
R能读取html编码的表情符号吗?
问题
我的问题解释如下:
如何使用R读取包含HTML代码(如��**?** )的字符串
我想:
(1)在解析的字符串或中表示符号(例如,作为unicode符号:)
(2)将其转换为等效文本(":hugging face:")
背景
我有一个XML文本信息数据集(来自安卓/iOS应用程序信号),我正在为一个文本挖掘项目将其读入R。数据如下所示,每个文本消息都表示在一个sms节点中:
<?xml version="1.0" encoding="UTF-8" standalone="yes" ?>
<!-- File Created By Signal -->
<smses count="1">
<sms protocol="0" address="+15555555555" contact_name="Jane Doe" date="1483256850399" readable_date="Sat, 31 Dec 2016 23:47:30 PST" type="1" subject="null" body="Hug emoji: ��" toa="null" sc_toa="null" service_center="null" read="1" status="-1" locked="0" />
</smses>问题
当我使用xml2函数时,我正在使用xml2::read_xml包读取数据,但是,我得到了以下错误消息:
Error in doc_parse_raw(x, encoding = encoding, base_url = base_url, as_html = as_html, :
xmlParseCharRef: invalid xmlChar value 55358正如我所理解的那样,它表明该表情符号字符不被识别为有效的XML。
使用xml2::read_html函数确实有效,但删除了表情符号字符。这方面的一个小例子是:
example_text <- "Hugging emoji: ��"
xml2::xml_text(xml2::read_html(paste0("<x>", example_text, "</x>")))(输出:[1] "Hugging emoji: ")
这个字符是有效的HTML ��实际上将它在搜索栏中转换为“拥抱脸”表情,并显示与该表情符号相关的结果。
我发现的其他与这个问题相关的信息
我一直在搜索堆栈溢出,没有发现任何有关这个特定问题的问题。我还没有找到一个直接给出它们所代表的表情符号旁边的HTML代码的表,因此在解析数据集之前,无法在一个大循环中(尽管效率很低)将这些HTML代码转换成它们的文本对等代码;例如,这份清单和它的底层数据集似乎都没有包含字符串55358。
回答 4
Stack Overflow用户
发布于 2018-01-08 00:59:17
tl;dr:表情符号不是有效的实体;UTF-16数字被用来构建它们而不是Unicode代码点。我在答案的底部描述了一个算法来转换它们,使它们成为有效的XML。
识别问题
R绝对处理表情符号:
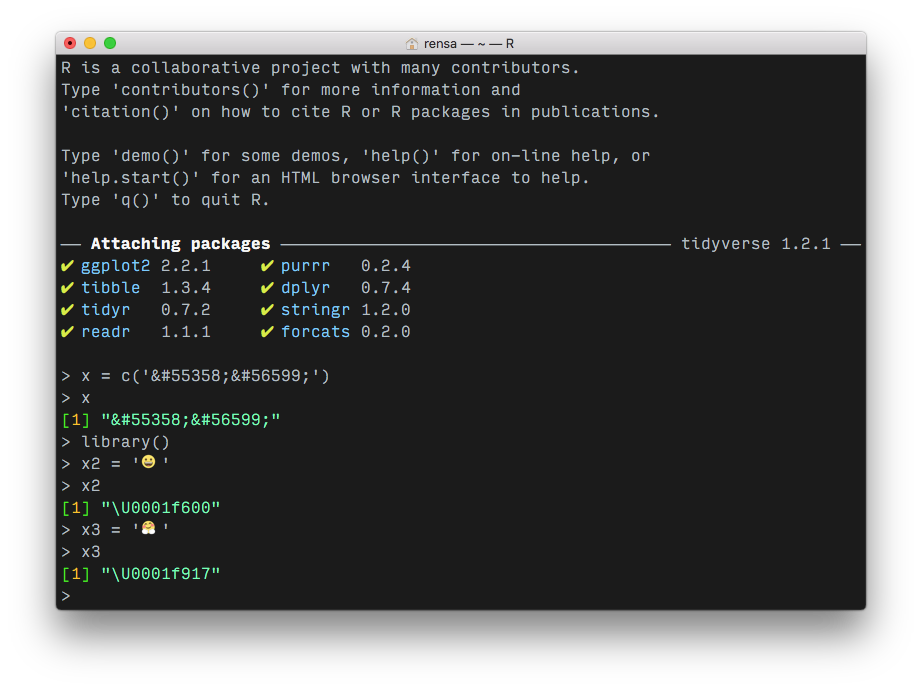
事实上,在R中有一些用于处理表情符号的包--例如,[医]表情和埃莫包都允许您基于style关键字检索表情符号。这只是一个问题,让您的源字符通过HTML转义格式,以便您可以转换他们。
xml2::read_xml似乎可以很好地处理其他的HTML实体,比如符号和双引号。我查看了这就是答案实体是否存在任何特定于XML的约束,看起来它们似乎在存储表情符号。所以我试着把你的reprex中的表情符号改为那个答案中的表情符号:
body="Hug emoji: 😀😃"果然,它们被保存下来了(尽管它们显然不再是拥抱表情符号了):
> test8 = read_html('Desktop/test.xml')
> test8 %>% xml_child() %>% xml_child() %>% xml_child() %>% xml_attr('body')
[1] "Hug emoji: \U0001f600\U0001f603"我在此页上查找了拥抱表情符号,而十进制HTML实体中没有��。看起来,该表情符号的UTF-16小数点代码已被包装在&#和;中。
总之,我认为答案是你的表情符号实际上不是有效的实体。如果无法控制源,则可能需要对这些错误进行一些预处理。。
那么,为什么浏览器要正确地转换它们呢?我想知道浏览器在这些东西上是否更灵活一些,并猜测这些代码可能是什么。不过,我只是在推测。
将UTF-16转换为Unicode代码点
经过进一步研究,看起来有效的表情符号HTML实体使用Unicode代码点(十进制,如果是&#...;,或者十六进制,如果是&#x...;)。https://www.smashingmagazine.com/2016/11/character-sets-encoding-emoji/ (这个链接解释了很多关于表情符号和其他字符是如何被编码的,BTW!读得好。)
因此,我们需要将源数据中使用的UTF-16代码转换为Unicode代码点。提到这篇维基百科关于UTF-16的文章,我已经验证了它是如何完成的。每个Unicode代码点(我们的目标)是一个20位数字,或五个十六进制数字。当从Unicode到UTF-16时,你把它分成两个10位数字(中间的十六进制数字被切成两半,每个块有两个比特),对它们做一些数学运算,得到结果)。
回到过去,就像你想要的那样,它是这样完成的:
- 您的十进制UTF-16数字(目前在两个单独的块中)是
55358 56599。 - 将这些块转换为十六进制(单独)将给出
0x0d83e 0x0dd17 - 从第一个块减去
0xd800,从第二个块减去0xdc00,给出0x3e 0x117 - 将它们转换为二进制,将它们填充到10位,并将它们连接起来,这是
0b0000 1111 1001 0001 0111 - 然后我们将其转换回十六进制,即
0x0f917。 - 最后,我们添加
0x10000,给出0x1f917 - 因此,我们的(十六进制)
🤗**.实体是或者,以小数表示,**🤗
因此,要预处理这个数据集,您需要提取现有的数字,使用上面的算法,然后将结果放回(使用一个&#...;,而不是两个)。
在R中显示表情符号
据我所知,在R控制台中打印表情符号是没有解决方案的:它们总是以"U0001f600" (或者其他什么)的形式出现。不过,我上面描述的包可以帮助您在某些情况下绘制表情符号(我希望扩展格旗,以便在某一时刻显示任意的全色表情符号)。他们也可以帮助你搜索表情符号来获取他们的代码,但是他们不能获得给定代码AFAIK的名字。但是,如果您已经将表情符号代码提取到列中,则可以尝试将emojilib导入到R中,并使用数据框架进行连接,以获得英文名称。
Stack Overflow用户
发布于 2018-12-10 18:02:49
JavaScript解决方案
我遇到了这个完全相同的问题,但是需要JavaScript中的解决方案,而不是R.使用伦萨的上述评论 (非常有用!),我创建了下面的代码来解决这个问题,我只是想分享它,以防其他人像我一样在这个线程中发生,但在JavaScript中需要它。
str.replace(/(&#\d+;){2}/g, function(match) {
match = match.replace(/&#/g,'').split(';');
var binFirst = (parseInt('0x' + parseInt(match[0]).toString(16)) - 0xd800).toString(2);
var binSecond = (parseInt('0x' + parseInt(match[1]).toString(16)) - 0xdc00).toString(2);
binFirst = '0000000000'.substr(binFirst.length) + binFirst;
binSecond = '0000000000'.substr(binSecond.length) + binSecond;
return '&#x' + (('0x' + (parseInt(binFirst + binSecond, 2).toString(16))) - (-0x10000)).toString(16) + ';';
});而且,这里有一个完整的代码片段,如果您想运行它的话:
var str = '������������'
str = str.replace(/(&#\d+;){2}/g, function(match) {
match = match.replace(/&#/g,'').split(';');
var binFirst = (parseInt('0x' + parseInt(match[0]).toString(16)) - 0xd800).toString(2);
var binSecond = (parseInt('0x' + parseInt(match[1]).toString(16)) - 0xdc00).toString(2);
binFirst = '0000000000'.substr(binFirst.length) + binFirst;
binSecond = '0000000000'.substr(binSecond.length) + binSecond;
return '&#x' + (('0x' + (parseInt(binFirst + binSecond, 2).toString(16))) - (-0x10000)).toString(16) + ';';
});
document.getElementById('result').innerHTML = str;
// ������������
// is turned into
// 😊😘😀😆😂😁
// which is rendered by the browser as the emojisOriginal:<br>������������<br><br>
Result:<br>
<div id='result'></div>
我的SMS XML解析器应用程序现在工作得很好,但是它在大量的XML文件上停止运行,所以,我正在考虑用PHP重写它。如果我这么做了,我也会发布这段代码。
Stack Overflow用户
发布于 2018-01-08 16:45:37
我在R中实现了算法由rensa上文所述,并在这里共享它。--我很高兴在 CC0奉献下发布下面的代码片段(即,将该实现放到公共域中以进行免费重用)。
这是rensa算法的一个快速而不完善的实现,但是它是有效的!
utf16_double_dec_code_to_utf8 <- function(utf16_decimal_code){
string_elements <- str_match_all(utf16_decimal_code, "&#(.*?);")[[1]][,2]
string3a <- string_elements[1]
string3b <- string_elements[2]
string4a <- sprintf("0x0%x", as.numeric(string3a))
string4b <- sprintf("0x0%x", as.numeric(string3b))
string5a <- paste0(
# "0x",
as.hexmode(string4a) - 0xd800
)
string5b <- paste0(
# "0x",
as.hexmode(string4b) - 0xdc00
)
string6 <- paste0(
stringi::stri_pad(
paste0(BMS::hex2bin(string5a), collapse = ""),
10,
pad = "0"
) %>%
stringr::str_trunc(10, side = "left", ellipsis = ""),
stringi::stri_pad(
paste0(BMS::hex2bin(string5b), collapse = ""),
10,
pad = "0"
) %>%
stringr::str_trunc(10, side = "left", ellipsis = "")
)
string7 <- BMS::bin2hex(as.numeric(strsplit(string6, split = "")[[1]]))
string8 <- as.hexmode(string7) + 0x10000
unicode_pattern <- string8
unicode_pattern
}
make_unicode_entity <- function(x) {
paste0("\\U000", utf16_double_dec_code_to_utf8(x))
}
make_html_entity <- function(x) {
paste0("&#x", utf16_double_dec_code_to_utf8(x), ";")
}
# An example string, using the "hug" emoji:
example_string <- "test �� test"
output_string <- stringr::str_replace_all(
example_string,
"(&#[0-9]*?;){2}", # Find all two-character "&#...;&#...;" codes.
make_unicode_entity
# make_html_entity
)
cat(output_string)
# To print Unicode string (doesn't display in R console, but can be copied and
# pasted elsewhere:
# (This assumes you've used 'make_unicode_entity' above in the str_replace_all
# call):
stringi::stri_unescape_unicode(output_string)https://stackoverflow.com/questions/48142634
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号