
时间序列距离度量
为了聚类一组时间序列,我正在寻找一种智能的距离度量。我试过一些众所周知的指标,但没有人适合我的情况。
让我们假设我的集群算法提取了这三个质心s1、s2、s3:
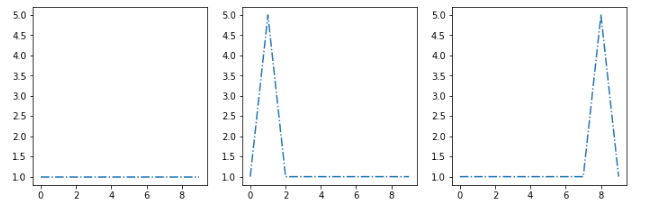
我想把这个新示例sx放在最相似的集群中:
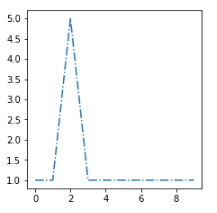
最相似的质心是第二个,所以我需要找到一个距离函数d,给我d(sx, s2) < d(sx, s1)和d(sx, s2) < d(sx, s3)。
编辑
这里的结果与度量余弦,欧几里德,明考斯基,动态类型翘曲。
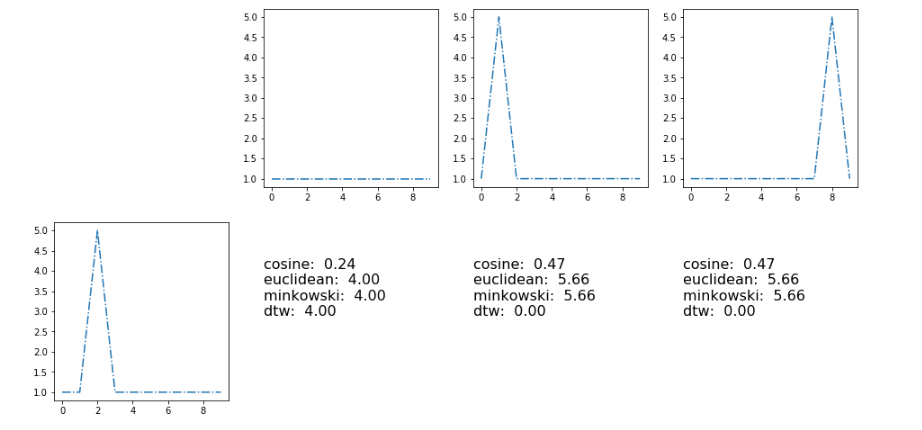
]3.
{kind=link}
编辑2
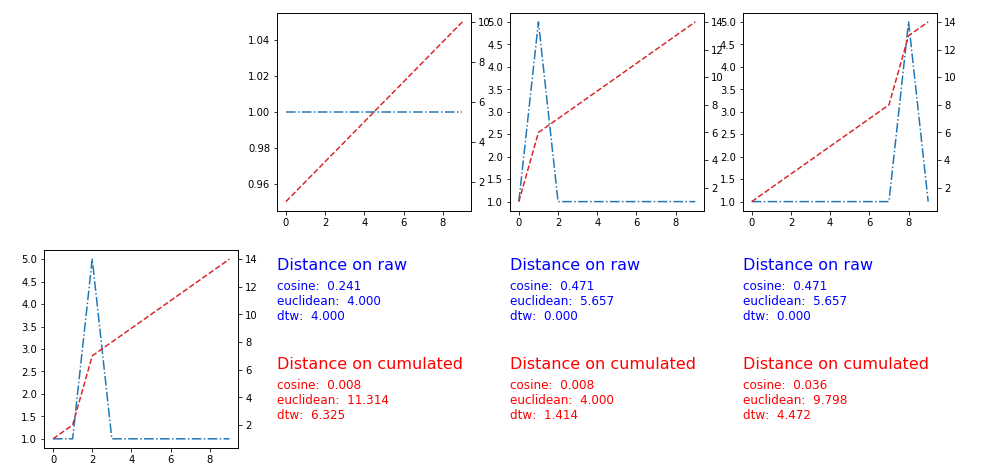
用户Pietro建议在累积版本的时间序列上应用距离--解决方案在这里工作,这里是图和度量:
回答 4
Stack Overflow用户
发布于 2018-01-30 14:27:07
问得好!在这些时间序列上使用R^n (欧几里德、曼哈顿或一般minkowski)的任何标准距离都无法达到您想要的结果,因为这些度量与R^n坐标的排列无关(而时间是严格有序的,这是您想要捕捉的现象)。
一个简单的技巧,可以做您要求的是使用累积版本的时间序列(随着时间的推移和值),然后应用一个标准的度量。使用曼哈顿的度量,你会得到两个时间序列之间的距离,它们的累积版本之间的面积。
Stack Overflow用户
发布于 2020-06-24 03:47:19
另一种方法是利用DTW算法计算两个时态序列之间的相似性。完全公开;我为此编写了一个称为trendypy的Python包,您可以通过pip (pip install trendypy)下载。这里是关于如何使用包的演示。你只是在计算不同组合的总最小距离来设置集群中心。
Stack Overflow用户
发布于 2018-01-29 10:20:38
如果使用标准的皮尔森相关系数?,那么您可以将新的点分配给系数最高的集群。
correlation = scipy.stats.pearsonr(<new time series>, <centroid>)
https://stackoverflow.com/questions/48497756
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号