
如何从丢失的比特中恢复?
来自维基百科的报价
如果字节流易损坏,则某些编码比其他编码恢复得更好。在这方面,UTF-8和UTF-EBCDIC是最好的,因为它们总是可以在下一个代码点开始时重新同步; ..。 UTF-16和UTF-32将通过在下一个好的代码点上重新同步来处理损坏的(更改的)字节,但是丢失或伪造字节(八进制)的奇数将混淆所有以下文本。
我不太明白为什么当腐败发生时,UTF-8比UTF-16更有效。“奇数”是什么意思?这是否意味着1在0101010111101(字节流)中?
此外,当不出现奇数丢失或伪字节(八进制)时,我是否可以说UTF-16的恢复性能与UTF-8一样好?
在使用UTF-8或UTF-16时,有人能给出系统如何从误码中恢复吗?
回答 2
Stack Overflow用户
发布于 2018-01-11 19:33:35
这个文档引用是指在丢失了一些代码点之后恢复流,而不是纠正在传输过程中出现错误的字符。
它的意思很简单:如果在utf-8流中遗漏了一个或多个字节,只要下一个字节是新代码点(通常是字符)的开始,您就可以从那里恢复文本。
在utf-16中,所有字符都有两个字节长,如果您遗漏了一个字节,那么所有后续字节都会被错误地放置,如果没有更高级别的校正,那么对于该流,没有其他代码点是正确的。
为了可视化这一点,在Python3交互模式中我们可以这样做:
In [19]: a = "Resumé for mr. Fernando"
In [20]: b = a.encode("utf-8"); b = b[:3] + b[4:]
In [21]: print (b.decode("utf-8"))
Resmé for mr. Fernando
In [22]: b = a.encode("utf-16"); b = b[:10] + b[11:]
In [23]: print (b.decode("utf-16", errors="replace"))
Resu 昀漀爀 洀爀⸀ 䘀攀爀渀愀渀搀漀�( Python中用于那些不熟悉的地方的切片表示法意味着[<begin (inclusive)>: <end (exclusive)>]作为位置。空的任何参数都被假定为切片序列的开头或结尾)
为什么“奇数”在这一点上应该是显而易见的:如果您遗漏了偶数字节,解码系统仍将尝试在字符边界处解码-如果使用奇数,所有字符边界都将是不正确的。
Stack Overflow用户
发布于 2018-02-02 09:38:33
魔法隐藏在编码的结构中。在UTF-8结构中,UTF-8编码字节的所有起始字节都不能被不是起始字节的字节错误地替换。然而,在UTF-16中,情况并非如此。
UTF-8结构
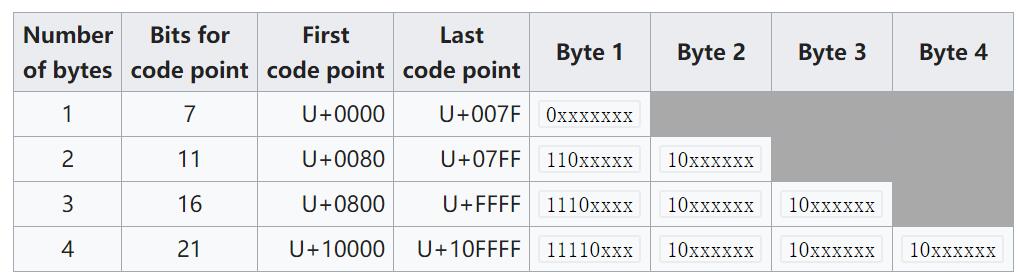
让我们模拟接收UTF-8编码字节作为输入和输出代码点的神奇机器是如何工作的,当一个字节丢失在一个3字节长的UTF-8编码字节中时。
比如说,来自两个字符一二的UTF-8编码字节是e4b880(一)和e4ba8c(二).现在机器读取e4,即11100100,它知道下面的代码点是一个3字节长的代码点。不幸的是,错过了下面的字节b8。接下来,阅读80。然后,读取二的第一个字节,即e4。然而,e4不适合这个规则:当涉及到3字节长的代码点时,字节3需要根据上面的表以10开头。现在机器知道一些字节丢失了,代码点被破坏了。它将试图环顾四周,找到正确的解码起点。显然,下一个字节ba不是一个好的开始,因为它不适合上表中的任何一个字节1。然后,它将回顾,发现前一个字节e4是一个很好的开始字节解码。
在UTF-16中,一个字节可能被错误地替换为不是起始字节的字节,因为UTF-16无法判断它是否是起始字节。
https://stackoverflow.com/questions/48088226
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号