
事件驱动体系结构的构建块
在数据的流水线处理中,我们使用,
- 发电机(S)
- 中间处理器引擎(聚合操作)
- 终结者
例如,使用python生成器和协同例程,

&
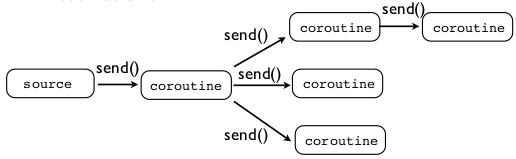
&
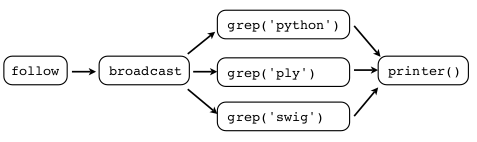
Generator(s)-IntermediateProcessor(s)-Terminator(s)是否可以被视为事件驱动体系结构的构建块
回答 1
Stack Overflow用户
发布于 2018-01-03 09:51:17
那得看情况。
您的事件驱动架构所缺少的是事件。只要您的所有模块(生成器、终止器等)都可以接收和发送事件到它们想要的收件人,它就是一个事件驱动的体系结构。
偶尔,您会得到非常类似于事件驱动的体系结构,如管道,但传递的信息不被视为事件。例如,Java流传递的是数据,而不是事件。
现在,如果一个人决定将他们所有的数据元素称为“事件”,那么人们可能会认为它是由事件驱动的;但是,这个论点很快就会消失,因为事件通常有一个结构(或至少一个类型)不会在流的处理阶段发生变异。
带着这个小小的想法。是的,所有处理事件的方法都起源于源(生成器),遍历可能完全消耗事件的处理节点(终止器),或者通过可能生成其他事件的节点(中间处理器)。
但是,这种分类是您的,而不是事件处理系统的要求。例如,我可以有多个这样的角色中的节点。单个节点可能终止已经处理过其终止的员工的“employee -退出”事件,同时执行一些工作并将"removeFromPayroll“事件转发给未处理其终止的员工。同样,安排每日电子邮件提醒的事件也不是完全的“生成器”,而是包含了“生成器”的许多方面。
因此,您的分类是很好的,只要您意识到这是一个分类,您要添加到一个系统中,以帮助您组织它,而不是一组严格的“节点类型”,这是排他性的。
-例如
你要说的更好的例子是
(origin) -> follow_news_topic -> (story web spider) -> new_news_topic_article -> (archiver)在这里我们可以清楚地看到有两个事件"follow_news_topic“和"new_news_topic_article”
“事件导向”是对事件的关注。节点是广义元素,但它们不够一般,不足以完全适合您的3种分类中的一种。一个节点可能会将双任务(甚至是三重任务)拉到您的分类下。
https://stackoverflow.com/questions/48074348
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号