
OOM in tez/hive
[经过几次回答和评论后,我根据这里获得的知识提出了一个新的问题:tuple ]
我的查询中有一个始终失败,错误是:
ERROR : Status: Failed
ERROR : Vertex failed, vertexName=Map 1, vertexId=vertex_1516602562532_3606_2_03, diagnostics=[Task failed, taskId=task_1516602562532_3606_2_03_000001, diagnostics=[TaskAttempt 0 failed, info=[Container container_e113_1516602562532_3606_01_000008 finished with diagnostics set to [Container failed, exitCode=255. Exception from container-launch.
Container id: container_e113_1516602562532_3606_01_000008
Exit code: 255
Stack trace: ExitCodeException exitCode=255:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:933)
at org.apache.hadoop.util.Shell.run(Shell.java:844)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:1123)
at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:237)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:317)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:83)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Container exited with a non-zero exit code 255
]], TaskAttempt 1 failed, info=[Error: Failure while running task:java.lang.RuntimeException: java.lang.OutOfMemoryError: Java heap space
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:173)这里的关键字似乎是java.lang.OutOfMemoryError: Java heap space。
我环顾四周,但我认为我从Tez所理解的东西都帮不了我:
- yarn-site/yarn.nodemanager.resource.memory-mb被放大了,=>,我使用了我能用的所有内存
- yarn-site/yarn.scheduler.maximum-allocation-mb:与yarn.nodemarager.resources.mb mb相同
- yarn-site/yarn.scheduler.minimum-allocation-mb = 1024
- 单元-站点/hive.tez.cuer.size= 4096 (yarn.调度器的倍数。最小-分配-mb)
我的查询有4个映射器,3个非常快,第4个每次都会死。下面是查询的Tez图形视图:
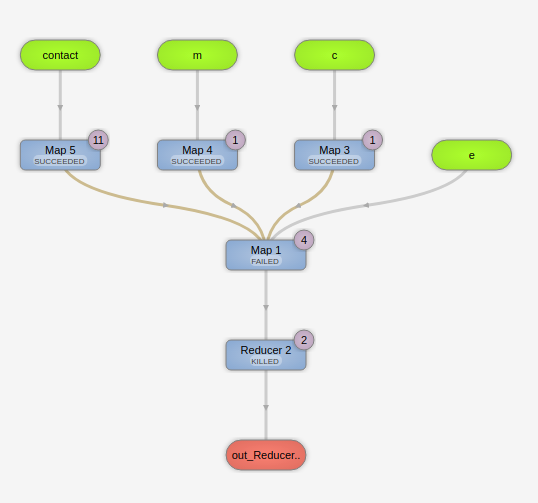
从这张图片中:
- 表触点有150米行,283 is的ORC压缩数据(有一个大的json字段,横向视图)
- 表m有1M行,20 m的ORC压缩数据。
- 表c有2k行,< 1MB ORC压缩
- 表e有800 k行,7GB的ORC压缩。
- E与所有其他表一起使用
E和contact被分区,在WHERE子句中只选择一个分区。
因此,我试图增加地图的数量:
- 最大大小:默认情况下为650 by,即使我将其降低到- tez.grouping.min-size(16 By),也没有什么区别。
- 分裂计数甚至增加到1000也没有什么区别
- 默认情况下,拆分波1.7,甚至增加到5也没有区别。
如果是相关的,下面是一些其他内存设置:
- Min= 1024 (Min容器大小)
- min = 2048 (2 *min容器大小)
- mapred-site/mapduce.map.java.opts= 819 (0.8 * min容器大小)
- mapred-site/maporee.Reduce.java.opts= 1638 (0.8 * mapreduce.reduce.memory.mb)
- 地图-站点/yarn.app.mapReduce.am.Resoure.mb= 2048 (2 * min容器大小)
- mapred-site/yarn.app.mapreduce.am.command-opts = 1638 (0.8 * yarn.app.mapreduce.am.resource.mb)
- min = 409 (0.4 *min容器大小)
我的理解是,tez可以在许多负载中分担工作,因此需要很长时间,但最终完成。我错了吗,还是我还没有找到呢?
上下文: hdp2.6,具有32 on的8个数据阳极,使用基于json直线运行的块状横向视图进行查询。
回答 2
Stack Overflow用户
发布于 2018-01-23 16:56:13
这一问题显然是由于数据失真造成的。我将再次建议您将distributed添加到您从源中选择查询,以便还原器具有均匀分布的数据。在下面的示例中,COL3是分布更均匀的数据,如ID列示例
ORIGINAL QUERY : insert overwrite table X AS SELECT COL1,COL2,COL3 from Y
NEW QUERY : insert overwrite table X AS SELECT COL1,COL2,COL3 from Y distribute by COL3Stack Overflow用户
发布于 2019-08-26 16:12:57
我也有同样的问题,增加所有的内存参数都没有帮助。
然后我转到MR,得到了下面的错误。
Failed with exception Number of dynamic partitions created is 2795, which is more than 1000.设置了更高的值后,我返回到tez,并解决了这个问题。
https://stackoverflow.com/questions/48403972
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号