
内存优化表-插入速度比SSD慢
我观察到,将数据插入到内存优化表中比将数据插入到5-SSD条带集上的基于磁盘的表的等效并行化插入要慢得多。
--DDL for Memory-Optimized Table
CREATE TABLE [MYSCHEMA].[WIDE_MEMORY_TABLE]
(
[TX_ID] BIGINT NOT NULL
, [COLUMN_01] [NVARCHAR](10) NOT NULL
, [COLUMN_02] [NVARCHAR] (10) NOT NULL
--etc., about 100 columns
--at least one index is required for Memory-Optimized Tables
, INDEX IX_WIDE_MEMORY_TABLE_ENTITY_ID HASH (TX_ID) WITH (BUCKET_COUNT=10000000)
)
WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_ONLY)
--DDL for Disk-Based Table
CREATE TABLE [MYSCHEMA].[WIDE_DISK_TABLE]
(
[TX_ID] BIGINT NOT NULL
, [COLUMN_01] [NVARCHAR](10) NOT NULL
, [COLUMN_02] [NVARCHAR] (10) NOT NULL
--etc., about 100 columns
--No indexes
) ON [PRIMARY]对于这个特定的测试,我将把10,000,000行分批到这个表中,每组25,000行。对于内存优化表,该语句如下所示:
--Insert to Memory-Optimized Table
INSERT INTO
WIDE_MEMORY_TABLE
(
TX_ID
, COLUMN_01
, COLUMN_02
--etc., about 100 columns
)
SELECT
S.COLUMN_01
, S.COLUMN_02
--etc., about 100 columns
FROM
[MYSCHEMA].[SOURCE_TABLE] AS S WITH(TABLOCK)
WHERE
S.TX_ID >= 1
AND S.TX_ID < 25001
OPTION (MAXDOP 4)此进程继续加载10,000,000行。每次迭代只检索接下来的25,000行。SELECT对MY_SCHEMA.SOURCE_TABLE上的覆盖索引执行查找。查询计划显示序列化的插入到BIG_MEMORY_TABLE。每套25,000行的长度约为1400毫秒。
如果我对托管在5-SSD条带上的基于磁盘的表(每个磁盘5,000 IOPS,200 to /秒的吞吐量)执行此操作,则插入的进度要快得多,平均约为700 to。在基于磁盘的情况下,查询执行并行插入到MY_SCHEMA.WIDE_DISK_TABLE.注意MYSCHEMA.WIDE_DISK_TABLE上的TABLOCK提示。
--Insert to Disk-Based Table
INSERT INTO
WIDE_DISK_TABLE WITH(TABLOCK)
(
TX_ID
, COLUMN_01
, COLUMN_02
--etc., about 100 columns
)
SELECT
S.COLUMN_01
, S.COLUMN_02
--etc., about 100 columns
FROM
[MYSCHEMA].[SOURCE_TABLE] AS S WITH(TABLOCK)
WHERE
S.TX_ID >= 1
AND S.TX_ID < 25001
OPTION (MAXDOP 4)当然,基于磁盘的表没有索引,TABLOCK提示支持并行插入,但我期望从insert到RAM的方式更多。
有什么想法吗?
谢谢!
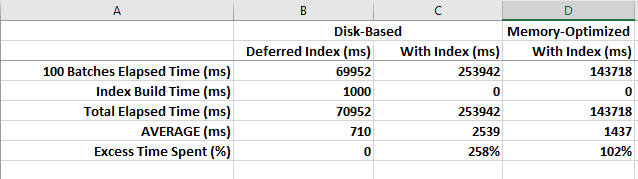
下面是以3种模式运行的100批数据的比较:基于磁盘的,与延迟索引的创建,基于磁盘的索引,以及由索引优化的内存(内存优化表至少需要一个索引)。
回答 1
Stack Overflow用户
发布于 2018-02-10 15:36:56
更新
经过大量的测试和研究,我相信这可以归结为并行性。此时,Server 2016,包括SP1 CU7,都不支持对内存优化的表进行并行插入。--这使得所有插入语句都被插入到内存优化的表中--单线程.。
下面是Neugebauer关于这个问题的一篇有洞察力的文章:Niko Neugebauer - Hekaton中的并行性(内存OLTP)
这使得它对ETL/ELT摄取的用处要小得多。但是,OLTP DML (特别是通过本地编译的存储过程)和BI查询中的数据聚合非常出色。对于摄入,几乎不可能击败没有索引的基于SSD的堆,只要您采取正确的步骤来确保您的插入将并行运行。
即使数据库处于完全恢复模式,并行插入到基于磁盘的堆的性能也优于对内存优化表的插入。如果在INSERT.之后将可比较的索引添加到基于磁盘的表中,则这仍然是正确的。
https://stackoverflow.com/questions/48602705
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号