
R中生产计划的计算
我正在用Excel复制一个生产计划,需要在R中计算生产量。
最终目标是在最少的天数内建立每月的需求。
Excel中的逻辑通过计算月中的生产日和生产间隔的模块来确定该天是否为构建日,然后查看迄今为止的累积产量,如果剩余需求大于最大生产量,则调度最大生产量,否则将调度剩余的需求量。
一个复杂的问题是,第一个生产订单应该安排在这个月的第一个生产日,而所有其他的构建日期都由一个来计算这个生产的第一天。
如果这个月的需求少于最大订购量,我想把整个月的需求安排在第一天,而不是最大订单数量。
下面是高亮显示栏中希望得到的结果的一个例子:
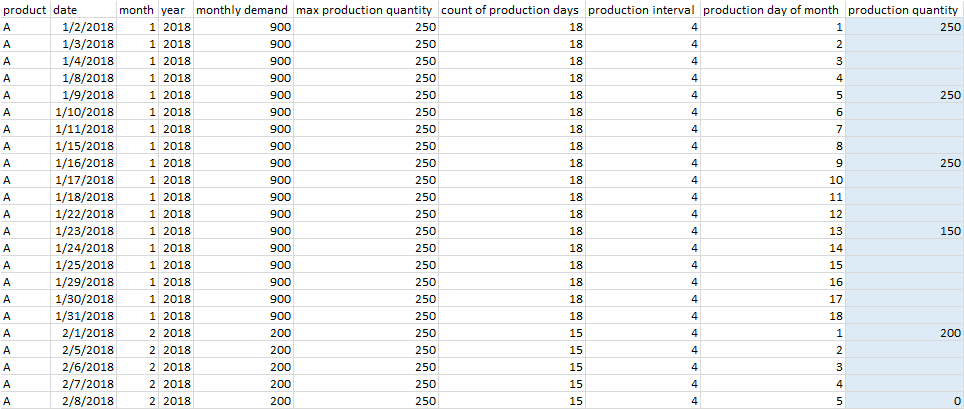
任何和所有的帮助都是非常感谢!
回答 1
Stack Overflow用户
发布于 2018-01-28 00:09:01
更新:很笨重,但我想出来了.
对像我这样的非数学家来说,一个关键的洞察力是,1 %的任何东西都能得到1,这让我可以写出下面的部分,在正确的日子里得到数量的位置。
production_revisions <- production_revisions %>%
arrange(SKU, date) %>%
mutate(revised_production_quantity = ifelse(production_day_of_month %% production_interval == 1,
ifelse(revised_quantity < max_order_quantity,
revised_quantity,
max_order_quantity),
0))但是它在月底的时候会多出一天的时间,所以我计算了那个月的累计生产量。
production_revisions <- production_revisions %>% group_by(SKU, year, month) %>% arrange(SKU, date) %>% mutate(cumulative_production_quantity = cumsum(revised_production_quantity))然后,如果我们已经构建了足够满足需求的版本,...and就会使用这个部分来摆脱最后的构建。我还对其进行了调整,以满足需求,如果剩余的数量少于最大订单量的话,就可以建造所需的。
production_revisions <- production_revisions %>% mutate(revised_production_quantity = ifelse(cumulative_production_quantity > revised_quantity,
ifelse(revised_quantity - lag(cumulative_production_quantity, 1) > 0,
revised_quantity - lag(cumulative_production_quantity, 1),
0),
revised_production_quantity))最后,...and重新计算了累计生产量,以确保生产完全符合需求(在一个完美的世界中)。
production_revisions <- production_revisions %>% group_by(SKU, year, month) %>% arrange(SKU, date) %>% mutate(cumulative_production_quantity = cumsum(revised_production_quantity))https://stackoverflow.com/questions/48472561
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号