
噪声训练损失
我正在训练基于编解码注意力的模型,批量大小为8。我不怀疑数据集中有太多的噪音,但是示例来自几个不同的分布。
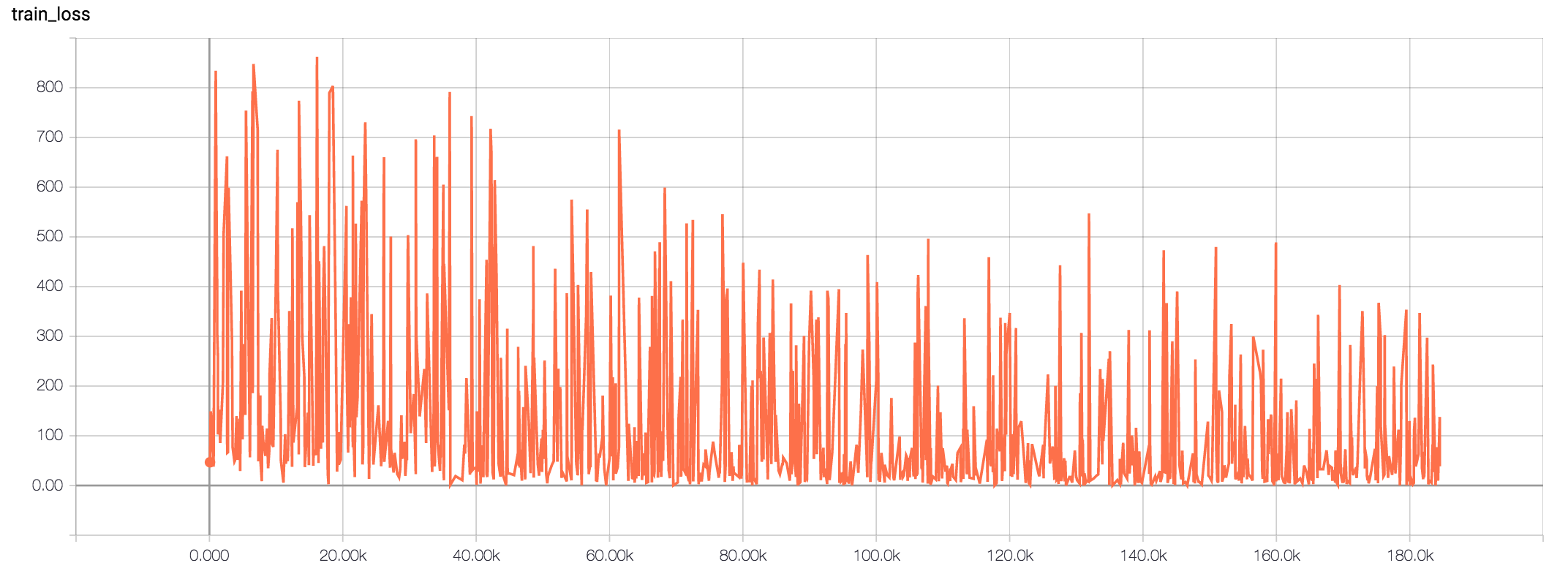
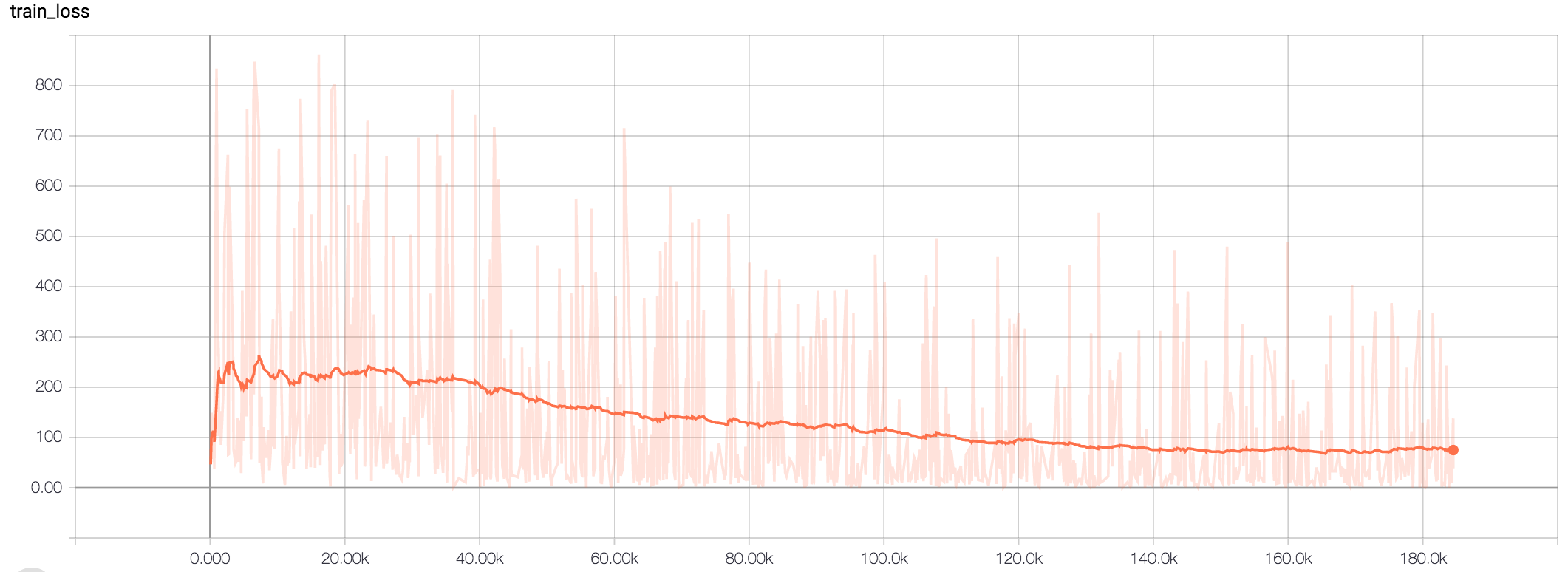
我能在火车损失曲线上看到很多噪音。平均后(.99)趋势良好。模型的精度也不差。
我想知道为什么会有这样的损失曲线。
回答 3
Stack Overflow用户
发布于 2018-03-07 09:42:38
我自己找到了答案。
我认为其他答案是不正确的,因为它们是基于一个更简单的模型/架构的经验。困扰我的主要问题是,损失中的噪声通常更对称(你可以画出平均值,噪声随机地在平均值和平均值以下)。在这里,我们看到的更像是低趋势路径和突然的高峰。
正如我所写的,我所使用的架构是非常注意的编解码器。可以很容易地得出结论,输入和输出可以有不同的长度。损失是所有时间步骤的总和,不需要除以时间步骤的数目。
https://www.tensorflow.org/tutorials/seq2seq
重要注意:值得指出的是,我们将损失除以batch_size,因此我们的超参数对batch_size是“不变的”。有些人将损失除以(batch_size * num_time_steps),它淡化了短句中所犯的错误。更微妙的是,我们的超参数(应用于前一种方式)不能用于后一种方式。例如,如果两种方法都使用学习为1.0的SGD,则后者有效地使用了1/ num_time_steps的小得多的学习速率。
我没有平均损失,这就是为什么噪音是可以观察到的。
类似地,例如8的批次大小可以有几百个输入和目标,所以实际上你不能说它是小的或大的,不知道示例的平均长度。
Stack Overflow用户
发布于 2018-02-02 09:54:18
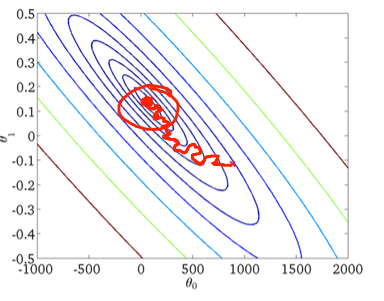
噪音训练的损失,但良好的准确性,可能是由于这个原因:
局部极小值:
该函数可以具有局部极小值,因此每次梯度下降收敛到局部极小时,损失/成本就会减少。但在学习速度好的情况下,该模型将学习从这些点跳转,梯度下降将收敛到全局极小值,即解。这就是为什么训练损失很大的原因。
Stack Overflow用户
发布于 2018-02-02 10:14:47
您使用的是小批处理梯度下降,它计算损失函数的梯度仅针对小批处理中的示例。然而,你正在测量的损失超过了所有的训练例子。总体损失应该有一个下降的趋势,但它往往会走错方向,因为你的小批量梯度不是一个足够准确的估计总损失。
此外,在每一步中,你都在将梯度乘以学习速率,试图降低损失函数。这是一个局部近似,经常会超过目标的最小值,并最终在损失面上的一个较高的点结束,特别是当你的学习率很高的时候。
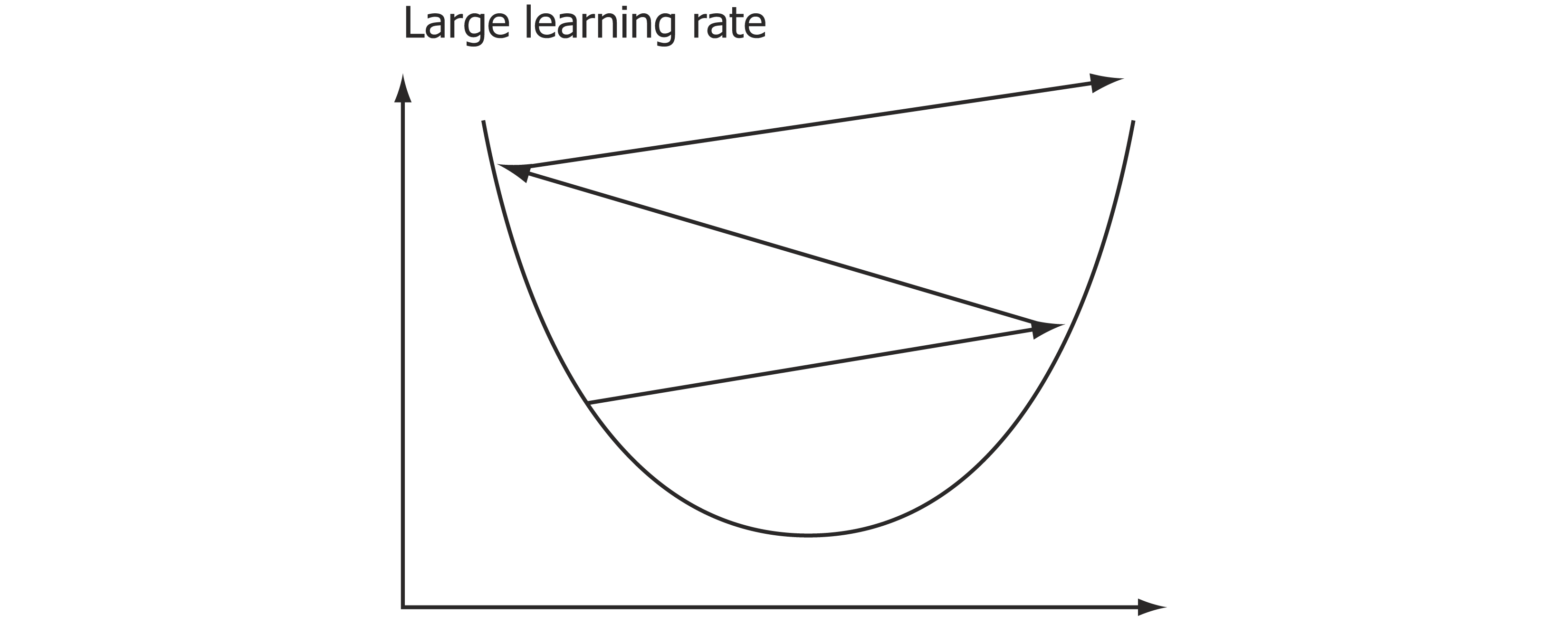
把这个图像看作只有一个参数的模型的损失函数。我们取点处的梯度,乘以学习速率,在梯度的方向投射一个线段(未见图)。然后,我们将这个线段末尾的x值作为我们更新的参数,最后在这个新的参数设置下计算损失。
如果我们的学习率太高,那么我们就会超过梯度指向的最小值,并可能导致更高的损失,如图所示。
https://stackoverflow.com/questions/48579315
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号