
遗传算法-无序变长染色体-交叉策略?
我在研究遗传算法。染色体不是有序的--这意味着它们在成员中出现的顺序不影响成员得分。而且染色体的数目也不是固定的。一个成员可能有一个染色体,另一个成员可能有超过100个染色体。
我在Python工作,染色体被存储在列表中。以下是该结构的简化示例:
member = [{"key1":"value","key2":"value"},{"key1":"value","key2":"value"},{"key1":"value","key2":"value"}]两个示例成员(简化)可能是:
member1 = [{"a":1.5,"b":2.334563},{"a":769.0003413,"b":0.00023}]
member2 = [{"a":7,"b":432.993246927},{"a":99,"b":532.234},{"a":21,"b":712.2},{"a":432,"b":999.9999},{"a":932,"b":12}]在应用程序中,重复出现故障的染色体是可以的:
member3 = [{"a":1,"b":1},{"a":2,"b":2},{"a":2,"b":2},{"a":1,"b":1}]成员
成员中的每个染色体都是一个数学函数,它以Unix时间戳作为输入,并输出一个值。这允许我在任何时候使用该成员的函数获得“值”。染色体中的键总是相同的--但在初始播种值期间,这些值是随机生成的,从0到100不等,小数点数最多为100位。
分级系统
我正在根据SQL数据库中的实时序列数据对函数进行分级。时间序列数据每隔1到3秒不断更新一次新值.当我对这些数据进行选择时,我选择epoc值大于当前EPOC-5秒的位置,并通过降序排序,并将输出限制在1行。我取返回的实际epoc值,这是我所评定的值之一。
我取所有的点(epoc:值对)并使用它们来评分,给成员函数epoc,得到成员的值,然后从实际值中减去这个值,然后取它的绝对值。
看上去有点像这样:
total = 0
for chromosome in member[chromosomes]:
for epoc in epocs:
thisValue = Calc(epoc,chromosome)
total = total + abs(thisValue - getRealValue(epoc))函数Calc取染色体和epoc值,输出浮点。
零是一个完美的分数。分数越高,队员就越差。我平均所有成员的分数,并删除低于平均水平的。
我尝试根据数据库中的一组静态数据进行分级,并尝试根据过去的24小时进行动态分级--这意味着,随着时间的推移,过去的24小时总是不同的。我也试过过去的4个小时,最后一个小时,和持续3天。
突变系统
我把我的突变率设为2%,但我在更高的百分比上玩过,结果更糟。只有孩子可能会变异,而不是现有的人口(想要留住精英)。当一个孩子被选择进行突变时,它在染色体中的值被随机移动(加或减随机)--小数点在小数点0到1之间的100位小数。这给孩子的价值观带来了微小的变化--因为一个非常微小的变化会极大地改变染色体功能的输出。
我的问题
我现在使用的交叉方法会导致过早的收敛。
交叉策略我尝试过
我试过从每个家长那里随机抽取一些染色体。我试过把第一父母的前半部分和第二家长的后半部分都取下来。到目前为止,我已经尝试过这些方法:
# Number of chromosomes from parent 1.
parent1chromosomes = randomNumber(0,len(parent1['chromosomes']))
# Number of chromosomes from parent 2.
parent2chromosomes = randomNumber(0,len(parent2['chromosomes']))
child = {}
child['chromosomes'] = []
# Get parent 1 chromosomes into child.
for i in range(0,parent1chromosomes):
child['chromosomes'].append(random.choice(parent1['chromosomes']))
# Get parent 2 chromosomes into child.
for i in range(0,parent2chromosomes):
child['chromosomes'].append(random.choice(parent2['chromosomes']))注意:randomNumber是一个函数,它在指定的范围之间返回一个随机整数。
这两种尝试都导致了早期的趋同。我想解决的问题非常复杂--到目前为止,我已经尝试了10,000到1,000,000的人口规模。
示例性能
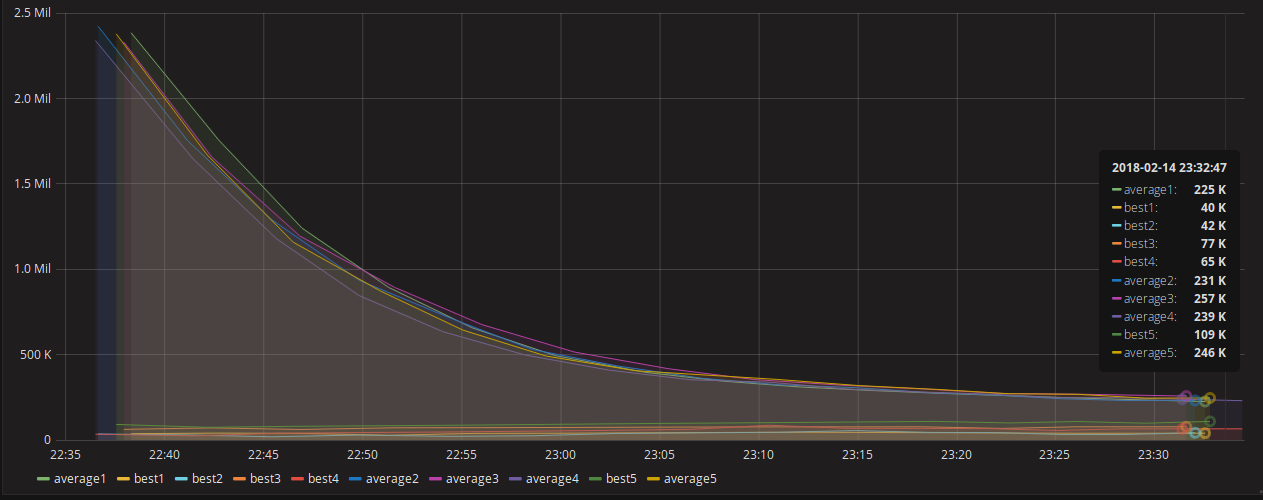
这是最近一次运行的屏幕截图。我正在绘制最好的分数(最低的)和平均的分数。在这张照片中,它描绘了五个不同人群的最佳和平均时间。这些特定的5个群体使用3秒的实际数据抽样,每个10,000名成员,并且动态地对最后一个小时的真实数据进行评分--这就是为什么最好的数据会变得更糟的原因--因为它所依据的真实数据的变化会使最好的成员变得更糟。最好的分数是几千分,这是根本不准确的。较少的人口导致更快的早期收敛。
我的问题
在染色体顺序不重要、重复染色体不重要的情况下,还有什么更好地处理可变长度成员交叉的方法?
回答 2
Stack Overflow用户
发布于 2018-02-13 19:24:46
而不是:
for i in range(0,parent1chromosomes):
child['chromosomes'].append(random.choice(parent1['chromosomes']))也许:
child['chromosomes'].extend(random.sample(parent1['chromosomes'], parent1chromosomes))这意味着你只能从父母一方获得重复染色体,或者从父母双方得到一个拷贝。
Stack Overflow用户
发布于 2018-02-15 09:05:05
免责声明:基于您的反馈,这个答案可能会在后续的改进中引起。
因此,我们想在这里解决两个问题:
- 快速收敛:种群多样性下降过快
- 遗传淘汰:健身功能随着时间的推移而变化,这使得早期成功的个体长期失去潜能,而早期的不成功个体则成为长期的潜在赢家。
在您的场景中,在每一轮中,都会保留--您的群体中最好的个人。原则上,这通常是一个好主意:一个人不想失去最优解的最佳近似。然而,从一轮到下一轮,你保留的个体越多(wrt )。全球人口),人口内部的多样性减少得越快。这是因为让一个人活下来会给他的基因组一个更高的传播机会,而且这种情况会在多个回合中以指数的速度发生。因此,从一轮到下一轮,你保持生存的个体比例应该是非常小的,与整个种群相比,或者为零。
或者,你可以通过加强你的突变率来补偿fast-convergence,使它产生更高的多样性。在这方面,您可能需要考虑采用两种不同的突变方法:
- strong-mutation:,这改变了一些价值,以一种任意的方式,所以引入(或重新引入)在人群中,一个基因是无法获得的。有几种方法可以做到这一点:1。a(或多个)新的
key-value对被任意丢弃或引入到孩子2的基因组中。key或key-value对的value是以任意的方式改变的,类似于您现在正在做的事情。 - weak-mutation:考虑到您的适应度函数的性质,它会随着时间的推移而改变其分数评估,使用
%计算任意地对某些数值进行alter可能是明智的,例如akey-value对由0.00000001%增加/减少。这将使您的用户更容易适应时间的流动,尽管我必须指出,应该非常小心地选择所选择的变化率,这样才不会使主导搜索或使其不稳定。
房间里真正的大象是基因过时的。假设你的问题是离散的而不是连续体,你必须在时间上为不动点找到最好的个体,而不是因为一个变化的适应度函数而在搜索过程中“进化”。然后,在前一种情况下,我们要做的是对适应度函数执行不同权重的N单独搜索。每一次,我们都会从一个完全随机的种群开始,然后允许遗传算法收敛到一个最优解。现在以一个非常大的N为例,它足够大,以便搜索所需的时间与您想要评估的下几个点重叠,并尝试重叠在所有搜索中保留的总体。你得到的是啥?你会得到一个高度多样性的群体,因为几个重叠搜索才刚刚开始!
因此,如果您现在想将离散的情况扩展到连续体,您必须复制相同的情况:在每一轮,或者在固定(和少量)回合之后,您应该生成一组新的随机个体,就像初始化阶段的情况一样,并给它们一个繁殖的机会。这需要小心地做,因为新的种群是完全随机的,它可能会在几轮的时间内完全被现有的种群所淹没。一种想法可能是让新的随机的个体池在安全的避难所中被改进一些回合,然后根据主要的个人池进行评估。经过几轮后,这两个池可以相互繁殖,然后合并成一个独特的种群,这样就可以创建一个新的随机个体集。
https://stackoverflow.com/questions/48773854
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号