New.Hope 4 3.21 0.0477 0.0477
6 Ana Star.Wars.IV...A.New.Hope 2 3.07 0.598 0.598
7 Sergi Star.Wars.IV...A.New.Hope NA 2.55 0.0364 0.0364
8 Marc Star.Wars.IV...A.New.Hope 4 2.83 0.0793 0.0793
9 Jim Star.Wars.IV...A.New.Hope 5 3.15 -0.445 0.445
10 Chris Star.Wars.IV...A.New.Hope 4 3.18 -0.344 0.344
# ... with 390 more rows最后,我们使用filter和%in%运算符减少到包含维多利亚没有看过的那些行。我们这次是group_by胶片,所以计算是按胶片计算的.然后,我们用summarise来计算推荐分数,用你在问题中列出的公式来计算,然后加上维多利亚的平均值。最后,我们使用arrange和desc按降序排序。
v_recommendations <- v_correlations %>%
filter(film %in% v_films_not_seen) %>%
group_by(film) %>%
summarise(
score = sum((rating - mean) * pearson, na.rm = TRUE) / (sum(pearson_abs) - 1)) %>%
mutate(score = score + mean(v_persons_ratings, na.rm = TRUE)) %>%
arrange(desc(score))
# A tibble: 7 x 2
film score
<chr> <dbl>
1 The.Matrix 3.79
2 Forrest.Gump 3.51
3 The.Sixth.Sense 3.33
4 Shakespeare.in.Love 3.11
5 Blade.Runner 2.91
6 Saving.Private.Ryan 2.89
7 The.Shawshank.Redemption 2.81函数
呼!现在,我们只需将上述代码放入函数中,将上面的所有v_对象替换为泛型对象,并提供tbl、person和n作为参数。tbl是电影、用户、收视率和用户平均评分的数据,person是我们希望推荐的人,n是我们想要的推荐数量。这段代码与上面的代码基本相同,只是我在最后添加了head(n),只返回推荐表的n行。
top_recs <- function(tbl, person, n){
films_not_seen <- tbl %>%
filter(user == person & is.na(rating)) %>%
extract2("film")
persons_ratings <- tbl %>%
filter(user == person) %>%
extract2("rating")
correlations <- tbl %>%
group_by(user) %>%
mutate(
pearson = cor(rating, persons_ratings, use = "complete.obs"),
pearson_abs = abs(pearson)
) %>%
ungroup()
recommendations <- correlations %>%
filter(film %in% films_not_seen) %>%
group_by(film) %>%
summarise(
score = sum((rating - mean) * pearson, na.rm = TRUE) / (sum(pearson_abs) - 1)) %>%
mutate(score = score + mean(persons_ratings, na.rm = TRUE)) %>%
arrange(desc(score)) %>%
head(n)
}我们可以再次用Victoria测试这个函数,并看到它是有效的:
top_recs(tidy_cr, "Victoria", 5) %>% print()
# A tibble: 5 x 2
film score
<chr> <dbl>
1 The.Matrix 3.79
2 Forrest.Gump 3.51
3 The.Sixth.Sense 3.33
4 Shakespeare.in.Love 3.11
5 Blade.Runner 2.91但是,我们现在也可以获得对任何用户的建议,例如给Bernard的8条建议:
top_recs(tidy_cr, "Bernard", 8) %>% print()
# A tibble: 8 x 2
film score
<chr> <dbl>
1 The.Shawshank.Redemption 3.23
2 Pulp.Fiction 3.17
3 Schindler.s.List 3.11
4 Blade.Runner 2.97
5 Saving.Private.Ryan 2.94
6 Shakespeare.in.Love 2.74
7 Groundhog.Day 2.72
8 Stand.by.Me 2.60备注
这实际上是一个有趣的练习,您是否可以找到工具来做您想做的事情,并相应地构造工作流。我认为这种方法的威力是突出的,因为我们现在可以为任何用户提供建议。也许更重要的是,代码中的任何内容(我认为)都不依赖于这些特定的用户、电影或收视率。如果您有更多的数据,您只需将它们添加到tidy_cr的底部,该函数仍然可以工作。如果您更改了评等公式,则只需编辑几行即可更新它。
我希望您能通过这一步,并了解更多关于如何编写您自己的函数在R!其他后续步骤可能是错误检查,例如,如果您要求提供比现有建议更多的建议,或者键入不在数据库中的用户名,则会显示一些信息。我认为这可能令人望而生畏,但?是您在R中检查函数选项的最好朋友。我绝对不知道这一切都是从我头上冒出来的!
https://stackoverflow.com/questions/48774183
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号