
在小批量梯度下降中的混淆使用
我的问题是最后。
一个示例 CNN接受了小批量GD的训练,并在最后一个完全连接的层(第60行)中使用了退出。
fc1 = tf.layers.dropout(fc1, rate=dropout, training=is_training)起初,我认为tf.layers.dropout或tf.nn.dropout在列中随机地将神经元设置为零。但我最近发现情况并非如此。下面的代码将打印dropout所做的工作。我使用fc0作为一个4样例x10特征矩阵,使用fc作为退出版本。
import tensorflow as tf
import numpy as np
fc0 = tf.random_normal([4, 10])
fc = tf.nn.dropout(fc0, 0.5)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
a, b = sess.run([fc0, fc])
np.savetxt("oo.txt", np.vstack((a, b)), fmt="%.2f", delimiter=",")并在输出oo.txt (原始矩阵:第1-4行,退出矩阵:第5-8行):
0.10,1.69,0.36,-0.53,0.89,0.71,-0.84,0.24,-0.72,-0.44
0.88,0.32,0.58,-0.18,1.57,0.04,0.58,-0.56,-0.66,0.59
-1.65,-1.68,-0.26,-0.09,-1.35,-0.21,1.78,-1.69,-0.47,1.26
-1.52,0.52,-0.99,0.35,0.90,1.17,-0.92,-0.68,-0.27,0.68
0.20,0.00,0.71,-0.00,0.00,0.00,-0.00,0.47,-0.00,-0.87
0.00,0.00,0.00,-0.00,3.15,0.07,1.16,-0.00,-1.32,0.00
-0.00,-3.36,-0.00,-0.17,-0.00,-0.42,3.57,-3.37,-0.00,2.53
-0.00,1.05,-1.99,0.00,1.80,0.00,-0.00,-0.00,-0.55,1.35我对正确的理解?退出是,在一个小批处理或批处理梯度下降阶段,为每个样本敲出p% 相同的单元,并且反向传播更新“细化网络”的权重和偏差。然而,在示例的实现中,的神经元在一批样本中被随机删除,如oo.txt第5行至第8行所示,而对于每个样本,“稀疏网络”是不同的。
作为比较,在随机梯度下降的情况下,样本被一个一个地输入到神经网络中,并且在每次迭代中,每个引入的“细化网络”的tf.layers.dropout的权重被更新。
我的问题是,在小批次或批次训练中,难道不应该对一批中的所有样本执行敲除相同的神经元吗?也许通过在每次迭代时对所有输入批样本应用一个掩码?类似于:
# ones: a 1xN all 1s tensor
# mask: a 1xN 0-1 tensor, multiply fc1 by mask with broadcasting along the axis of samples
mask = tf.layers.dropout(ones, rate=dropout, training=is_training)
fc1 = tf.multiply(fc1, mask)现在我在想,示例中的退出策略可能是一种加权方法,用于更新某个神经元的权重,如果一个神经元被保存在一个小批量的10个样本中,那么它的权重将由alpha * 1/10 * (y_k_hat-y_k) * x_k更新,而对于在所有10个样本中保留的另一个神经元的权重,alpha * 1/10 * (y_k_hat-y_k) * x_k会更新它的权重吗?
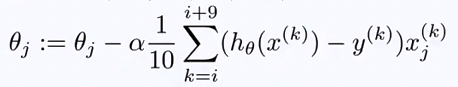
来自这里的截图
回答 2
Stack Overflow用户
发布于 2018-02-05 08:27:02
辍学通常被用来防止过度适应。在这种情况下,它将是一个巨大的重量施加在其中一个神经元。通过随机地使它不时地为0,你强迫网络使用更多的神经元来决定结果。要想让它工作得很好,你应该在每一个例子中删除不同的神经元,这样你计算出来的梯度就会更接近于你在没有辍学的情况下得到的梯度。
如果要对批处理中的每个示例删除相同的神经元,我的猜测是,您将有一个不太稳定的梯度(对您的应用程序可能不重要)。
此外,退出-扩大其馀的值,以保持平均激活水平大约相同。没有它,网络就会学到错误的偏见,或者当你关闭掉时会变得过于饱和。
如果你仍然希望同样的神经元在批次中被丢弃,然后将其应用于所有的1张张量形状(1,num_neurons),然后将其与激活相乘。
Stack Overflow用户
发布于 2018-05-12 16:15:01
在使用辍学时,您实际上是在使用Monte抽样(通过积分下的微分,平均梯度等于平均梯度)来估计随机选择的退出掩码的网络的平均性能。通过为每个小批修复一个退出掩码,您只是在逐次梯度估计之间引入相关性,这会增加方差并导致更慢的训练。
想象一下,对于小批处理中的每一张图像,使用一个不同的退出掩码,但是从相同图像的k个拷贝中形成一个小批处理,这显然是完全浪费精力!
https://stackoverflow.com/questions/48618108
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号