
MDP与强化学习& VI、PI和QLearning算法的收敛性比较
我使用python实现了VI (值迭代)、PI (策略迭代)和QLearning算法。在比较了结果之后,我注意到了一些事情。VI算法和PI算法收敛于相同的实用程序和策略。具有相同的参数,QLearning算法收敛于不同的实用程序,而策略与VI和PI算法相同。这是正常的吗?我读了很多关于MDP和RL的论文和书籍,但是找不到任何东西来说明VI-PI算法的实用程序是否应该收敛到与QLearning相同的实用程序。
下面是关于我的网格世界和结果的信息。
我的网格世界
{kind=link}
- => {s0,s1,.,s10}
- 动作=> { a0,a1,a2,a3},其中:a0= Up,a1 =右,a2 = Down,a3 =左
- 有四个终端状态,它们有+1,+1,-10,+10奖励。
- 初始状态为s6
- 一个动作的转移概率是P,而(1-p)/ 2是该动作的左边或右侧。(例如:如果P= 0.8,则当代理试图上升时,80%的机会代理将上升,10%的机会代理将向右移动,10%的代理将向左移动。)
结果
- VI算法和PI算法的结果分别为:报酬= -0.02,折扣因子= 0.8,概率= 0.8。
- VI在50次迭代后收敛,PI在3次迭代后收敛。
{kind=link}
- QLearning算法的结果为:奖励= -0.02,折扣因子= 0.8,学习率= 0.1,Epsilon (用于探索)= 0.1
- 结果在QLearning结果图像上的实用程序是每个状态的最大Q(s,a)对。
{kind=link}
此外,我还注意到,当QLearning执行100万次迭代时,与+10奖励终端相当远的状态具有相同的实用程序。Agent似乎并不关心它是否会从接近-10终端的路径上得到奖励,而agent则在VI和PI算法上关注它。是因为,在QLearning中,我们不知道环境的转换概率?
回答 1
Stack Overflow用户
发布于 2017-12-29 09:23:47
如果状态和动作空间是有限的,就像在您的问题中一样,Q-learning算法应该逐步收敛到最优效用(又名Q-函数),当过渡数接近无穷大时,在以下条件下:
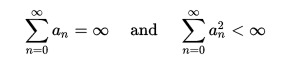
,
其中n是转换数,a是学习速率。这种情况需要随着学习的进展而更新您的学习速度。一个典型的选择可以是使用a_n = 1/n。然而,在实践中,学习进度计划可能需要根据问题进行一些调整。
另一方面,另一个收敛条件是无限地更新所有状态-动作对(在不对称意义上)。要做到这一点,只需将勘探率保持在零以上。
所以,在你的情况下,你需要降低学习率。
https://stackoverflow.com/questions/48011874
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号