
用tensorflow.contrib.signal重建信号会引起放大或调制(帧、overlap_and_add、stft等)
UPDATE__:我在librosa中重新实现了这个比较,结果确实与tensorflow的结果非常不同。Librosa给出了我期望的结果(但不是tensorflow)。
我已经在tensorflow回购上发布了这个问题,但是那里很安静,所以我在这里尝试。另外,我也不确定这是tensorflow中的一个bug,还是代表我的用户错误。为了完整起见,我也将在这里包含完整的源代码和结果。
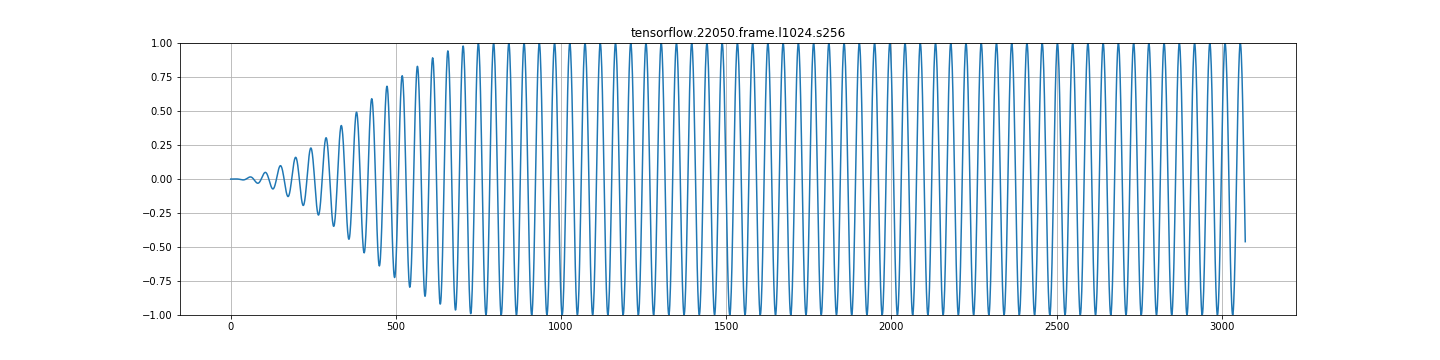
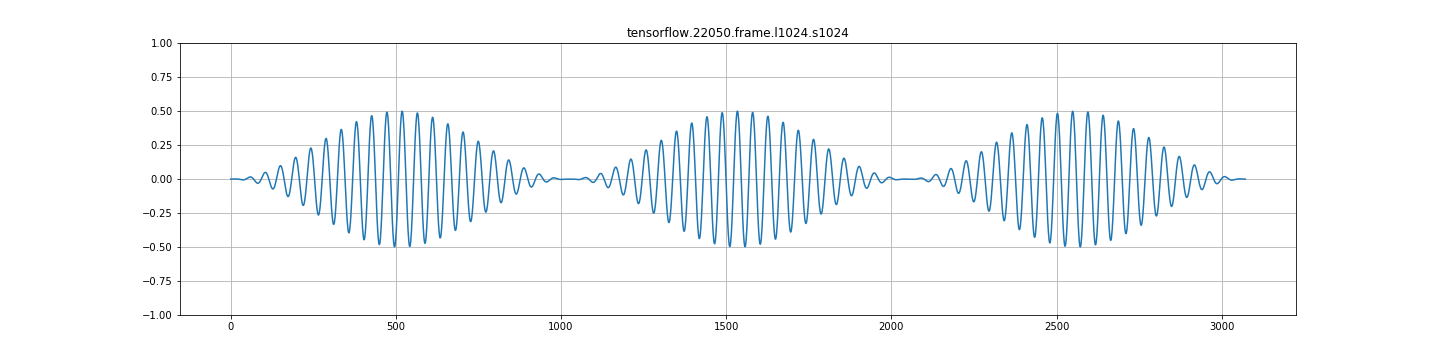
A.)当我用frame_length=1024和frame_step=256 ( 25% hop大小,75%重叠)的信号创建帧时,使用hann窗口(也尝试过hamming),然后用overlap_and_add进行重构,我希望信号能够被正确地重建(因为COLA等)。但结果却是振幅的两倍。我需要将产生的信号除以二,才能正确。
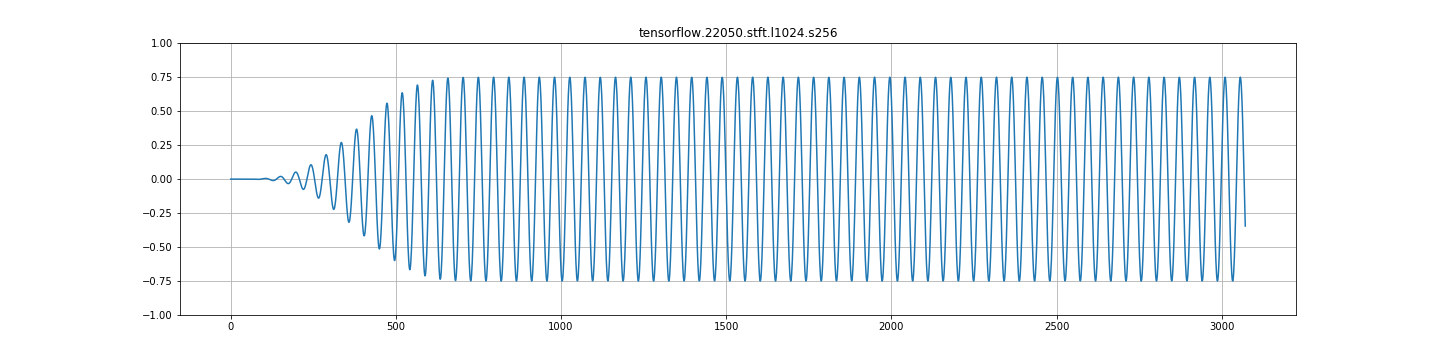
B.)如果用STFT建立一系列重叠谱图,再用逆STFT重建,再用frame_length=1024和frame_step=256重建信号,再进行双振幅重建。
我意识到为什么会出现这种情况( hann的单位增益为50%重叠,因此75%的重叠将使信号加倍)。但是,考虑到这一点,重建功能不正常吗?例如,librosa istft以正确的幅度返回信号,而tensorflow返回双倍的信号。
C.)在任何其他frame_step中,都存在严重的调幅。见下面的图片。这看起来一点都不对。
UPDATE:如果我在inverse_stft中显式地设置了window_fn=tf.contrib.signal.inverse_stft_window_fn(frame_step),则输出是正确的。因此,似乎frame_step在inverse_stft中并没有被传递到window函数中(这也是结果所暗示的)。
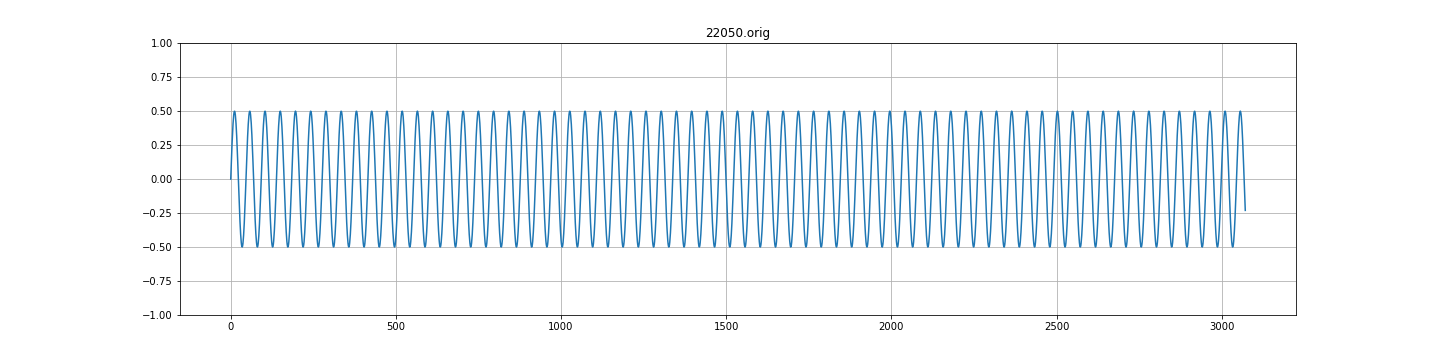
原始数据:
来自帧+overlap_and_add的流量输出:
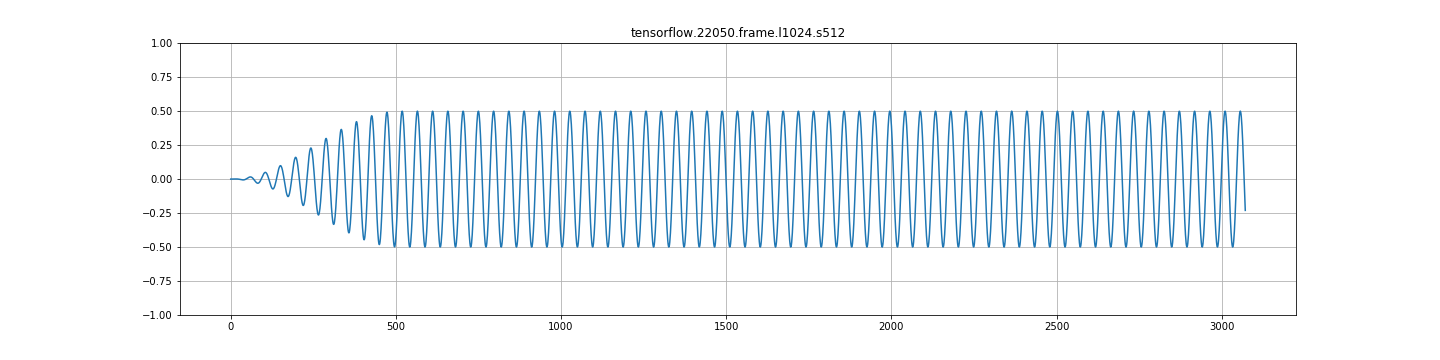
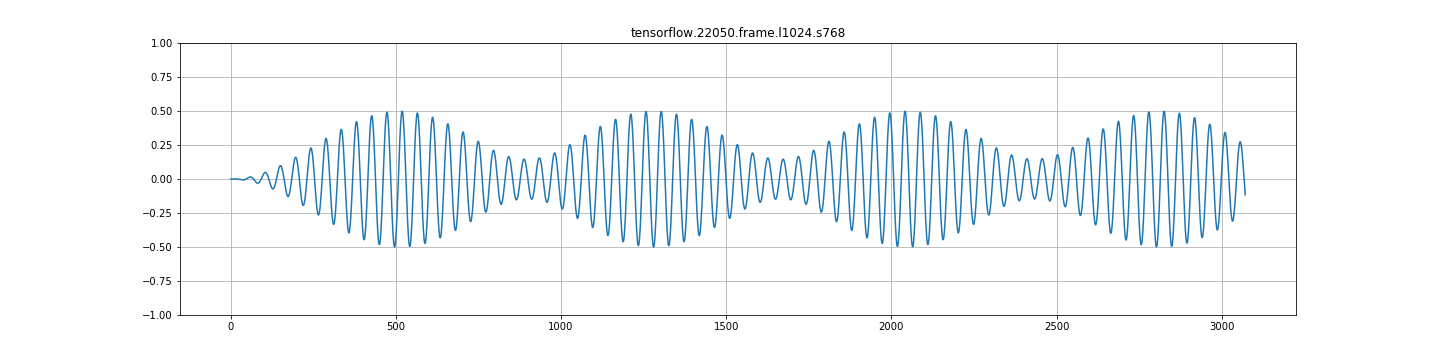
来自stft+istft的tensorflow输出:
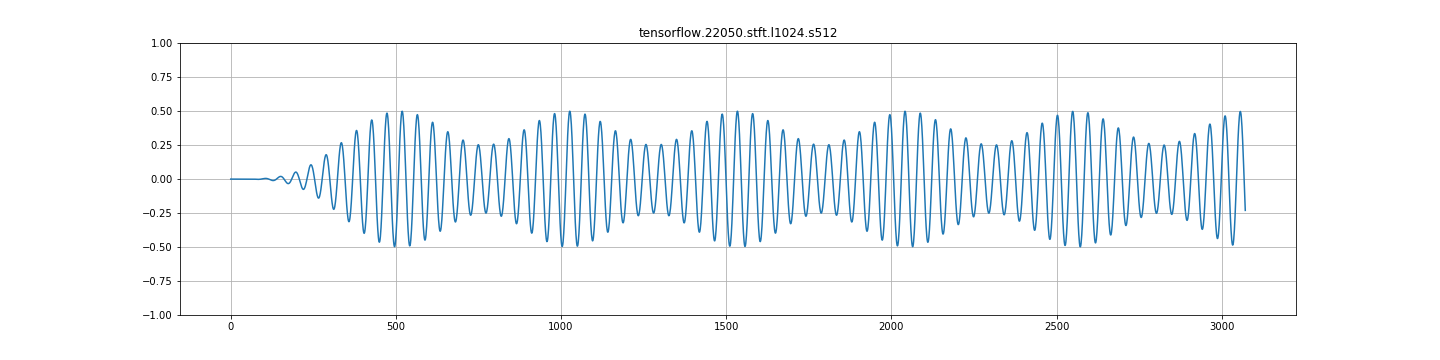
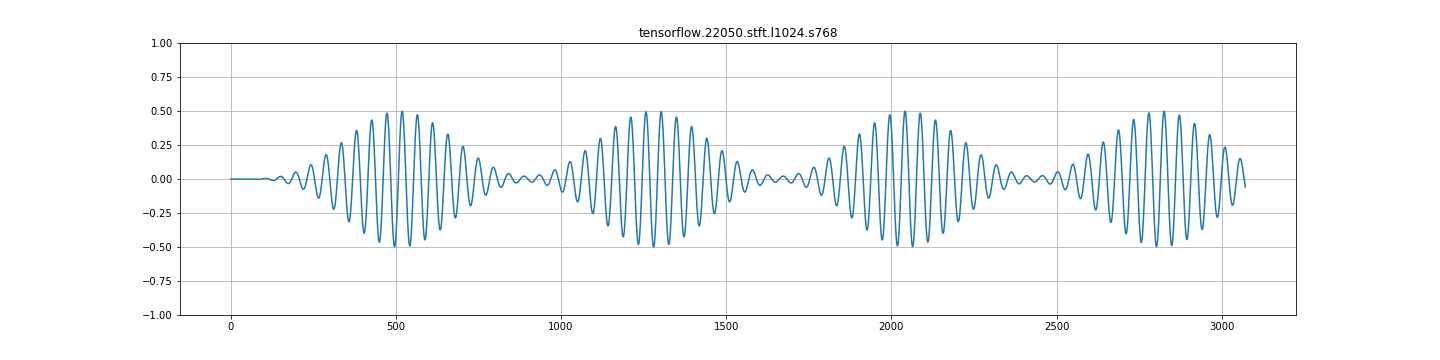
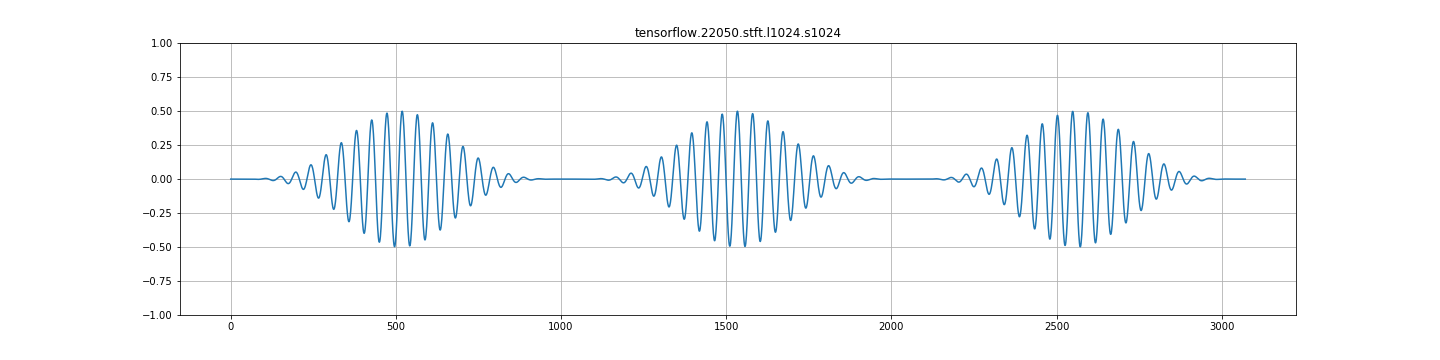
来自stft+istft的librosa输出:
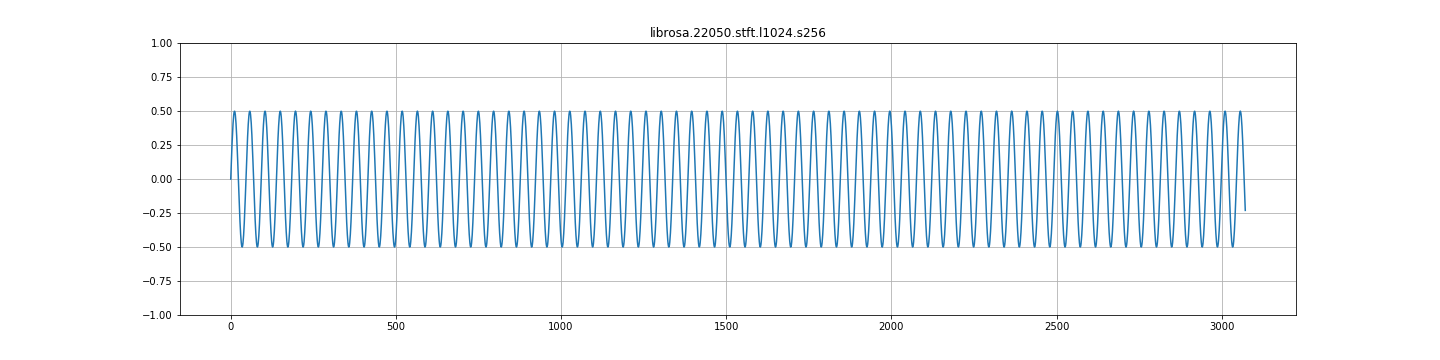
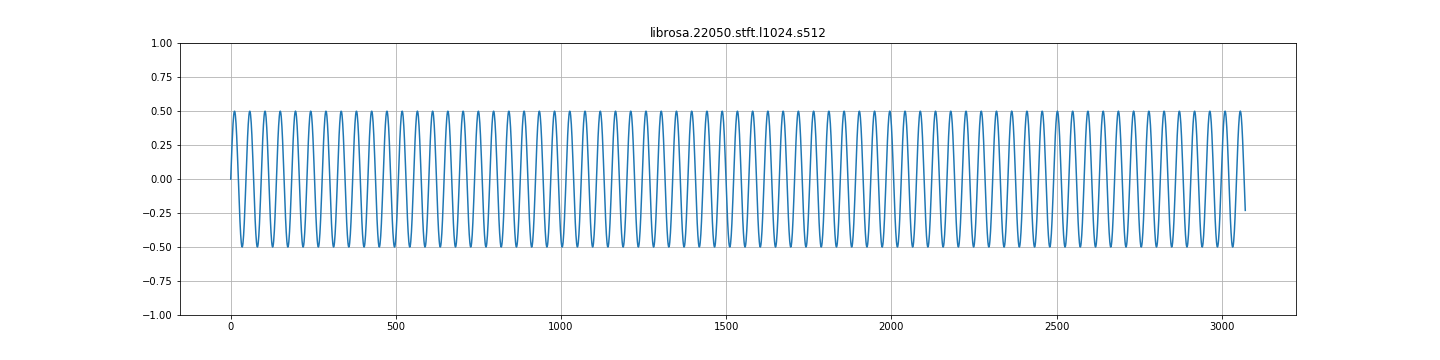
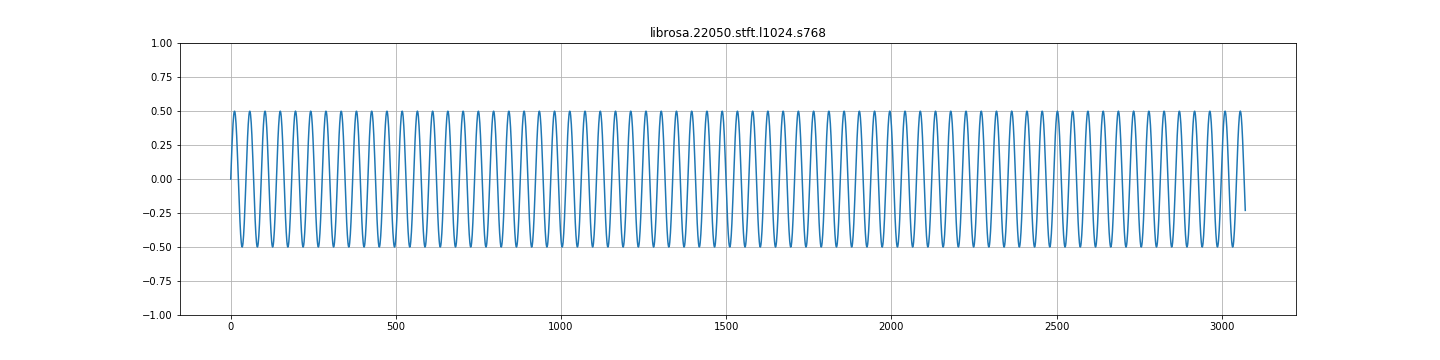
tensorflow代码:
from __future__ import print_function
from __future__ import division
import numpy as np
import scipy.io.wavfile
import math
import random
import matplotlib.pyplot as plt
import tensorflow as tf
out_prefix = 'tensorflow'
def plot(data, title, do_save=True):
plt.figure(figsize=(20,5))
plt.plot(data[:3*frame_length])
plt.ylim([-1, 1])
plt.title(title)
plt.grid()
if do_save: plt.savefig(title + '.png')
plt.show()
def reconstruct_from_frames(x, frame_length, frame_step):
name = 'frame'
frames_T = tf.contrib.signal.frame(x, frame_length=frame_length, frame_step=frame_step)
windowed_frames_T = frames_T * tf.contrib.signal.hann_window(frame_length, periodic=True)
output_T = tf.contrib.signal.overlap_and_add(windowed_frames_T, frame_step=frame_step)
return name, output_T
def reconstruct_from_stft(x, frame_length, frame_step):
name = 'stft'
spectrograms_T = tf.contrib.signal.stft(x, frame_length, frame_step)
output_T = tf.contrib.signal.inverse_stft(spectrograms_T, frame_length, frame_step)
return name, output_T
def test(fn, input_data):
print('-'*80)
tf.reset_default_graph()
input_T = tf.placeholder(tf.float32, [None])
name, output_T = fn(input_T, frame_length, frame_step)
title = "{}.{}.{}.l{}.s{}".format(out_prefix, sample_rate, name, frame_length, frame_step)
print(title)
with tf.Session():
output_data = output_T.eval({input_T:input_data})
# output_data /= frame_length/frame_step/2 # tensorflow needs this to normalise amp
plot(output_data, title)
scipy.io.wavfile.write(title+'.wav', sample_rate, output_data)
def generate_data(duration_secs, sample_rate, num_sin, min_freq=10, max_freq=500, rnd_seed=0, max_val=0):
'''generate signal from multiple random sin waves'''
if rnd_seed>0: random.seed(rnd_seed)
data = np.zeros([duration_secs*sample_rate], np.float32)
for i in range(num_sin):
w = np.float32(np.sin(np.linspace(0, math.pi*2*random.randrange(min_freq, max_freq), num=duration_secs*sample_rate)))
data += random.random() * w
if max_val>0:
data *= max_val / np.max(np.abs(data))
return data
frame_length = 1024
sample_rate = 22050
input_data = generate_data(duration_secs=1, sample_rate=sample_rate, num_sin=1, rnd_seed=2, max_val=0.5)
title = "{}.orig".format(sample_rate)
plot(input_data, title)
scipy.io.wavfile.write(title+'.wav', sample_rate, input_data)
for frame_step in [256, 512, 768, 1024]:
test(reconstruct_from_frames, input_data)
test(reconstruct_from_stft, input_data)
print('done.')librosa代码:
from __future__ import print_function
from __future__ import division
import numpy as np
import scipy.io.wavfile
import math
import random
import matplotlib.pyplot as plt
import librosa.core as lc
out_prefix = 'librosa'
def plot(data, title, do_save=True):
plt.figure(figsize=(20,5))
plt.plot(data[:3*frame_length])
plt.ylim([-1, 1])
plt.title(title)
plt.grid()
if do_save: plt.savefig(title + '.png')
plt.show()
def reconstruct_from_stft(x, frame_length, frame_step):
name = 'stft'
stft = lc.stft(x, n_fft=frame_length, hop_length=frame_step)
istft = lc.istft(stft, frame_step)
return name, istft
def test(fn, input_data):
print('-'*80)
name, output_data = fn(input_data, frame_length, frame_step)
title = "{}.{}.{}.l{}.s{}".format(out_prefix, sample_rate, name, frame_length, frame_step)
print(title)
# output_data /= frame_length/frame_step/2 # tensorflow needs this to normalise amp
plot(output_data, title)
scipy.io.wavfile.write(title+'.wav', sample_rate, output_data)
def generate_data(duration_secs, sample_rate, num_sin, min_freq=10, max_freq=500, rnd_seed=0, max_val=0):
'''generate signal from multiple random sin waves'''
if rnd_seed>0: random.seed(rnd_seed)
data = np.zeros([duration_secs*sample_rate], np.float32)
for i in range(num_sin):
w = np.float32(np.sin(np.linspace(0, math.pi*2*random.randrange(min_freq, max_freq), num=duration_secs*sample_rate)))
data += random.random() * w
if max_val>0:
data *= max_val / np.max(np.abs(data))
return data
frame_length = 1024
sample_rate = 22050
input_data = generate_data(duration_secs=1, sample_rate=sample_rate, num_sin=1, rnd_seed=2, max_val=0.5)
title = "{}.orig".format(sample_rate)
plot(input_data, title)
scipy.io.wavfile.write(title+'.wav', sample_rate, input_data)
for frame_step in [256, 512, 768, 1024]:
test(reconstruct_from_stft, input_data)
print('done.')- Linux Ubuntu 16.04
- 从二进制v1.4.0-19-ga52c8d9,1.4.1安装Tensorflow
- Python2.7.14\ Anaconda自定义(64位)x(缺省值,2017年10月16日,17:29:19)。IPython 5.4.1
- Cuda 8.0版,V8.0.61版,cuDNN 6版
- Geforce GTX 970M,驱动程序版本: 384.111
(刚刚用TF1.5、Cuda9.0、cuDNN 7.0.5以及相同的结果进行了尝试)。
回答 2
Stack Overflow用户
发布于 2019-06-25 02:08:25
你应该使用tf.signal.inverse_stft_window_fn
window_fn=tf.signal.inverse_stft_window_fn(frame_step)
tf_istfts=tf.signal.inverse_stft(tf_stfts, frame_length=frame_length, frame_step=frame_step, fft_length=fft_length, window_fn=window_fn)}参见fn的更多信息
Stack Overflow用户
发布于 2018-01-29 21:30:57
具有50%重叠的Von Hann窗口的无限序列等于平坦的单位增益。如果有25%的重叠,则每单位时间的窗口数会增加一倍,从而使增益加倍。
重叠-加法快速卷积滤波通常是在没有重叠和(非矩形)窗口的情况下进行的,只需要足够的零填充,至少是滤波器函数的脉冲响应长度。任何重叠百分比不应包括任何添加的零填充长度。
https://stackoverflow.com/questions/48510229
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号