
Intel TBB流程图开销
这里是我尝试测试英特尔TBB流图的性能。下面是设置:
- 一个广播节点向
N后续节点发送continue_msg(abroadcast_node<continue_msg>) - 每个后续节点执行一次计算,耗时
t秒。 - 串行执行时的总计算时间是
Tserial = N * t。 - 如果使用所有核,理想的计算时间是
Tpar(ideal) = N * t / C,,其中C是核数。 - 加速比被定义为
Tpar(actual) / Tserial - 我在一台16核心PC上用gcc5测试了代码。
下面的结果显示了加速比与单个任务(即主体)处理时间的关系:
t = 100 microsecond , speed-up = 14
t = 10 microsecond , speed-up = 7
t = 1 microsecond , speed-up = 1与轻量级任务(其计算时间小于1微秒)一样,并行代码实际上比串行代码慢。
以下是我的问题:
( 1 )这些结果是否与Intel基准一致?
( 2 )当每一个任务花费不到1微秒时,它有一个比流图更好的范例吗?
回答 2
Stack Overflow用户
发布于 2018-01-03 17:44:44
并行的开销
你的成本模型错了。
理想的并行计算时间是:
Tpar(ideal) = N * t / C + Pstart + Pend其中,Pstart是启动并行性所需的时间,而Pend是完成它所需的时间。对于Pstart来说,在几十毫秒左右的时间是很正常的。
我不确定您是否熟悉OpenMP (尽管知道这是件好事),但是,就我们的目的而言,它是一个在线程团队之间划分工作的线程模型。下图显示了与线程团队大小相关的一些命令的开销:
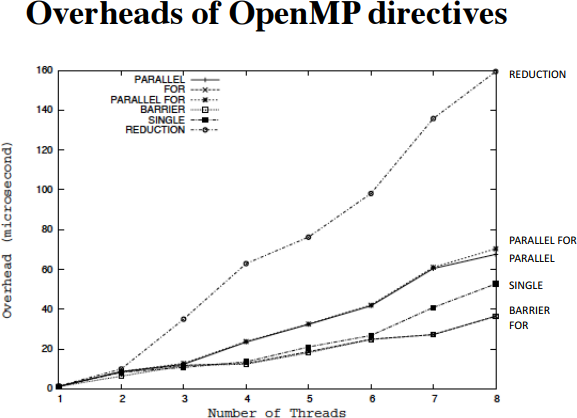
需要注意的是,运行并行性( parallel for行)可能很昂贵,并且随着线程数的增加而增加。结束并行( barrier行)也有类似的代价。
事实上,如果您查看TBB的教程,第3.2.2节(“自动链接”)说:
注意:通常情况下,一个循环需要花费至少100万个时钟周期才能提高parallel_for的性能。例如,在一个2 GHz处理器上花费至少500微秒的循环可能会从parallel_for中受益。
实现更高速度的
加快代码速度的最好方法是,只有在有大量的操作和/或调整执行工作的线程数量的情况下,才能并行执行这些操作,以便每个线程都有大量的工作要做。在TBB中,您可以实现类似的行为:
#include <tbb/parallel_for.h>
// . . .
if(work_size>1000)
tbb::serial::parallel_for( . . . );
else
tbb::parallel_for( . . . );
// . . . 在这里,您希望将1000调整到足够高的数字,从而开始看到并行性带来的好处。
您还可以减少线程的数量,因为这在一定程度上减少了开销:
tbb::task_scheduler_init init(nthread);TBB还执行动态负载平衡(请参阅这里)。如果您期望循环迭代/任务具有广泛的运行时分布,但如果预期的运行时相同,则表示不必要的开销。我不确定TBB是否有静态调度,但可能值得研究。
如果人们最终在这里没有对TBB做出强有力的承诺,那么在OpenMP中,您可以做如下的事情:
#pragma omp parallel for if(work_size>1000) num_threads(4) schedule(static)Stack Overflow用户
发布于 2018-01-04 19:25:15
@Richard有正确的答案( TBB教程讨论了调度开销摊销的概念),通常我会把它作为评论,但有一件事我想补充一下。
TBB对任务使用“贪婪调度”。如果存在由先前任务的执行所创建的任务(从技术上讲,如果任务返回一个任务指针),则该任务是在线程上运行的下一个任务。这有两个好处:
- 最后一个任务可能已经加载或生成了下一个任务使用的数据,这有助于数据局部性。
- 我们跳过了选择要运行的下一个任务的过程(它是否在本地线程的队列中,是否可以从另一个线程中窃取)。这大大减少了调度开销。
tbb::flow_graph使用相同的想法;如果一个节点有一个或多个接班人,则在其执行完成时,会选择其中一个接班人作为下一个运行。
这样做的缺点是,如果您想改变这种行为(以“广度优先”而不是“深度优先”顺序执行节点),您必须跳过一些循环。它还将使您在调度开销和丢失本地资源方面付出代价。
https://stackoverflow.com/questions/48081943
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号