
基于新客户号码的累积和重置
基于新客户号码的累积和重置
提问于 2018-01-11 19:57:32
我有一个像这样的数据集。
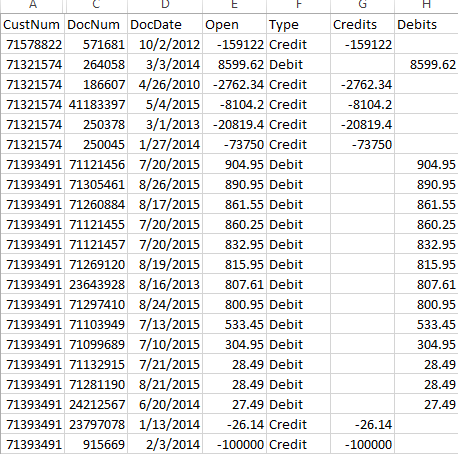
我想做的是:
- 每一个客户号码,金额信贷金额,金额借方金额(最老至最新),直到借方累计=信贷金额*-1
- 信用证可适用于部分发票。
- 返回一份文件编号(和金额)列表,以便为每个客户应用信贷。
df['debcum_sum'] = df.groupby(['CustNum'])['Debits'].apply(lambda x: x.cumsum())
我本来打算为累积和添加一个列,但我想尝试并将其作为一个for循环。有什么建议吗?
回答 1
Stack Overflow用户
发布于 2018-01-11 20:16:06
使用groupby + cumsum的组合,然后使用pd.Series.where/mask根据Credit列隐藏值-
v = df.groupby(['CustNum'])['Debits'].cumsum()
df['debit_cumsum'] = v.where(v >= df['Credit'] * -1)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/48214911
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号