
如何用DSE图处理超级节点
我有一个简单的顶点“url”
schema.vertexLabel('url').partitionKey('url_fingerprint', 'prop1').properties("url_complete").ifNotExists().create()还有一个叫做“链接”的edgeLabel,它将一个url连接到另一个url。
schema.edgeLabel('links').properties("prop1", 'prop2').connection('url', 'url').ifNotExists().create()有可能一个网址有数以百万计的传入链接(例如,来自所有子页的ebay.com首页)。
但这似乎会导致真正的大分区/和崩溃的dse,因为广泛的分区(来自Opscenter宽分区报告):graphdbname.url_e (2284mb)
我怎样才能避免这种情况?如何处理这个“超级节点”?我已经为标签找到了一个“分区”命令(关于这个1的文章),但是这个命令是不推荐的,它将在DSE 6.0中删除/发布说明中唯一的提示就是用另一种方式对数据建模--但我不知道在这种情况下如何做到这一点。
我对每一个提示都很高兴。谢谢!
回答 1
Stack Overflow用户
发布于 2018-01-10 17:48:07
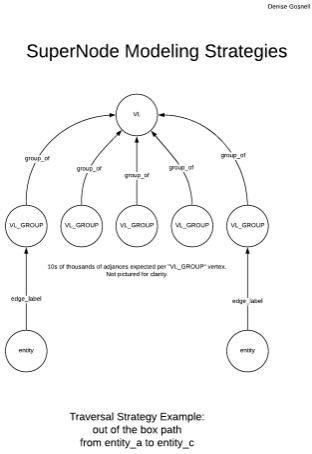
当前的建议是使用在C*世界中驱动数据模型设计的“桶”概念,并通过创建一个表示链接组的中间顶点将其应用于图形。
2个顶点标号
- URL
- URL_Group /分区密钥((url,group))…即具有两个分区关键组件的复合主键
2边
- URL -> URL_Group
- URL_Group (替换现有的自参考边) URL_Group <->URL_Group每个组不超过100 than url_fingerprints。在每个100 each边存在之后创建一个新组。
此解决方案需要簿记以确定何时需要新组。这可以通过一个简单的C*表来完成,这样可以快速、容易地检索。
CREATE TABLE lookup url_fingerprint, group, count counter PRIMARY KEY (url_fingerprint, group) 这应保持DESC顺序,如果DESC顺序未被保留,则可能需要按语句添加订单。
在写入图表之前,需要阅读表才能找到最新的组。
SELECT url_fingerprint, group, count from lookup LIMIT(1) 如果计数器>100 group,则创建一个新组(增量组+1)。在将新行写入图形期间或之后,需要增加计数器。
遍历将需要类似于:
g.V().has(some url).out(URL).out(URL_Group).in(URL)在概念上,您将遍历像URL -> URL_Group->URL_Group<-URL这样的关系。
这种类型的遍历的可视化模型如下图所示
https://stackoverflow.com/questions/48092495
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号