
glht()和lsmeans()在lmer()模型中找不到对比
我有以下情况:
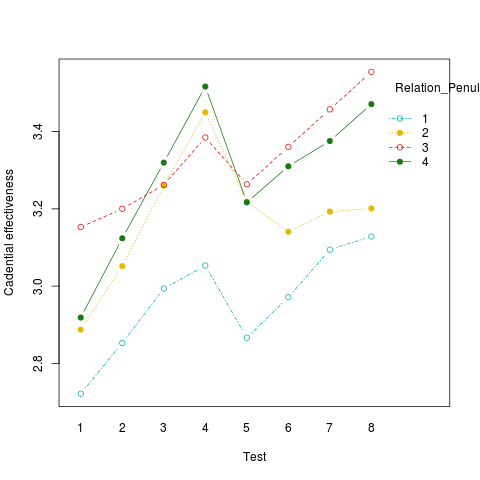
我的固定效应模型发现了Relation_PenultimateLast在被称为“作曲家”的参与者群体中的主要效应。因此,我想找出Relation_PenultimateLast的水平在统计上与其他级别不同。
f.e.model.composers = lmer(Score ~ Relation_PenultimateLast + (1|TrajectoryType) + (1|StimulusType) + (1|Relation_FirstLast) + (1|LastPosition), data=datasheet.complete.composers)摘要(f.e.model.composers)
Random effects:
Groups Name Variance Std.Dev.
TrajectoryType (Intercept) 0.005457 0.07387
LastPosition (Intercept) 0.036705 0.19159
Relation_FirstLast (Intercept) 0.004298 0.06556
StimulusType (Intercept) 0.019197 0.13855
Residual 1.318116 1.14809
Number of obs: 2200, groups:
TrajectoryType, 25; LastPosition, 8; Relation_FirstLast, 4; StimulusType, 4
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 2.90933 0.12476 14.84800 23.320 4.15e-13 ***
Relation_PenultimateLast 0.09987 0.02493 22.43100 4.006 0.000577 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1我必须对我的lmer()模型做一个Tukey比较。现在,我找到了两种比较Relation_PenultimateLast级别的方法(我在这里发现了它们:https://stats.stackexchange.com/questions/237512/how-to-perform-post-hoc-test-on-lmer-model):
summary(glht(f.e.model.composers, linfct = mcp(Relation_PenultimateLast = "Tukey")), test = adjusted("holm"))和
lsmeans(f.e.model.composers, list(pairwise ~ Relation_PenultimateLast), adjust = "holm")这些都不管用。前几份报告:
Variable(s) ‘Relation_PenultimateLast’ of class ‘integer’ is/are not contained as a factor in ‘model’后者:
Relation_PenultimateLast lsmean SE df lower.CL upper.CL
2.6 3.168989 0.1063552 8.5 2.926218 3.41176
Degrees-of-freedom method: satterthwaite
Confidence level used: 0.95
$` of contrast`
contrast estimate SE df z.ratio p.value
(nothing) nonEst NA NA NA NA有人能帮我弄明白为什么我会有这个结果吗?
回答 1
Stack Overflow用户
发布于 2018-01-13 18:59:34
首先,重要的是要认识到,你已经安装的模型是不合适的。它使用Relation_PenultimateLast作为数值预测器;因此,它适合于其值1、2、3和4的线性趋势,而不是作为一个因子对该值的每个级别进行单独的估计。我还想知道,考虑到您显示的图,为什么Test不在模型中;它看起来应该是(同样是作为一个因素,而不是一个数字预测器)。我建议您得到一些统计咨询帮助,以检查您是否在使用适当的模型在您的研究。也许你可以给一个统计学研究生一些实际应用的基础--一个双赢的命题。
要将Relation_PenultimateLast建模为一个因素,一种方法是在模型公式中用factor(Relation_PenultimateLast)替换它。这将适用于lsmeans(),但不适用于glht()。更好的方法可能是在dataset中更改它:
datasheet.complete.composers = transform(datasheet.complete.composers,
Relation_PenultimateLast = factor(Relation_PenultimateLast))
f.e.model.composers = lmer(...) ### (as before, assuming Test isn't needed)(顺便说一句,你一定是个比我更好的打字员;我会用更短的名字,虽然我会用信息丰富的名字来鼓掌。)
(注:f.e.model.composers是否被认为是一个固定效应模型?这不是一种,而是一种混合模式。再一次,顾问.)
lsmeans包注定要被废弃,所以我建议您使用它的延续,emmeans表示包:
library(emmeans)
emmeans(f.e.model.composers, pairwise ~ Relation_PenultimateLast)我建议对这个应用程序使用默认的"tukey"调整而不是Holm。
如果Test确实应该在模型中,那么看起来您需要包含交互;所以它应该是这样的:
model.composers = lmer(Score ~ Relation_PenultimateLast * factor(Test) + ...)
### A plot like the one shown, but based on the model predictions:
emmip(model.composers, Relation_PenultimateLast ~ Test)
### Estimates and comparisons of Relation_PenultimateLast for each Test:
emmeans(model.composers, pairwise ~ Relation_PenultimateLast | Test)https://stackoverflow.com/questions/48241097
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号