
卷积神经网络中的过拟合
卷积神经网络中的过拟合
提问于 2018-02-06 02:55:24
我申请CNN对手势进行分类,我有10个手势和100个手势图像。我所建立的模型对训练数据的准确率约为97%,而我在测试数据中的准确率为89%。我是否可以说,我的模型是过度安装,或它是否可以接受有这样的准确性图表(如下所示)?
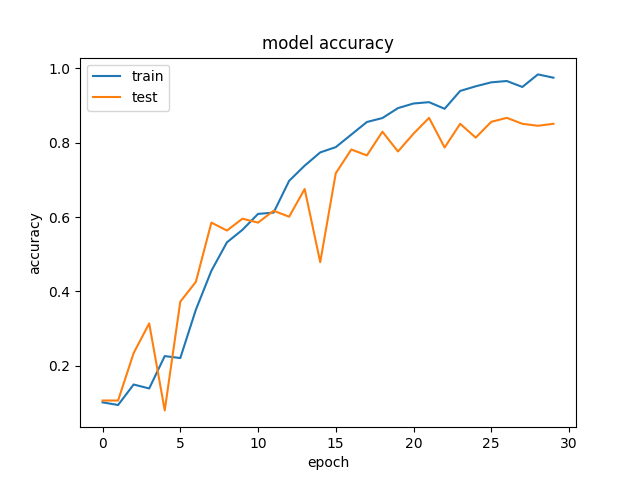
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-02-06 05:02:16
向培训集添加更多数据
当您的培训集中有大量的数据(各种实例)时,创建一个过度拟合的模型是很好的。
例如:假设你只想检测到一个手势,比如“拇指向上”(二进制分类问题),你已经用大约1000幅图像创建了你的正面训练集,其中图像被旋转、翻译、缩放、不同颜色、不同角度、不同视点、背景cluttered...etc。如果你的训练准确率是99%,你的测试准确率也将接近某个地方。
由于我们的训练集足够大,足以涵盖所有阳性类的实例,所以即使模型被过度拟合,它也会在测试集中表现良好,因为测试集中的实例与训练集中的实例只会有微小的变化。
在您的情况下,您的模型是好的,但如果您可以添加更多的数据,您将获得更好的准确性。
要添加什么样的数据?
手动检查模型出错的测试样本,并检查模式,如果您能够找出哪种样本出错了,您可以将这类样本添加到您的培训集中,然后再进行一次培训。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/48634756
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号